Java SPI机制在Flink SQL中的应用
Java SPI机制,即Java Service Provider Interface,是Java提供的基于“接口编程 + 策略模式 + 配置文件”组合实现的动态加载机制。调用者可以根据实际使用需要,来启用、扩展或者替换框架的现有实现策略。在Java中,基于该SPI思想,提供了具体的实现,ServiceLoader,利用该类可以轻松实现面向服务的注册与发现,完成服务提供与使用的解耦。
Java SPI机制常见的例子,如:
- 数据库驱动接口实现类的加载:JDBC可以根据实际使用加载不同类型数据库的驱动,如OracleDriver、SQLServerDriver、Driver(MySql)。
- slf4j日志门面接口实现类的加载:slf4j日志门面并不是日志框架,需要使用Java SPI机制加载符合条件的日志框架接口实现类来完成日志框架的绑定,如Log4j、Logback等。
具体使用请参考 高级开发必须理解的Java中SPI机制 。
Java SPI机制在Flink中的应用
在Flink SQL程序中用到了Java SPI机制动态加载各种Factory的实现类。比如说,对于TableFactory接口,Flink程序会从程序所使用到的依赖中找到META-INF/services/org.apache.flink.table.factories.TableFactory,并通过反射实例化TableFactory接口的实现,并通过TableFactoryService#filter()方法筛选出符合条件的TableFactory实现类。以Flink SQL程序从Kafka(版本0.11)读取数据为例,Flink SQL程序会首先获得TableFactory所有可用的实现类,通过TableFactoryService#filter()得到符合条件的TableFactory实现类Kafka011TableSourceSinkFactory实例。本文主要说明Java SPI机制在Flink SQL程序中的应用,对于 对TableFactory实现类的筛选 将在另一篇文章中说明。
特别说明:本文涉及的flink源码版本为1.9。
tEnv
.connect(
new Kafka()
.version("0.11")
.topic(topic)
.startFromLatest()
.properties(props))
.withSchema(schema)
.withFormat(format)
.registerTableSource("record");
复制代码
上述程序用于与Kafka建立连接,并指定了读取数据的结构与格式,最后使用registerTableSource完成table source的注册工作。我们跟进代码,可以发现内部调用了TableFactoryService#find()方法查找到符合条件的TableSourceFactory实例,并调用createTableSource()方法创建Kafka011TableSource实例。
# TableFactoryUtil.java
private static <T> TableSource<T> findAndCreateTableSource(Map<String, String> properties) {
try {
return TableFactoryService
.find(TableSourceFactory.class, properties)
.createTableSource(properties);
} catch (Throwable t) {
throw new TableException("findAndCreateTableSource failed.", t);
}
}
复制代码
# TableFactoryService
public static <T extends TableFactory> T find(Class<T> factoryClass, Map<String, String> propertyMap) {
return findSingleInternal(factoryClass, propertyMap, Optional.empty());
}
复制代码
# TableFactoryService.java
private static <T extends TableFactory> T findSingleInternal(
Class<T> factoryClass,Map<String, String> properties,Optional<ClassLoader> classLoader) {
List<TableFactory> tableFactories = discoverFactories(classLoader);
List<T> filtered = filter(tableFactories, factoryClass, properties);
...
}
复制代码
在TableFactoryService#findSingleInternal()方法里面,我们可以看见里面主要使用了两个方法,discoverFactories()方法主要用来查询当前Flink SQL程序中提供的TableFactory接口的实现类,filter()方法则是用来筛选出满足条件的TableFactory的实现类。很显然,Java SPI机制的使用就在discoverFactories()方法内部。
#TableFactoryService.java
private static List<TableFactory> discoverFactories(Optional<ClassLoader> classLoader) {
try {
List<TableFactory> result = new LinkedList<>();
if (classLoader.isPresent()) {
ServiceLoader
.load(TableFactory.class, classLoader.get())
.iterator()
.forEachRemaining(result::add);
} else {
defaultLoader.iterator().forEachRemaining(result::add);
}
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for table factories.", e);
throw new TableException("Could not load service provider for table factories.", e);
}
}
复制代码
在discoverFactories()方法中,由于传进来的classLoader为Optional.empty(),即classLoader.isPresent()为false,故执行的是else代码块。
private static final ServiceLoader<TableFactory> defaultLoader = ServiceLoader.load(TableFactory.class); 复制代码
可以看到defaultLoader是一个静态类变量,也正是因为这个缘故,Flink SQL 1.9代码可能会出现一个Bug。当然,这个Bug我们在文末会进行说明。
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,ClassLoader loader) {
return new ServiceLoader<>(service, loader);
}
# service => TableFactory, loader => AppClassLoader, acc => null
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
复制代码
在ServiceLoader的构造方法中,我们可以看到,完成对service、loader、acc变量的赋值工作。
// Cached providers, in instantiation order
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
private LazyIterator lookupIterator;
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
复制代码
在reload()方法中,首先清空providers变量中存储的数据,另外创建了LazyIterator实例。providers变量存储读取到的是services文件夹中的TableFactory的实现类的实例。LazyIterator,顾名思义,完全延迟的提供程序查找(fully-lazy provider lookup)。
private class LazyIterator implements Iterator<S> {
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null; # 用于保存项目中所有的依赖名
Iterator<String> pending = null; # 用于保存每个依赖中services文件夹的TableFactory实现类的全路径名
String nextName = null; # 用于保存当前TableFactory实现类的全路径名
# service -> TableFactory, loader -> AppClassLoader
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
...
}
private S nextService() {
...
}
public boolean hasNext() {
...
}
public S next() {
...
}
public void remove() {
...
}
}
复制代码
看完defaultLoader变量,我们继续往下进行。
defaultLoader.iterator().forEachRemaining(result::add); 复制代码
# ServiceLoader.java
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
复制代码
可以看到defaultLoader.iterator()方法中,创建了一个Iterator接口的内部类,并且创建了knownProviders实例,并且提供了hasNext()、next()、remove()等方法。 看完iterator()方法后,我们继续看forEachRemaining()。
#Iterator.java
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
复制代码
值得说明的事,该处的hasNext(),next()方法实际上调用的是上述Iterator接口的内部类的hasNext()、next()方法。首先,我们来看下,hasNext()方法的实现。
public boolean hasNext() {
# 由于程序第一次寻找TableFactory的实现类,因此providers在一开始是经过clear()处理的,
# 同时,knownProviders = providers.entrySet().iterator();
# 也就是说knownProviders.hasNext()在当前这一组TableFactory实现类的查询过程中都是为false。
# 进入lookupIterator.hasNext()中。
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
# lookupIterator
public boolean hasNext() {
# 在Flink SQL查询TableFactory接口实现类时,acc(AccessControlContext:创建ServiceLoader时采取的访问控制上下文)始终为null
if (acc == null) {
return hasNextService();
}
...
}
# lookupIterator
private boolean hasNextService() {
# nextName 表示查询到的下一个TableFactory实现类的全路径名
if (nextName != null) {
return true;
}
# 在程序第一次寻找TableFactory的实现类时,其为null(Enumeration<URL> configs = null)。
if (configs == null) {
try {
# PREFIX = META-INF/services/
# service.getName()为TableFactory的全路径名
# 这里也就说明了,Java SPI机制在哪里读取接口的实现类。
String fullName = PREFIX + service.getName();
# 使用classloader根据路径去加载资源信息,
# 并将加载到项目中所有包含META-INF/services/org.apache.flink.table.factories.TableFactory的依赖jar地址,
# classLoader等信息保存到变量configs(Enumeration<URL> configs)中。
# 当系统实例化一个jar中的TableFactory实现类后,会通过configs.next()方法读取下一个jar中services文件中的内容。
# configs数据结构如下图所示。
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
# pending变量用于存储一个依赖jar中读取到的TableFactory实现类的全路径名,
# 其是一个Iterator数据接口,需要使用的时候,每次每次调用pending.next()方法
# 并将得到的TableFactory实现类的全路径名赋值给nextName。(Iterator<String> pending = null)
# 其中pending为null表示第一次进行TableFactory接口实现类的读取时,
# !pending.hasNext() = true则表示当读取完一个依赖jar中services文件夹的内容时,
# 希望继续从接下来的依赖jar中读取信息。
while ((pending == null) || !pending.hasNext()) {
# 当所有的依赖都遍历完后,configs.hasMoreElements()将返回false,
# 这个时候也就意味着这一组TableFactory实现类查询结束。
if (!configs.hasMoreElements()) {
return false;
}
# parse()方法用于读取一个依赖jar中的services文件夹中的TableFactory接口实现类的全路径名并保存到pending变量中。
# 该方法中,有一点值得说明的事,如果providers中已经保存了TableFactory接口实现类的全路径名A,即使当前依赖jar中任然包含该全路径名A,
# 那么这个时候,这个全路径名A也就不会添加到pending变量中。这样就能够保证providers中的保存的TableFactory的实现类实例唯一,
# 即使多个依赖的services文件夹里面包含同一个实现类的全路径名
pending = parse(service, configs.nextElement());
}
# 读取pending中保存的TableFactory接口实现类的全路径名,并保存到nextName变量中。
nextName = pending.next();
return true;
}
复制代码
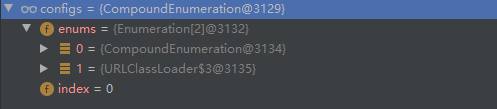
在这个hasNext()方法中,主要做了以下几件事:
- 根据资源路径名(META-INF/services/org.apache.flink.table.factories.TableFactory)使用classloader加载资源信息并赋值给configs变量。
- 从configs变量中获取一个依赖jar,并从这个依赖jar中读取TableFactory接口的全路径名,然后将这些全路径名保存到pending变量中。
- 从pending变量中取出一个TableFactory接口的全路径名,保存到nextName变量中,以供在next()方法中使用。
接下来我们再来看下next()方法。
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
# lookupIterator
public S next() {
# 在Flink SQL查询TableFactory接口实现类时,acc(AccessControlContext:创建ServiceLoader时采取的访问控制上下文)始终为null
if (acc == null) {
return nextService();
}
...
}
# lookupIterator
private S nextService() {
# hasNextService()方法就是上述的方法,这个时候nextName != null,则其返回true。
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
# nextName赋值为null,用于下一次的TableFactory接口实现类全路径名的赋值工作。
nextName = null;
Class<?> c = null;
...
# 使用Class.forName()根据TableFactory接口实现类的全路径名进行反射,
# 并根据全路径名对该类进行实例化
c = Class.forName(cn, false, loader);
...
S p = service.cast(c.newInstance());
# 将实例化后的TableFactory接口实现类保存到providers变量中。
providers.put(cn, p);
return p;
...
}
复制代码
至此,TableFactory接口实现类的一次查询工作结束。接下来就是在一个依赖jar中多个TableFactory接口实现类的查询工作,然后就是当前项目中所有包含META-INF/services/org.apache.flink.table.factories.TableFactory的依赖jar中的查询工作。大体工作相同,这里就不赘述。
Java SPI机制在Flink SQL 1.9中存在的问题
现有如下场景,有两个MQ(消息队列)产品,记为A、B,Flink有对应的connector工作flink-connector-A,flink-connector-B,并且这两个里面都包含了META-INF/services/org.apache.flink.table.factories.TableFactory文件。这个时候,在同一个集群中,从flink-connector-A进行消费的Flink SQL程序1启动后,又启动从flink-connector-2消费的Flink SQL程序2时就会报出如下异常:
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException:
Could not find a suitable table factory for
'org.apache.flink.table.factories.TableSourceFactory' in the classpath.
...
50395:The following factories have been considered:
...
51110:org.apache.flink.streaming.connectors.kafka.A
...
复制代码
很明显,Flink SQL程序2查询到的TableFactory接口的实现类信息实际上是Flink SQL程序1查询到的信息。这个问题的产生,原因在于defaultLoader变量。
# TableFactoryService private static final ServiceLoader<TableFactory> defaultLoader = ServiceLoader.load(TableFactory.class); 复制代码
TableFactoryService类其内部变量,方法都是static进行修饰。在Flink SQL程序1中进行TableFactory接口实现类的查找后,defaultLoader变量引用的变量providers中保存了该次读取到的TableFactory接口的实例类。当程序Flink SQL程序2准备查找TableFactory接口实现类时,会直接使用Flink SQL程序1中的defaultLoader(因为其是静态变量,会保存在JVM中,除非集群停止)。
defaultLoader.iterator().forEachRemaining(result::add);
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
public Iterator<S> iterator() {
return new Iterator<S>() {
# 这个时候knownProviders保存的数据就是Flink SQL程序1读取到TableFactory接口实现类的实例
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
# 此时,kownProviders.hasNext() 为true
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
# 此时,knownProviders.hasNext() 为true
if (knownProviders.hasNext())
# 从knownProviders中读取TableFactory接口实现类的实例
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
复制代码
至此,我们就很清楚的知道了,为什么Flink SQL程序2中为什么会读取到Flink SQL程序1查询到的TableFactory接口的实现类数据。值得庆幸的是,Flink 1.10中已经解决了这个bug。
private static List<TableFactory> discoverFactories(Optional<ClassLoader> classLoader) {
try {
List<TableFactory> result = new LinkedList<>();
ClassLoader cl = classLoader.orElse(Thread.currentThread().getContextClassLoader());
ServiceLoader
.load(TableFactory.class, cl)
.iterator()
.forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for table factories.", e);
throw new TableException("Could not load service provider for table factories.", e);
}
}
复制代码
文终
很遗憾的说,推酷将在这个月底关闭。人生海海,几度秋凉,感谢那些有你的时光。
原文 https://juejin.im/post/5f15a1b7f265da22ec609e77正文到此结束
- 本文标签: MQ sql App stream provider ssl Action Oracle 数据 HashMap 消息队列 http db IO 集群 CTO JDBC final apache Property find UI bug 实例 src tab cache cat 代码 构造方法 开发 java Security tar 配置 id parse schema 源码 ORM 产品 API JVM list mysql 文章 map 希望 遍历 Logback consumer classpath Service 数据库 IDE LinkedList value ACE https
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

