SpringCloud- 第十三篇 Zuul高层架构(二)
1:架构图
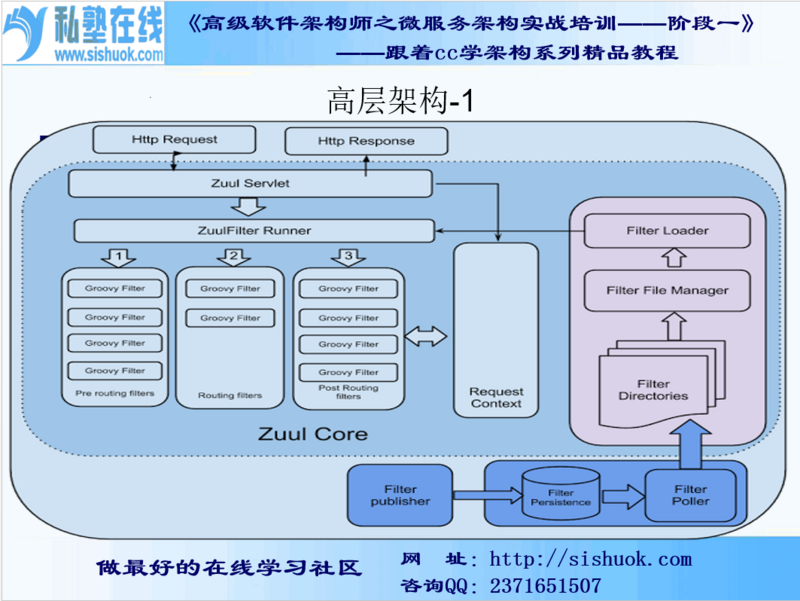
2:ZuulServlet
Zuul的核心是一系列的filters,Zuul大部分功能都是通过过滤器来实现的
1:ZuulServlet是Zuul的核心类,用来调度不同阶段的filters,处理请求,并处理异常等,路径是/zuul,可以使用zuul.servlet-path属性更改此路径
2:功能类似于SpringMvc的DispatcherServlet,所有的Request都要经过它的处理
3:里面有三个核心方法:preRoute(),route(), postRoute()
4:ZuulServlet会把具体的执行交给ZuulRunner去做,ZuulServlet是单例,因此ZuulRunner也仅有一个实例
5:Zuul的过滤器之间没有直接的相互通信,它们之间通过一个RequestContext的静态类来进行数据传递的。RequestContext类中有ThreadLocal变量来记录每个Request所需要传递的数据,ZuulRunner会初始化RequestContext
6:ZuulRunner直接将执行逻辑交由FilterProcessor处理,FilterProcessor也是单例,其功能就是依据filterType执行filter的处理逻辑,大致过程如下:
(1)根据Type获取所有输入该Type的filter
(2)遍历执行每个filter的处理逻辑,processZuulFilter(ZuulFilter filter)
(3)RequestContext对每个filter的执行状况进行记录,如果执行失败则对异常封装后抛出
3:生命周期
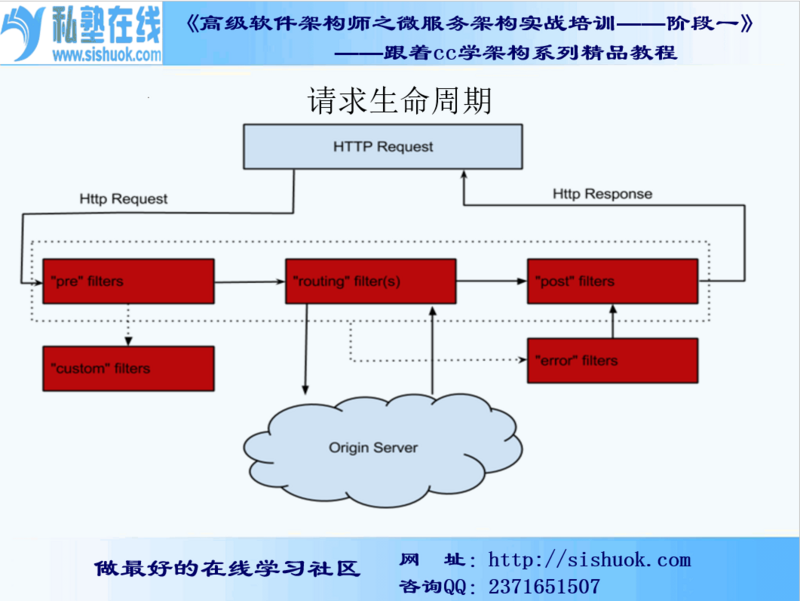
4:过滤器类型与请求生命周期
- PRE:这种过滤器在请求被路由之前调用。可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
- ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用Apache HttpClient或Netfilx Ribbon请求微服务。
- POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
- ERROR:在其他阶段发生错误时执行该过滤器。
一般来说,如果需要在请求到达后端应用前就进行处理的话,会选择前置过滤器,例如鉴权、请求转发、增加请求参数等行为。在请求完成后需要处理的操作放在后置过滤器中完成,例如统计返回值和调用时间、记录日志、增加跨域头等行为。
5:核心过滤器
5.1:概述
在spring cloud zuul中,为了让api网关组件可以被更方便的使用,它在http请求生命周期的各个阶段默认实现了一批核心过滤器,它们会在api网关服务启动的时候被自动加载和启动。
默认spring-cloud-netflix-core模块org.springframework.cloud.netflix.zuul.filters包下
5.2:pre过滤器
- ServletDetectionFilter
用来检测当前请求是通过Spring的DispatcherServlet处理运行的,还是通过ZuulServlet来处理运行的。它的检测结果会以布尔类型保存在当前请求上下文的isDispatcherServletRequest参数中,这样后续的过滤器中,可以通过RequestUtils.isDispatcherServletRequest()和RequestUtils.isZuulServletRequest()方法来判断请求处理的源头,以实现后续不同的处理机制。
一般情况下,发送到API网关的外部请求都会被Spring的DispatcherServlet处理,除了通过/zuul/*路径访问的请求会绕过DispatcherServlet,被ZuulServlet处理。
- FormBodyWrapperFilter:
解析表单数据,并对下游请求进行重新编码。
该过滤器仅对两类请求生效,第一类是Context-Type为application/x-www-form-urlencoded的请求,第二类是Context-Type为multipart/form-data并且是由String的DispatcherServlet处理的请求,而该过滤器的主要目的是将符合要求的请求体包装成FormBodyRequestWrapper对象
- DebugFilter:
该过滤器会根据配置参数zuul.debug.request和请求中的debug参数来决定是否执行过滤器中的操作。
它的具体操作内容是将当前请求上下文中的debugRouting和debugRequest参数设置为true。由于在同一个请求的不同生命周期都可以访问到这二个值,所以我们在后续的各个过滤器中可以利用这二个值来定义一些debug信息,这样当线上环境出现问题的时候,可以通过参数的方式来激活这些debug信息以帮助分析问题,另外,对于请求参数中的debug参数,我们可以通过zuul.debug.parameter来进行自定义。
- PreDecorationFilter:
此过滤器根据提供的RouteLocator确定在哪里和如何路由。
该过滤器会判断当前请求上下文中是否存在forward.do和serviceId参数,如果都不存在,那么它就会执行具体过滤器的操作(如果有一个存在的话,说明当前请求已经被处理过了,因为这二个信息就是根据当前请求的路由信息加载进来的)。
另外,还可以在该实现中找到对HTTP头请求进行处理的逻辑,其中包含了一些耳熟能详的头域,比如X-Forwarded-Host,X-Forwarded-Port。对于这些头域是通过zuul.addProxyHeaders参数进行控制的,而这个参数默认值是true,所以zuul在请求跳转时默认会为请求增加X-Forwarded-*头域,包括X-Forwarded-Host,X-Forwarded-Port,X-Forwarded-For,X-Forwarded-Prefix,X-Forwarded-Proto。也可以通过设置zuul.addProxyHeaders=false关闭对这些头域的添加动作
5.3:route过滤器
- RibbonRoutingFilter:
该过滤器只对请求上下文中存在serviceId参数的请求进行处理,即只对通过serviceId配置路由规则的请求生效。
该过滤器的执行逻辑就是面向服务路由的核心,它通过使用ribbon和hystrix来向服务实例发起请求,并将服务实例的请求结果返回
- SimpleHostRoutingFilter:
该过滤器只对请求上下文存在routeHost参数的请求进行处理,即只对通过url配置路由规则的请求生效。
该过滤器的执行逻辑就是直接向routeHost参数的物理地址发起请求,从源码中我们可以知道该请求是直接通过httpclient包实现的,而没有使用Hystrix命令进行包装,所以这类请求并没有线程隔离和断路器的保护。
- SendForwardFilter:
该过滤器只对请求上下文中存在的forward.do参数进行处理请求,即用来处理路由规则中的forward本地跳转装配
5.4:post过滤器
- SendErrorFilter:
该过滤器仅在请求上下文中包含error.status_code参数(由之前执行的过滤器设置的错误编码)并且还没有被该过滤器处理过的时候执行。
该过滤器的具体逻辑就是利用上下文中的错误信息来组成一个forward到api网关/error错误端点的请求来产生错误响应。
可以通过设置error.path属性来更改默认转发路径(/error)。
- SendResponseFilter:
该过滤器会检查请求上下文中是否包含请求响应相关的头信息,响应数据流或是响应体,只有在包含它们其中一个的时候执行处理逻辑。
其处理逻辑就是利用上下文的响应信息来组织需要发送回客户端的响应内容
5.5:禁用过滤器
- 重写shouldFilter逻辑,让它返回false
- 通过配置来禁用:
zuul.<SimpleClassName>.<filterType>.disable=true
<SimpleClassName>代表过滤器的类名,<filterType>代表过滤器类型
6: 重试机制
- Zuul的重试机制是依赖于Spring-Retry的,因此pom.xml必须有spring-retry,
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
- 开启重试,也可以具体的为某个服务开启重试
zuul.routes.user-api.retryable=true
其中的user-api是路由名称,可自行自定义
- 然后是相应的hystrix和Ribbon的配置
hystrix.command.default.execution.timeout.enabled=true hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=2000 ribbon.ConnectTimeout=250 ribbon.ReadTimeout=1000 ribbon.OkToRetryOnAllOperations=true ribbon.MaxAutoRetries=0 ribbon.MaxAutoRetriesNextServer=1
- 关闭重试机制
全局关闭:
zuul.retryable=false
指定路由关闭
zuul.routes.<route>.retryable=false
7: 饿汉式加载
- Zuul内部使用Ribbon调用远程URL,并且Ribbon客户端默认在第一次调用时由Spring Cloud加载。可以使用以下配置更改Zuul的此行为:
zuul.ribbon.eager-load.enabled=true
- 在Spring Cloud Zuul的饥饿加载中没有设计专门的参数来配置,而是直接采用了读取路由配置来进行饥饿加载的做法。所以,如果我们使用默认路由,而没有通过配置的方式指定具体路由规则,那么zuul.ribbon.eager-load.enabled=true的配置就没有什么作用了。
- 因此,在真正使用的时候,可以通过zuul.ignored-services=*来忽略所有的默认路由,让所有路由配置均维护在配置文件中,以达到网关启动的时候就默认初始化好各个路由转发的负载均衡对象
8:上传文件
8.1:对于小文件
Zuul不用做任何特别配置,直接按照路径进行路由就可以了
8.2:对于大文件
一个简单的方案就是使用在你的路径前添加上/zuul/,来绕开Spring的DispatcherServlet,以避免多部分处理,同时也规避了后台提取中文名乱码的问题。
- 要设置真正处理文件上传的应用,设置允许大文件上传,默认最大是10M,如:
spring.http.multipart.enabled=true spring.http.multipart.max-file-size=1000Mb spring.http.multipart.max-request-size=1500Mb
- 要设置zuul应用,主要是超时的问题,如:
zuul.host.socket-timeout-millis=10000 zuul.host.connect-timeout-millis=10000 hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=15000 ribbon.ConnectTimeout=500 ribbon.ReadTimeout=15000
9:健康检查
- 加入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- 配置示例
#开启健康检查(需要spring-boot-starter-actuator依赖) eureka.client.healthcheck.enabled=true #租期到期时间,默认90秒 eureka.instance.lease-expiration-duration-in-seconds=30 #租赁更新时间间隔,默认30,即30秒发送一次心跳 eureka.instance.lease-renewal-interval-in-seconds=10 #hystrix dashboard的信息收集频率,默认500毫秒 ,设置dashboard的刷新频率 hystrix.stream.dashboard.intervalInMilliseconds=5000
正文到此结束
- 本文标签: zuul ip UI 实例 src id Netflix stream servlet 配置 遍历 client IO ribbon 微服务 集群 解析 参数 ORM Spring cloud 重试机制 pom cat App Eureka Service springcloud retry 源码 线程 时间 文件上传 生命 Proxy apache tar API SpringMVC http Hystrix Hystrix Dashboard spring 负载均衡 数据 组织 统计 乱码 Dashboard https 调试 XML core bug
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

