入坑 LinkedList,i 了 i 了
上一篇入坑了ArrayList,小伙伴们反响不错,那这篇就继续入坑 LinkedList,它俩算是亲密无间的兄弟,相爱相杀的那种,不离不弃的那种,介绍了这个就必须介绍那个的那种。

明目张胆地告诉大家一个好消息,我写了一份 4 万多字的 Java 小白手册,小伙伴们可以在「 沉默王二 」公众号后台回复「 小白 」获取免费下载链接。觉得不错的话,请随手转发给身边需要的小伙伴,赠人玫瑰,手有余香哈。
最开始学习 Java 的时候,我还挺纳闷的,有了 ArrayList,干嘛还要 LinkedList 啊,都是 List,不是很多余吗?当时真的很傻很天真,不知道有没有同款小伙伴。搞不懂两者之间的区别,什么场景下该用 ArrayList,什么场景下该用 LinkedList,傻傻分不清楚。那么这篇文章,可以一脚把这种天真踹走了。
和数组一样,LinkedList 也是一种线性数据结构,但它不像数组一样在连续的位置上存储元素,而是通过引用相互链接。
LinkedList 中的每一个元素都可以称之为节点(Node),每一个节点都包含三个项目:其一是元素本身,其二是指向下一个元素的引用地址,其三是指向上一个元素的引用地址。
Node 是 LinkedList 类的一个私有的静态内部类,其源码如下所示:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
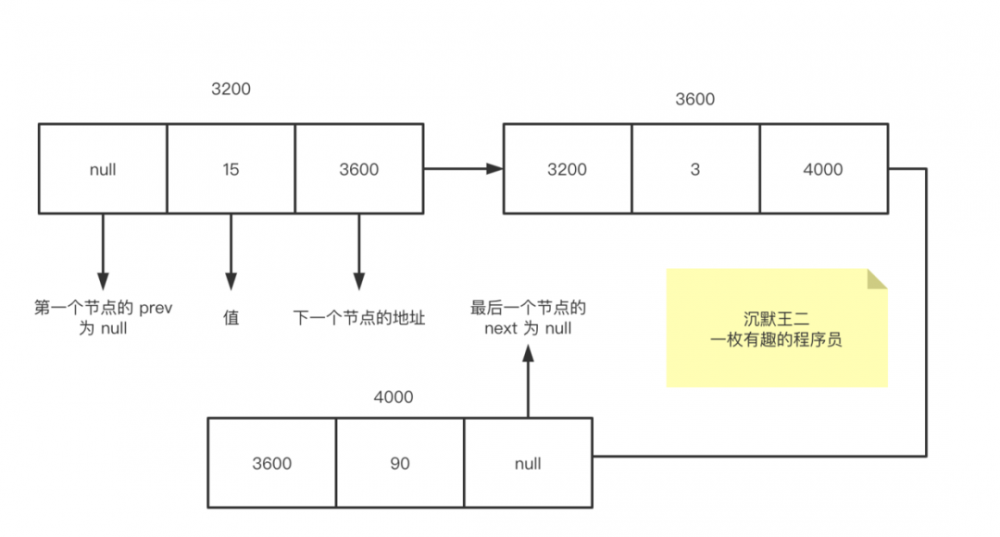
LinkedList 看起来就像下面这个样子:
-
第一个节点由于没有前一个节点,所以 prev 为 null;
-
最后一个节点由于没有后一个节点,所以 next 为 null;
-
这是一个双向链表,每一个节点都由三部分组成,前后节点和值。
那可能有些小伙伴就会和当初的我一样,好奇地问,“为什么要设计 LinkedList 呢?”如果能给 LinkedList 类的作者打个电话就好了,可惜没有他的联系方式。很遗憾,只能靠我来给大家解释一下了。
第一,数组的大小是固定的,即便是 ArrayList 可以自动扩容,但依然会有一定的限制:如果声明的大小不足,则需要扩容;如果声明的大小远远超出了实际的元素个数,又会造成内存的浪费。尽管扩容的算法已经非常优雅,尽管内存已经绰绰有余。
第二,数组的元素需要连续的内存位置来存储其值。这就是 ArrayList 进行删除或者插入元素的时候成本很高的真正原因,因为我们必须移动某些元素为新的元素留出空间,比如说:
现在有一个数组,10、12、15、20、4、5、100,如果需要在 12 的位置上插入一个值为 99 的元素,就必须得把 12 以后的元素往后移动,为 99 这个元素腾出位置。
删除是同样的道理,删除之后的所有元素都必须往前移动一次。
LinkedList 就摆脱了这种限制:
第一,LinkedList 允许内存进行动态分配,这就意味着内存分配是由编译器在运行时完成的,我们无需在 LinkedList 声明的时候指定大小。
第二,LinkedList 不需要在连续的位置上存储元素,因为节点可以通过引用指定下一个节点或者前一个节点。也就是说,LinkedList 在插入和删除元素的时候代价很低,因为不需要移动其他元素,只需要更新前一个节点和后一个节点的引用地址即可。
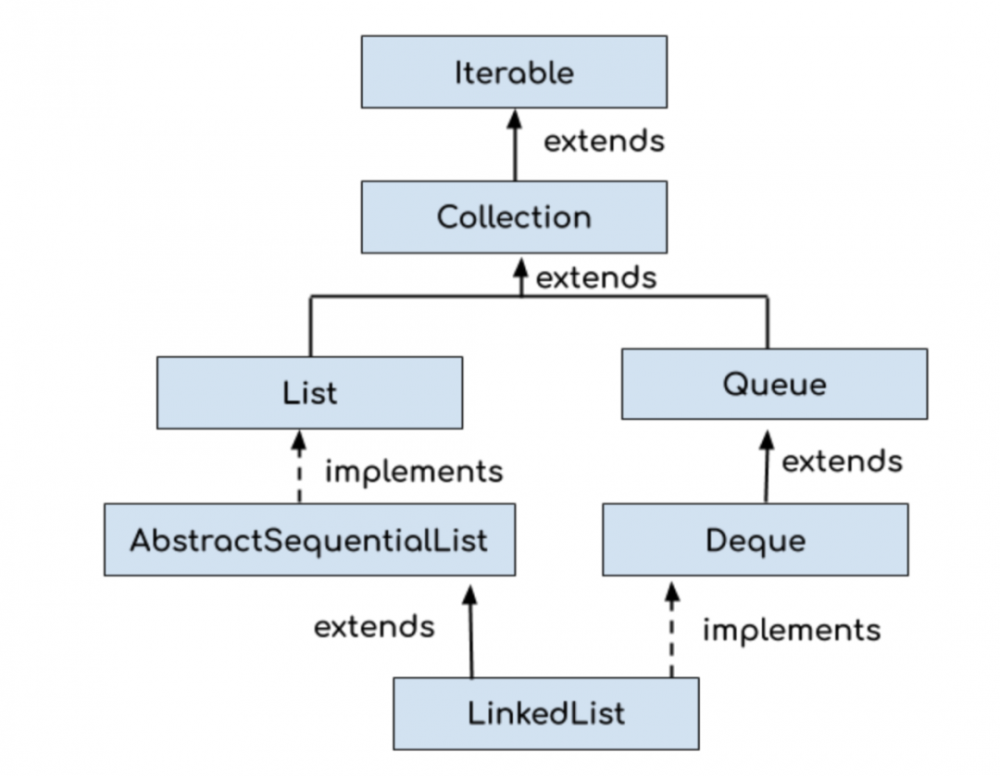
LinkedList 类的层次结构如下图所示:
-
LinkedList 是一个继承自 AbstractSequentialList 的双向链表,因此它也可以被当作堆栈、队列或双端队列进行操作。
-
LinkedList 实现了 List 接口,所以能对它进行队列操作。
-
LinkedList 实现了 Deque 接口,所以能将 LinkedList 当作双端队列使用。
明白了 LinkedList 的一些理论知识后,我们来看一下如何使用 LinkedList。
01、如何创建一个 LinkedList
LinkedList<String> list = new LinkedList<>();
和创建 ArrayList 一样,可以通过上面的语句来创建一个字符串类型的 LinkedList(通过尖括号来限定 LinkedList 中元素的类型,如果尝试添加其他类型的元素,将会产生编译错误)。
不过,LinkedList 无法在创建的时候像 ArrayList 那样指定大小。
02、向 LinkedList 中添加一个元素
可以通过 add() 方法向 LinkedList 中添加一个元素:
LinkedList<String> list = new LinkedList<>();
list.add("沉默王二");
list.add("沉默王三");
list.add("沉默王四");
感兴趣的小伙伴可以研究一下 add() 方法的源码,它在添加元素的时候会调用 linkLast() 方法。
void linkLast(E e) {
final LinkedList.Node<E> l = last;
final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
添加第一个元素的时候,last 为 null,创建新的节点(next 和 prev 都为 null),然后再把新的节点赋值给 last 和 first;当添加第二个元素的时候,last 为第一个节点,创建新的节点(next 为 null,prev 为第一个节点),然后把 last 更新为新的节点,first 保持不变,第一个节点的 next 更新为第二个节点;以此类推。
还可以通过 addFirst() 方法将元素添加到第一位; addLast() 方法将元素添加到末尾; add(int index, E element) 方法将元素添加到指定的位置。
03、更新 LinkedList 中的元素
可以使用 set() 方法来更改 LinkedList 中的元素,需要提供下标和新元素。
list.set(0, "沉默王五");
来看一下 set() 方法的源码:
public E set(int index, E element) {
checkElementIndex(index);
LinkedList.Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
该方法会先对指定的下标进行检查,看是否越界,然后根据下标查找节点:
LinkedList.Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
LinkedList.Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
LinkedList.Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
node() 方法会对下标进行一个初步的判断,如果靠近末端,则从最后开始遍历,这样能够节省不少遍历的时间,小伙伴们眼睛要睁大点了,这点要学。
找到节点后,再替换新值并返回旧值。
04、删除 LinkedList 中的元素
可以通过 remove() 方法删除指定位置上的元素:
list.remove(1);
该方法会调用 unlink() 方法对前后节点进行更新。
E unlink(LinkedList.Node<E> x) {
// assert x != null;
final E element = x.item;
final LinkedList.Node<E> next = x.next;
final LinkedList.Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
还可以使用 removeFirst() 和 removeLast() 方法删除第一个节点和最后一个节点。
05、查找 LinkedList 中的元素
如果要正序查找一个元素,可以使用 indexOf() 方法;如果要倒序查找一个元素,可以使用 lastIndexOf() 方法。
来看一下 indexOf() 方法的源码:
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (LinkedList.Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
基本上和 ArrayList 的大差不差,都需要遍历,如果要查找的元素为 null,则使用“==”操作符,可以避免抛出空指针异常;否则使用 equals() 方法进行比较。
另外, getFirst() 方法用于获取第一个元素; getLast() 方法用于获取最后一个元素; poll() 和 pollFirst() 方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的); pollLast() 方法用于删除并返回最后一个元素; peekFirst() 方法用于返回但不删除第一个元素。
06、最后
如果要我们自己实现一个链表的话,上面这些增删改查的轮子方法是一定要白嫖啊,不对,一定要借鉴啊。

上一篇ArrayList 中提到过,随机访问一个元素的时间复杂度为 O(1),但 LinkedList 要复杂一些,因为数据增大多少倍,耗时就增大多少倍,因为要循环遍历,所以时间复杂度为 O(n)。
至于 LinkedList 在插入、添加、删除元素的时候有没有比 ArrayList 更快,这要取决于数据量的大小,以及元素所在的位置。不过,从理论上来说,由于不需要移动数组,应该会更快一些。但到底快不快,下一篇带来答案,小伙伴们敬请期待。
------------------
公众号:沉默王二(ID:cmower)
CSDN:沉默王二
这是一个有颜值却靠才华吃饭的程序员,你知道,他的文章风趣幽默,读起来就好像花钱一样爽快。
长按下图二维码关注,你将感受到一个有趣的灵魂, 且每篇文章都有干货。

-------------- --- -
原创不易,莫要白票,如果觉得有点用的话,请毫不留情地素质三连吧,分享、点赞、在看, 因为这将是我写作更多优质文章的最强动力。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

