深度分析:那些阿里,腾讯面试官都喜欢问的LinkedHashMap源码
LinkedHashMap 内部通过双向链表来维护节点的顺序, 可以按插入先后顺序来获取节点的值。 在实现上,它是继承于HashMap的,覆写了其中的部分方法。
1. LinkedHashMap 的构造方法
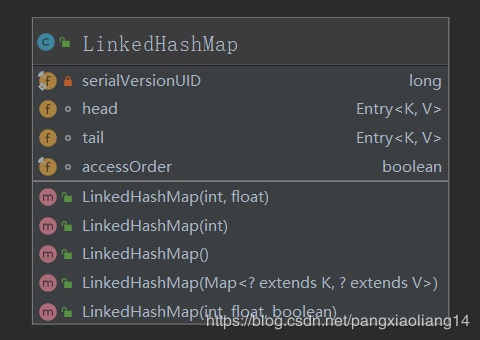
构造方法基本是和HashMap的方法类似,它的成员变量增加了头节点指针,尾节点指针,是否按访问顺序迭代 这三个成员变量。
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
//增加了前驱指针和后继指针,用于维护双向链表
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
/**
* The head (eldest) of the doubly linked list.
*/
//用于指向双向链表的头部
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
//用于指向双向链表的尾部
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
//是否按访问顺序来迭代,默认为false,也就是默认按插入先后顺序来迭代节点
final boolean accessOrder;
复制代码
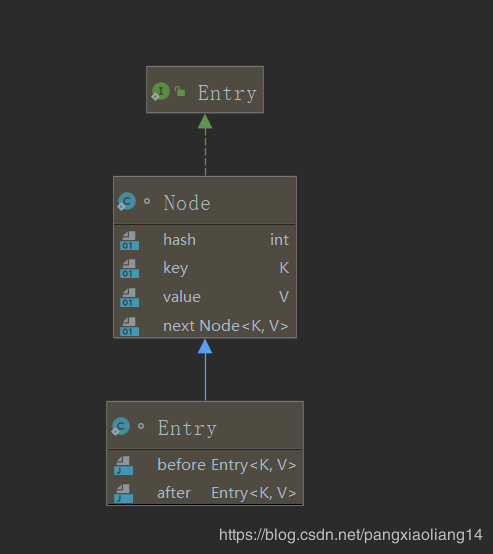
它的Entry<K, V>节点是继承于HashMap的Node, 增加了before指针和after指针, 用于实现双向链表。继承关系如下所示。
2. 链表节点的插入分析
首先调用的也是HashMap的Put相关方法, 只是重写了里面的newNode方法,创建的节点是自身定义的带有双向指针的节点,然后调用了linkNodeLast(p)方法,把节点插入到链表的尾部。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
复制代码
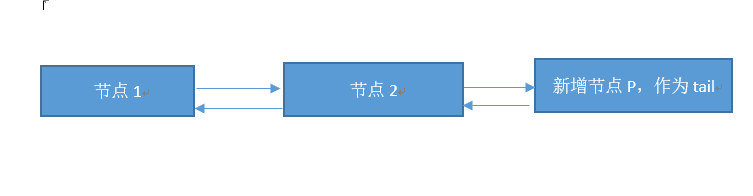
然后插入节点,重新修改节点的前驱和后继指针指向。
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//如果原来头节点为空,把当前节点作为头节点。否则把当前节点作为尾节点,用指针和原来的尾节点进行双向连接
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
复制代码
3. 节点的删除
删除节点也是调用HashMap的remove相关方法, 只是在链表或者红黑树中删除节点后,要调整双向链节点的前驱和后继节点的指针指向。
1. remove
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
复制代码
2. removeNode
//HashMap实现
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
//判断是否为红黑树的节点,是则按红黑树来获取到node
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//遍历单链表,寻找要删除的节点,并赋值给node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//从红黑树中删除
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//从单链表中删除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
//调用删除回调方法进行后续操作,LinkedHashMap覆写了该方法,调整了双向链表的节点指向,达到删除的目的
afterNodeRemoval(node);
return node;
}
}
return null;
}
复制代码
3. afterNodeRemoval
// LinkedHashMap覆写HashMap的方法,用于在双向链表中移除节点
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将p节点的前驱后继引用置空
p.before = p.after = null;
//b为null,表明p为头节点,要把p节点的后继节点作为新的头节点
if (b == null)
head = a;
else
b.after = a;
// a为null,表明p为尾节点,要把p节点的前驱节点作为新的尾节点
if (a == null)
tail = b;
else
a.before = b;
}
复制代码
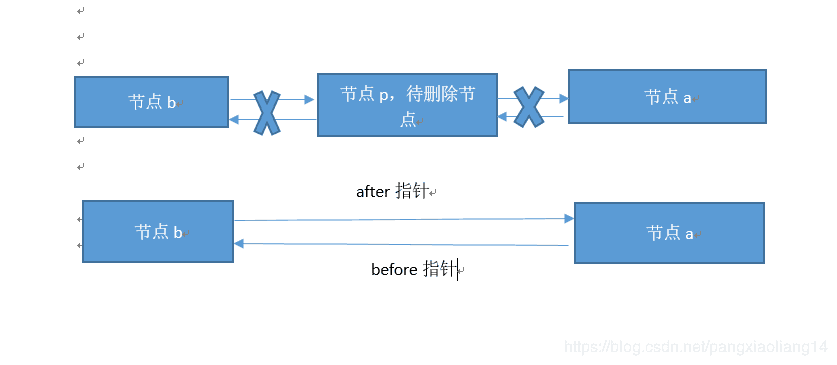
双向链表删除过程,其实就是改变节点的指针指向即可,要注意判断当前节点是否为头节点或者尾节点这两种特殊情况,这也是代码要具备鲁棒性的体现。指针调整过程如下图所示。
4. 访问顺序的维护过程
accessOrder 默认为false,按插入顺序来维护双向链表。如果我们把它设为true ,那么就是按访问节点的先后顺序来维护链表的。访问某个节点,就把该节点作为双向链表的最新的尾节点。
//覆写HashMap的方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
//如果accessOrder为true,则调用afterNodeAccess 将被访问节点移动到链表的尾部
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
复制代码
调整指针指向,设置尾节点。
//LinkedHashMap中重写
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
// 将 p 接在链表的最后
p.before = last;
last.after = p;
}
//把该节点作为最新的尾节点
tail = p;
++modCount;
}
}
复制代码
5. 基于LinkedHashMap实现LRU缓存
//插入完成后对节点做移除操作,默认不会执行
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
复制代码
这里面removeEldestEntry方法默认返回的是false,所以不会执行删除的逻辑。如果我们重写该方法,节点满足某些条件,就返回true,那么就可以删除节点了。例如节点的过期时间到了,就删除。或者节点数量超过某个值,就删除缓存。
//移除最近最少被访问条件之一,通过覆盖此方法可以实现不同策略的缓存
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
复制代码
6. 总结
LinkedHashMap 在HashMap的基础结构上,通过维护一条双向链表,实现了散列数据结构的有序排列。 LinkedHashMap是线程不安全的。当我们希望有顺序地去存取数据时,就可以使用LinkedHashMap了。它解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。
最后
感谢你看到这里,看完有什么的不懂的可以在评论区问我,觉得文章对你有帮助的话记得给我点个赞,每天都会分享java相关技术文章或行业资讯,欢迎大家关注和转发文章!
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

