JVM元数据区
如果你觉得该文章不错,请各位读者顺手点个赞,如果想要学些更多关于JVM的知识,请微信搜索公众号shysh95
元数据区
元数据区的概念出现在Java8以后,在Java8以前成为方法区,元数据区也是一块线程共享的内存区域,主要用来保存被虚拟机加载的 类信息、常量、静态变量以及即时编译器编译后的代码等数据。
由于元数据存储的信息不容易变动,因此它被安置在一块堆外内存,大小由-XX:MaxMetaspaceSize指定。
public class MetaSpaceTest {
public static void main(String[] args) {
int i = 0;
try {
for (i = 0; i < 100000; i++) {
new CglibBean(new HashMap<>());
}
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
System.out.println("total create count:" + i);
}
}
public static class CglibBean {
public CglibBean(Object object) {
Enhancer enhancer = new Enhancer();
enhancer.setUseCache(false);
enhancer.setCallback((MethodInterceptor) (obj, method, args, proxy) -> obj);
enhancer.setSuperclass(object.getClass());
enhancer.create();
}
}
}
上述代码通过Cglib生成大量的HashMap代理,下面我们在运行这段代码的时候指定下列参数
-XX:MaxMetaspaceSize=100M -XX:+PrintGCDetails
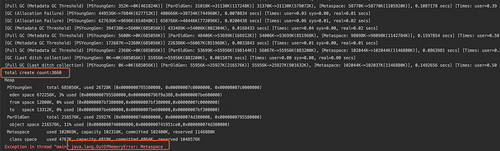
当我们程序循环至3660次,也就是说我们大约在生成了约3660个代理类以后元数据区发生了内存溢出,下面将MaxMetaspaceSize改为50M执行,
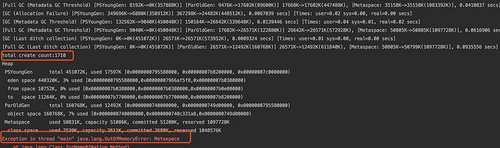
从上图可以看出当我们生成了1710个代理类以后元数据区发生了内存溢出,可见 一个元数据区的大小决定了Java虚拟机可以装载的类的多少。
运行时常量池
在元数据区中还有一块区域称为运行时常量池,此区域用来程序运行期间产生的常量,以及编译期生成的各种字面量和符号引用经类加载后的内容。
在Java中大概存储三种常量池概念,下面我们来讲一下Java中其他两种常量池,帮助读者了解他们中的区别。
首先大家在理解常量池的时候不要简单的理解为被final修饰的变量,常量在这里的含义是一切不变的东西, 包括final修饰的变量、字面量、类和接口全限定名、字段、方法名称以及修饰符等永恒不变的东西 。
类文件常量池
类文件常量池是指.class文件中的Constant_Pool项,如下图,类文件常量池存放的都是一些字面量和符号引用。
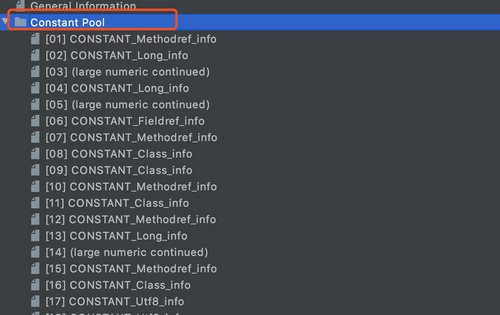
并不是所有的字面量都会存储在类文件常量池中,比如对于方法内(注意是方法)整数字面量,如果值在-32768~32767之间则会被直接嵌入JVM指令中去,不会保存在常量池中。
所以读者不会在常量池中知道CONSTANT_Integer_info为1的符号引用。
类文件常量池产生于编译时期,当JVM加载类文件时会将类文件常量池中的符合引用替换直接引用,加载之后的类文件信息将会被存放在运行时常量池。
字符串池
字符串池存在JDK1.6以前是存放在永久区中,但是在JDK1.7以后就被转移到堆上。
public static void intern() {
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
System.out.println(s1 == s2);
}
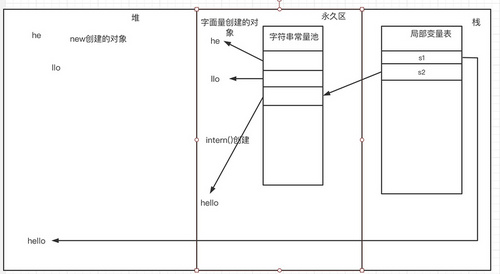
上述代码在JDK1.6的时候将会创建6个对象,首先new String("he")会在堆上创一个对象,并且"he"字面量会在永久区的字符串池上创建一个对象,new String("llo")同理创建了两个对象,最后的+又创建了一个对象,当调用intern()方法时,首先会去查找字符串池查找是否有hello内容的对象,发现没有则会在永久区中再创建一个对象,因此总共有6个对象,由于s1是堆中的对象,s2是永久区字符串池中的对象,因此s1==s2结果为false,详情如下图
但是在JDK1.6以后效果不再如此,原因就是由于字符串常量池被移到了堆中,intern方法也做了优化,在JDK1.6以后上述代码将会创建5个对象,首先new String("he")会在堆上创一个对象,并且"he"字面量也会在堆上创建一个对象, new String("llo")同理创建了两个对象,最后的+又创建了一个对象。当intern调用时,首先会在字符串池中查找是否有hello内容的对象,发现没有,此时不会主动创建而是先去查找堆中是否有hello内容的对象,如果有则直接将指针指向堆中的示例,因此这里一共会创建5个对象,由于s1和s2指向的是同一个对象实例,因此s1==s2为true,详情如下图
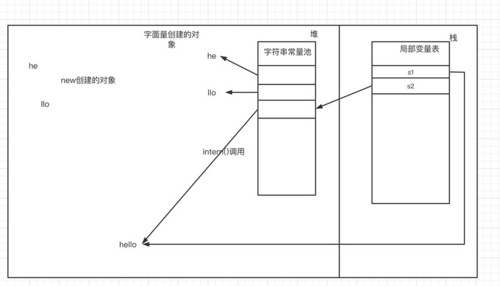
问题
为了帮助各位读者真正理解字符串常量池,下面有两段代码,请在脑海中给出结果,然后再进行Coding验证
public static void intern() {
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
String s3 = "hello";
System.out.println(s1 == s3);
System.out.println(s1 == s2);
}
public static void intern() {
String s3 = "hello";
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s2);
}
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

