你真的懂Unicode编码吗?
公司mysql数据库用的utf8mb4字符集,然后合作的第三方公司的mysql数据库用的是utf8字符集,我们都知道,mysql的utf8字符集是utf8mb4的子集,于是公司的app用户输入utf8以外的字,比如" "(可别以为这是工厂的厂字,仔细看看吧!很难区分吧!其实就是用户用手写输入法输入的时候误选的一个特殊字符),结果Java程序从数据库读出带有这个特殊字符的数据推送给第三方合作公司的时候,他们的utf8字符集无法存储,导致报错。这其实算是mysql设计之初的一个bug,更详细的介绍可以参考 记住没:永远不要在 MySQL 中使用 UTF-8
解决方案
最好的解决方案当然是,第三方公司把数据库的编码也改成utf8mb4就皆大欢喜了嘛。但无奈第三方公司是一家体量颇大的国企公司,出于种种原因不是很倾向于这种解决方案。
那我们只好委屈一下自己了呀,我们这边在取出数据库中的数据的时候,对字符进行判断,如果是特殊字符,就把字符去掉。所以这个问题的难点,就转换成了,如何在Java代码中区分特殊字符。
碰到难题
但是我们把带有上面这个" "字复制到idea的时候,可以看到,Java中是这样表示的:
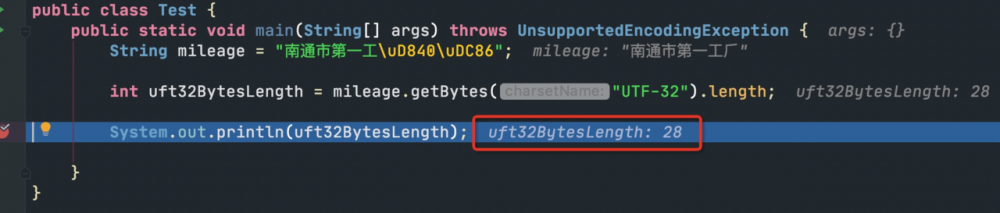
String mileage = "南通市第一工/uD840/uDC86"; 复制代码
我们这里设置的默认编码格式是UTF-8," "字表示成了2个unicode字符,而普通的汉字都是1个字符。我们肉眼很简单就能够区分特殊字符,而Java程序却无法知晓这两个unicode字符到底表示特殊字符,还是本来就是两个普通汉字。
寻找突破口
Java中的UTF-8其实和mysql的uft8都只能表示3个字节的字符,而Java中拥有和utf8mb4字符集一样表示范围的是UTF-32字符集。
于是我抱着尝试的心理,做了以下的debug调试:
UTF-32和UTF-8不同,它是一个定长的字符集,什么叫定长呢?比如UTF-8字符集就比较鸡贼,如果是“1”这样的数字,他在UTF-8字符集中映射数字为47,完全在2的8次方的表示范围内,也就说只要一字节就能满足了,这个时候UTF-8就把它转化成一字节的byte[],而对于映射成几千几万的汉字来说,UTF-8就会用长度为2或3的byte[]来表示。而UTF-32就很“老实”了,无论你映射成的数字是47,还是47000,还是更大,他都用长度为4的byte[]来表示(所以我们一般用UTF-8,因为UTF-32会浪费很多内存空间)。
上图所示的,uft32BytesLength的值为28,可以反推出,UTF-32判断的这个mileage字符串里面包含7个字符,也就是说,他把" "准确地判断为是一个字,而不是两个普通字合在一起!
从源码中汲取营养
既然JDK能识别特殊字符,那我们学习源码怎么写的不就好了。
于是从String#getBytes()方法一层层往下点,到最底一层,如下图:
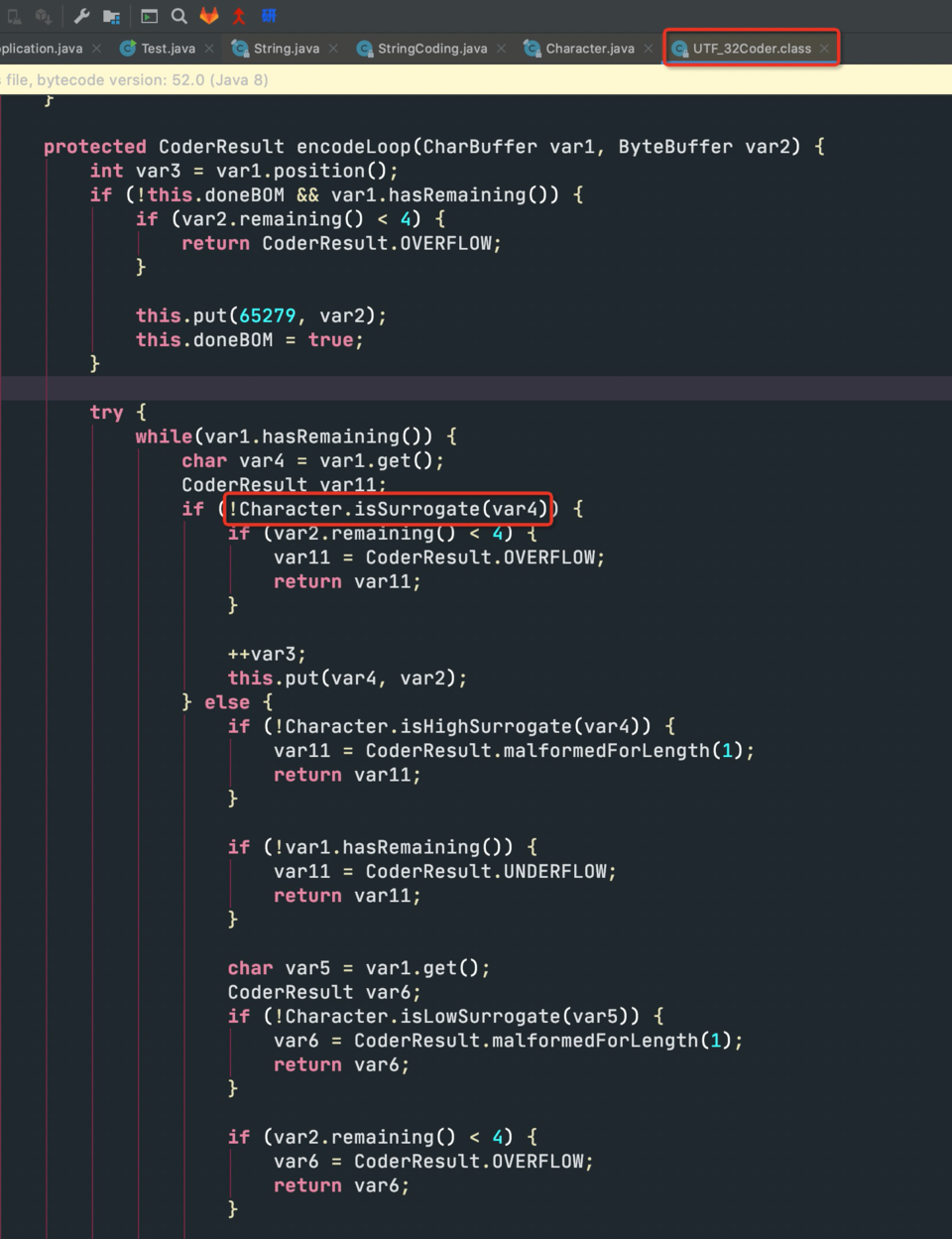
JDK就是通过这个方法来判断某个字符是普通字符还是属于特殊字符的一部分!
再点进去看这个方法:

这两段英文大致意思就是:
决定入参是否为unicode的代码单元,满足条件的字符并不是单独表示一个字,而是用来表示UTF-16的增补字符。
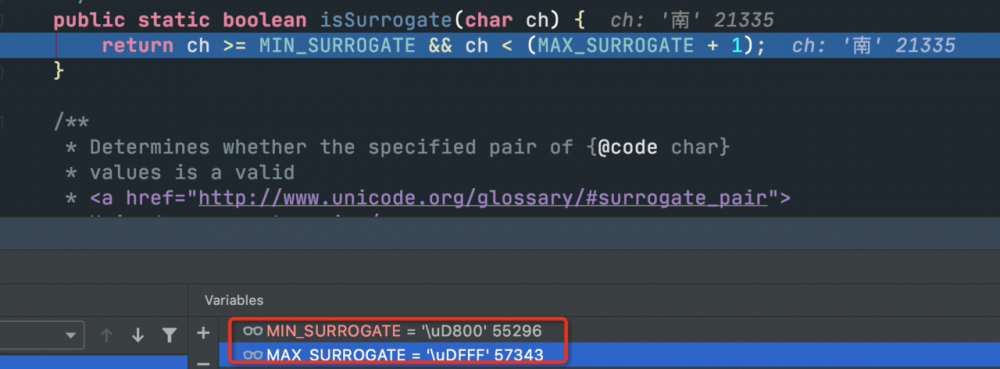
如上图所示,凡是落在'/uD800'到'/uDFFF',也就是55296到57343之间的字符都是用来两两表示特殊字符的!
解决问题
代码如下:
public String filterUtf8mb4Character(String input) {
List<Character> list = Lists.newArrayList();
char[] charArray = input.toCharArray();
for (char c : charArray) {
if (!Character.isSurrogate(c)) {
list.add(c);
}
}
char[] outputArray = new char[list.size()];
for (int i = 0; i < list.size(); i++) {
outputArray[i] = list.get(i);
}
return new String(outputArray);
}
复制代码
延伸阅读
可能有喜欢刨根问底的同学想问,那么UTF-32到底是怎么把两个unicode组合成一个特殊字符的呢,传送门--> Java 7之基础类型第4篇 - Java字符类型
感想总结
任何小问题只要肯钻研都会有不一样的收获,这也是决定大神和普通程序员的一个标准。
比如这个字符集的问题,我们从刚接触编程的时候就和它打交道了,但是又有几个人敢说自己精通呢?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

