Java 序列化和反序列化的底层原理
序列化是通过某种算法将存储于内存中的对象转换成可以用于持久化存储或者通信的形式的过程
反序列化是将这种被持久化存储或者通信的数据通过对应解析算法还原成对象的过程,它是序列化的逆向操作
为什么需要序列化
前端请求后端接口数据的时候,后端需要返回 JSON 数据,这就是后端将 Java 堆中的对象序列化为了 JSON 数据传给前端,前端可以根据自身需求直接使用或者将其反序列化为 JS 对象
RPC 远程调用过程中,调用者和被调用者必须约定好序列化和反序列化算法,比如 A 应用将 User 对象序列化为了 JSON 数据传给 B 应用,User 对象数据为 {"id": 1, "name": "long"} ,到达 B 应用的时候需要将这些数据反序列化为对象,如果此时 B 应用的反序列化算法是 XML 的话那么肯定就解析失败了,所以必须都得约定好他们都采用 JSON 序列化算法,那么基于 JSON 标准就能成功解析出 User 对象
Java 中的序列化
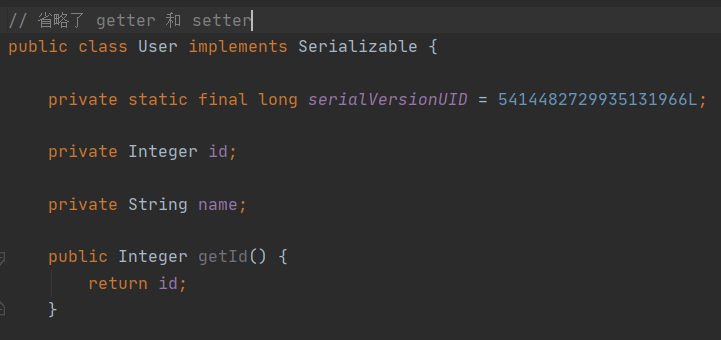
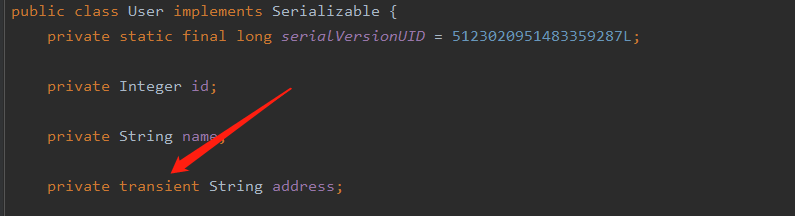
transient
如果某个字段我们不想通过 Java 默认序列化机制输出,我们就可以通过该字段来表明当前字段不需要被序列化
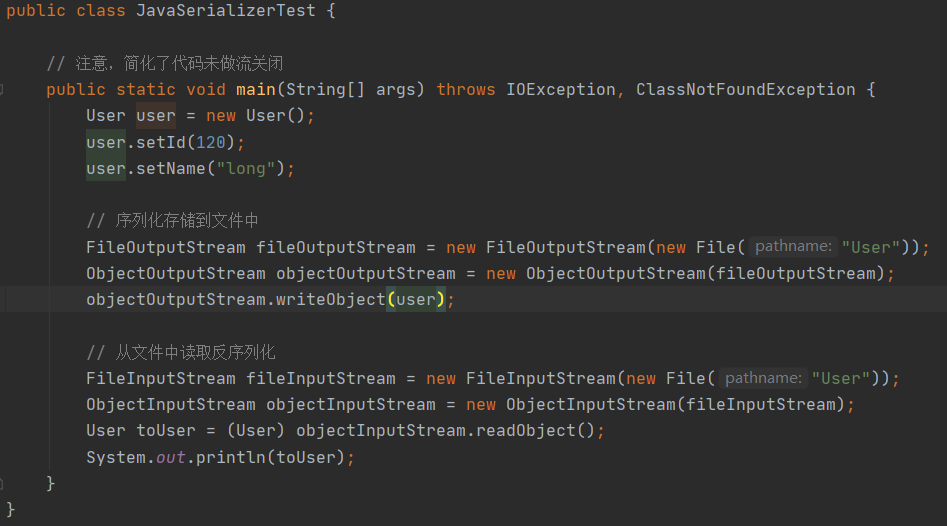
writeObject 和 readObject
我们想通过自定义的方式将 address 数据序列化
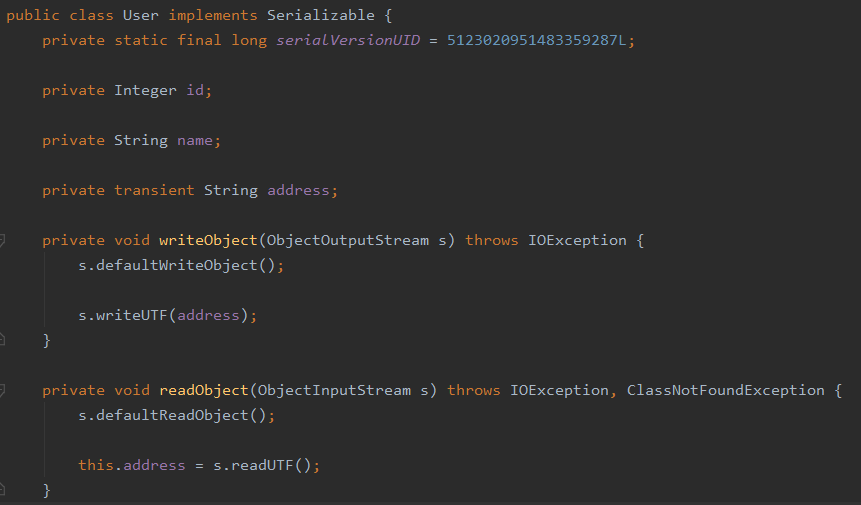
其中的 writeObject 作用于写序列化数据的时候会反射调用该方法,readObject 会在反序列化的时候调用
serialVersionUID 的作用
如果我们没有自定义 serialVersionUID 的话,会根据当前类的信息自动生成,如果当前类没有做修改那么生成的 serialVersionUID 是一致的,如果修改后 serialVersionUID 就会改变导致无法反序列化,所以在日常使用中我们一定要填写该字段
Java 序列化的实现原理
最开始看代码的时候,不要一下就陷入全部细节,我们应该只看我们目前关注的点,当认识逐渐深刻之后再来看一些细节,不然的话容易看的一脸懵逼
首先调用 objectOutputStream.writeObject(user); 然后调用 writeObject0(obj, false); 在这个方法里面有这样一段代码
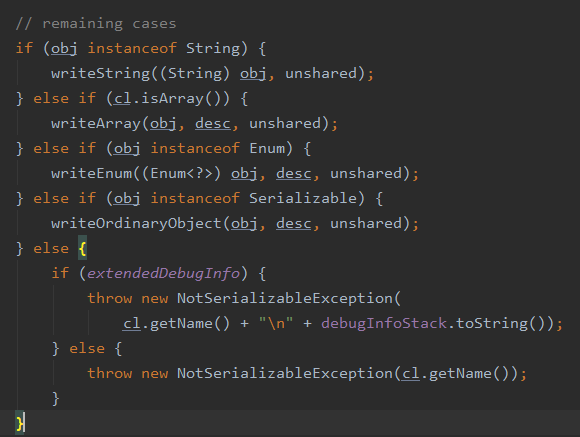
这里可以看到如果我们要序列化的是一个对象并且它没有实现 Serializable 接口的话就会直接抛出 NotSerializableException,由于我们目前传入的是 User 对象它实现了 Serializable 所以会进入到 writeOrdinaryObject 中
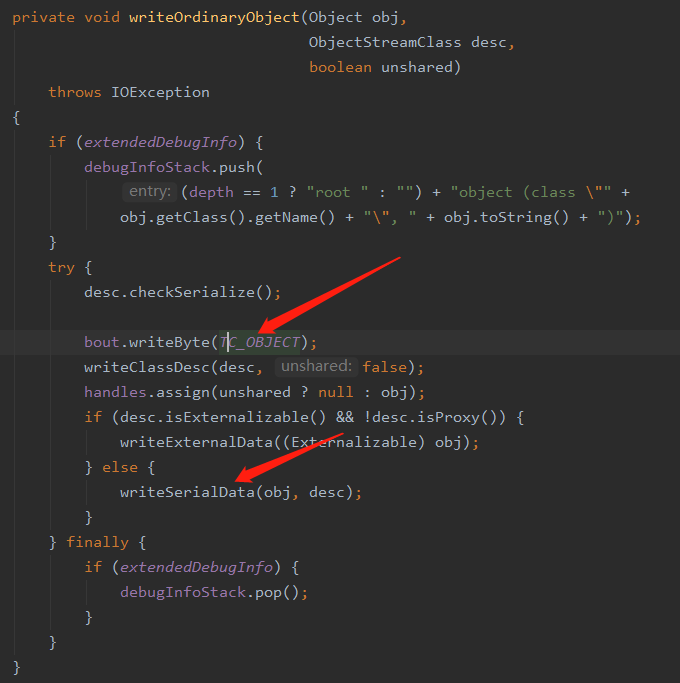
首先将 TC_OBJECT 这一个对象标志位写入到流中,标识着当前开始写一个的数据是一个对象,然后调用 writeSerialData 开始写入具体数据
-
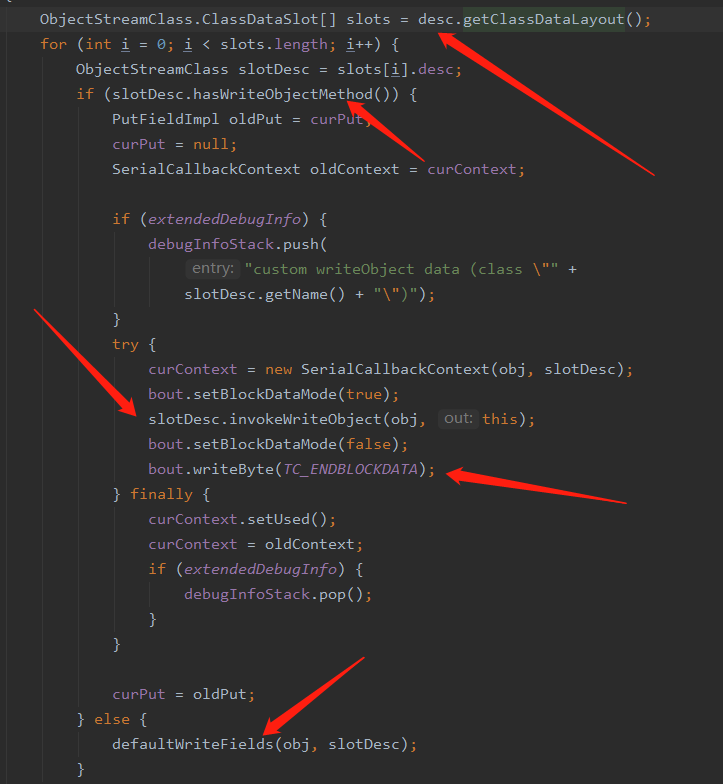
首先会获得 ClassDataSlot 我们可以把它看做是提供了序列化对象的辅助手段
-
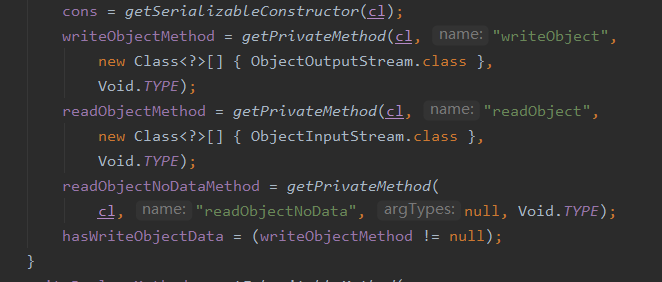
在此通过 ClassDataSlot 去检查序列化对象中是否实现了 writeObject 这个方法,那么这个 writeObjectMethod 是在什么时候初始化的呢?马上会讲到

-
如果实现了 writeObject 我们就去反射调用该方法
-
如果当前类没有实现 writeObject 方法就调用默认的 defaultWriteFields 去写数据
如何知道对象是否实现了 writeObject(ObjectOutputStream out) 和 readObject
在上文我们知道是通过 writeObjectMethod 这个来判断的,那么这个字段是在哪里初始化的呢,我们回到 ObjectOutputStream 的 writeObject0 方法,在调用后续的 writeOrderinaryObject 方法之前有这样一段代码
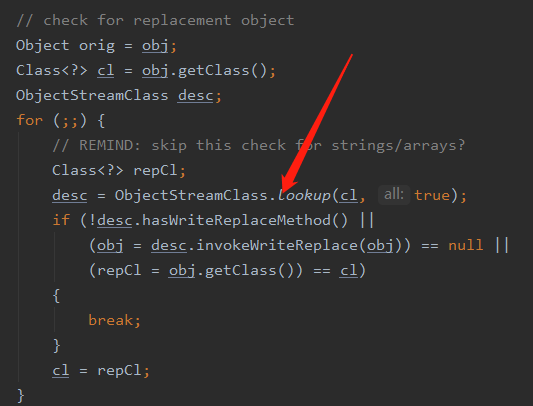
然后会调用到这段代码
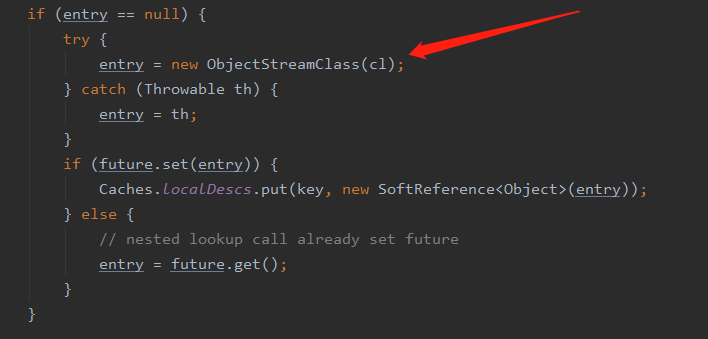
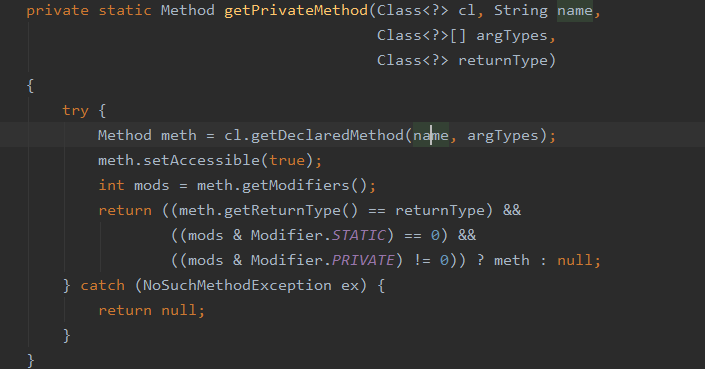
在创建 ObjectStreamClass 对象的过程中会通过反射去拿到当前类的方法,然后根据方法名 writeObject 和参数 ObjectOutputStream 去判断有没有这个方法,有的话就返回没有就返回为 null
然后我们回到 defaultWriteFields(Object obj, ObjectStreamClass desc) 继续来看

- 拿到当前需要写入数据的具体长度
- 通过反射去获取当前数据的值,ObjectStreamClass desc 这个对象可能是个 Object 可能是基本类型等,此时拿到的是 User 对象,所以取到的值默认为空,因为这里只是写入它的具体字段的数据
- 通过反射拿到当前对象的所有的值
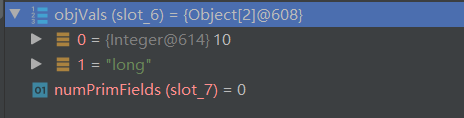
- 挨个调用 writeObject0 写入具体的值,首先调用的是 Integer 由于它是一个包装类,Integer 继承了 Number,Number 类实现了 Serializable 所以会和 User 对象走一样的流程到达次数(可以自己 DEBUG 一下)然后拆包取出值调用
- 随后就进入到了 String 的写入,再次调用 writeObject0,又到达 ObjectOutputStream 的 writeObject0,后续就有所区别了因为这里写入的具体类型是 String

因为 Integer 也实现了 Serializable 并且这里没有针对他坐特殊处理,所以它会走 writeOrdinaryObject,而 String 这里判断了,需要去调用 writeString

这个方法也比较简单首先写入 String 标志位然后写入具体的数据和长度,其它的类型也是一样会走这里不同的分支,最终将数据写入到流中
最后来看一下序列化后占用了多少个字节

Java 反序列化的原理
反序列化其实就是序列化的逆向过程,如果你看懂了序列化的关键代码,那么看这个过程就不会很难,下面贴出关键代码做出分析
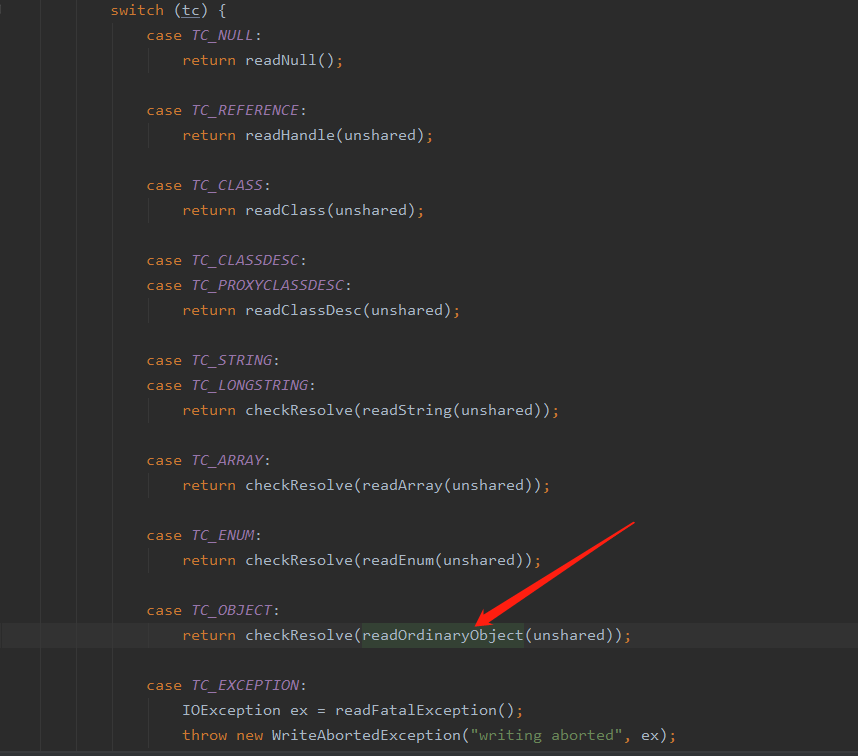
这里能够看到会根据反序列对象的具体类型分别做不同的处理,我们当前的对象是 User 对象所以会进入箭头指向的方法
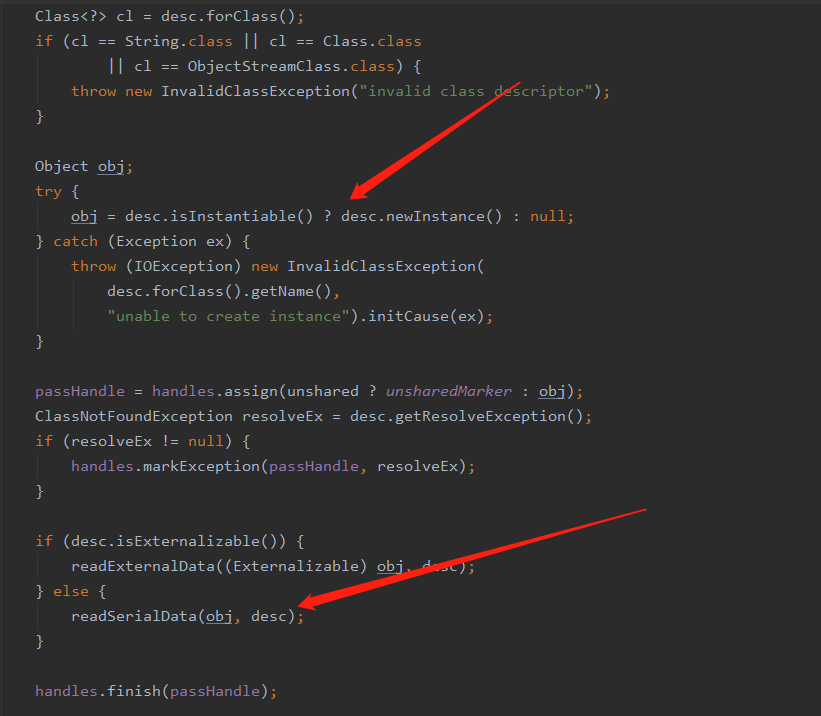
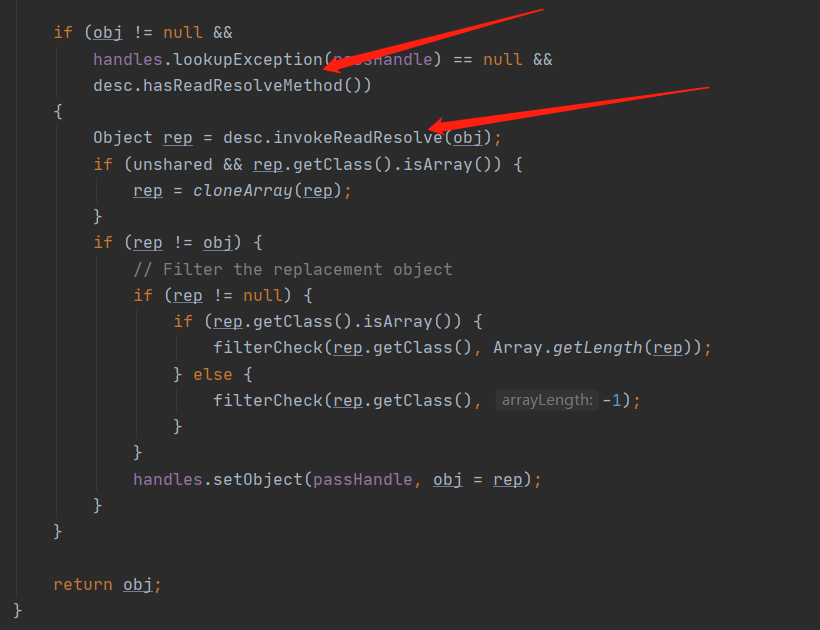
在该方法中会去创建一个实例对象,其中 isInstantiable 这个方法是去判断构造器是否初始化了,同时这里还会将 writeObject 和 readObject 方法设置好,然后会通过 hasReadResolveMethod 方法来确定是否实现了 readObject 方法如果实现了就反射调用 readObject 方法
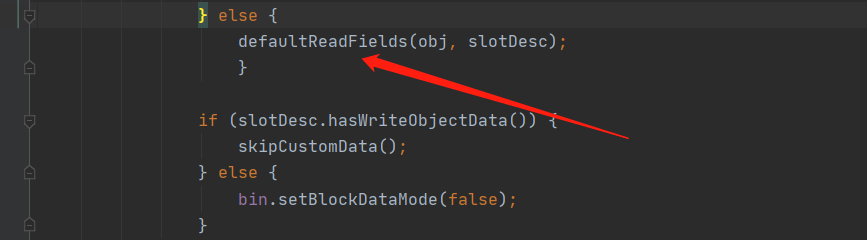
在调用了 readSerialData 方法之后会调用 defaultReadFields 方法来设置字段的值,当前的 Obj 是 User 对象
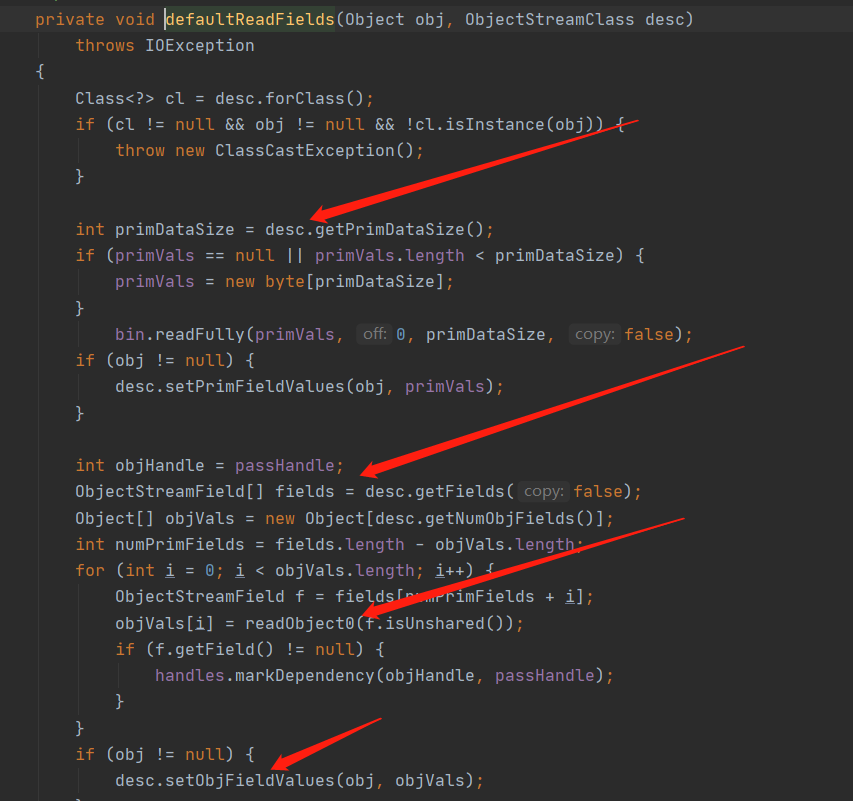
- 获取当前传入对象数据长度由于传入的是 User 空对象,所以此时长度为空
- 反射获取到需要被反序列化的所有字段,并且创建对应的数组来保存对应的值,此时获取到 User 对象有 2 个字段 id 和 name
- 然后开始递归调用 readObject0 处理完所有需要被反序列化的字段,就一当前的 id 和 name 举例
- 和上文序列化一样 id 是 Integer 包装类所以会被识别为 Object 当再次到达这个方法的时候,在第一步 primDataSize 数据长度为 4 因为是 int 类型 4 个字节
- 到第二步,因为是 Integer 没有其它需要被反序列化的字段它只有本身的拆包后的值,所以会到达第四步设置当前 id 的值
- 设置当前基本类型字段的值
对于 String 类型来说,在反序列化第一张中会调用读取对应的值
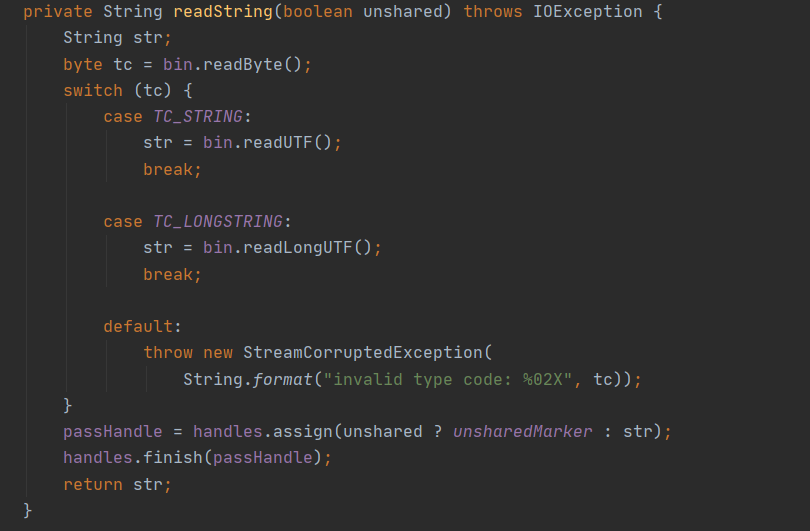
其它的序列化方式
一个新的技术的诞生都是有一定的原因和背景的,比如说 Java 原生序列化后数据比较大,传输效率低,同时又又无法跨语言通信,所以很多人选择使用 XML 的来序列化数据,XML 序列化后倒是解决了跨语言通信的问题,但是它序列化后的数据比原生数据还要大,所以就诞生了 JSON 序列化,他支持跨语言,并且序列化后的数据远远小于前 2 者,最后有人想进一步的优化大小就引入了 Protobuf 它具备 压缩 的功能,被压缩的数据小于 JSON 序列化后的数据。
其它的序列化方式
- XML
- JSON
- Jackson
- FastJson
- Hessian
- thrift
- protobuf
- ...
后面会写一篇文章就会来聊聊其它的序列化方式对比下他们的性能和底层使用原理
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

