解读 Java 内存模型
伟人之所以伟大,是因为他与别人共处逆境时,别人失去了信心,他却下决心实现自己的目标。
Java内存模型(Java Memory Model)定义了Java的线程在访问内存时会发生什么。这里针对以下几个要点进行解析:
- 重排序
- 可见性
- synchronized
- volitile
- final
- Double-Checked Locking
首先了解一下与Java内存模型交互时的指南:
* 使用synchronized或volatile来保护在多个线程之间共享的字段 * 将常量字段设置为final * 不要从构造函数中泄露this
重排序
什么是重排序
所谓重排序,英文记作Reorder,是指编译器和Java虚拟机通过改变程序的处理顺序来优化程序。虽然重排序被广泛用于提高程序性能,不过开发人员几乎不会意识到这一点。实际上,在运行单线程程序时我们无法判断是否进行了重排序。这是因为,虽然处理顺序改变了,但是规范上有很多限制可以避免程序出现运行错误。
但是,在多线程程序中,有时就会发生明显是由重排序导致的运行错误。
示例程序1
下面代码展示了一段帮助我们理解重排序的示例程序。在Something类中,有x、y两个字段,以及write、read这两个方法。x和y会在最开始被初始化为0。write方法会将x赋值为100,y赋值为50。而read方法则会比较x和y的值,如果x比y小,则显示x<y。
Main类的main方法会创建一个Something的实例,并启动两个线程。写数据的线程A会调用write方法,而读数据的线程B则会调用read方法。
class Something {
private int x = 0;
private int y = 0;
public void write() {
x = 100;
y = 50;
}
public void read() {
if(x < y) {
System.out.println("x < y");
}
}
}
public class Main {
public static void main(String[] args) {
final Something obj = new Something();
// 写数据的线程A
new Thread() {
public void run() {
obj.write();
}
}.start();
// 读数据的线程B
new Thread() {
public void run() {
obj.read();
}
}.start();
}
}
问题是,在运行这段程序后会显示出"x < y"吗?
由于write方法在给x赋值后会接着给y赋值,所以x会先从0变为100,而之后y则会从0变为50。因此,大家可能会做出绝对不可能显示"x < y"的判断。但是,这么判断是错误的。
大家应该会很吃惊,因为在Java内存模型中,是有可能显示出x < y 的。原因就在于重排序。
在write方法中,由于对x的赋值和对y的赋值之间不存在任何依赖关系,编译器可能会改变赋值顺序。而且,在线程A已经为y赋值,但尚未为x赋值之前,线程B也可能会去查询x和y的值并执行if语句进行判断,这时x < y的关系成立。
假设如示例程序1所示,对于一个字段,有“写数据的线程”和“读数据的线程”,但是我们并没有使用synchronized关键字和volatile关键字修饰该字段来正确的同步数据时,我们称这种没有同步的状态为“存在数据竞争”。此外,我们称这样存在数据竞争的程序为未正确同步(incorrectly synchronized)的程序。由于未正确同步的程序缺乏安全性,所以必须使用synchronized或volatile来正确地进行同步。
虽然示例程序1是未正确同步的程序,但是讲write和read都声明为synchronized方法,就可以实现正确同步的程序。
可见性
什么是可见性
假设线程A将某个值写入到字段x中,而线程B读取到了该值。我们称其为“线程A向x的写值对线程B是可见(visible)的”。“是否是可见的”这个性质就称为可见性,英文记作visibiliy。
在单线程程序中,无须在意可见性。这是因为,线程总是可以看见自己写入到字段中的值。
但是,在多线程程序中必须注意可见性。这是因为,如果没有使用synchronized或volatile正确地进行同步, 线程A写入到字段中的值可能并不会立即对线程B课可见。 开发人员必须非常清楚地知道在什么情况下一个线程的写值对其他线程是可见的。
示例程序2
下面代码展示了一段因没有注意到可见性而导致程序失去生存性的示例程序。
class Runner extends Thread {
private boolean quit = false;
public void run() {
while(!quit) {
// ...
}
System.out.println("Done");
}
public void shutdown() {
quit = true;
}
}
public class Main {
public static void main(String[] args) {
Runner runner = new Runner();
// 启动线程
runner.start();
// 终止线程
runner.shutdown();
}
}
Runner类的run方法会在字段quit变为true之前一直执行while循环。当quit变为true,while循环结束后,会显示字段Done。
shutdown方法会将字段quit设置为true。
Main类的main方法会先调用start方法启动Runner线程,然后调用shutdown方法将quit的值设置为true。我们原本以为在运行这段程序时,Runner线程会立即显示出Done,然后退出。但是Java内存模型可能会导致Runner线程永远在while循环中不停地循环也就是说,示例程序2可能会失去生存性。
原因是,向字段quit写值的线程(主线程)与读取字段quit的线程(Runner)是不同的线程。主线程向quit写入的true这个值可能对Runner线程永远不可见(非visible)。
如果以“缓存”的思路来理解不可见的原因可能会有助于大家理解。主线程向quit写入的true这个值可能只是被保存在主线程的缓存中。而Runner线程从quit读取到的值,仍然是在Runner线程的缓存中保存者的值false,并没有任何变化。不过如果将quit声明为volatile字段,就可以实现正确同步的代码。
共享内存与操作
在Java内存模型中,线程A写入的值并不一定会立即对线程B可见。下图展示了线程A和线程B通过字段进行数据交互的情形。
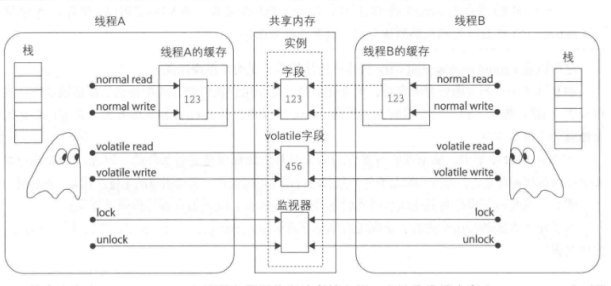
共享内存(shared memeory)是所有线程共享的存储空间,也被称为堆内存(heap memory)。因为实例会被全部保存在共享内存中,所以实例中的字段也存在与共享内存中。此外,数组的元素也被保存在共享内存中。也就是说,可以使用new在共享内存中分配存储空间。
局部变量不会被保存在共享内存中。通常,除局部变量外,方法的形参、catch语句块中编写的异常处理器的参数等也不会被保存在共享内存中,而是被保存在各个线程持有的栈中。正是由于它们没有被保存在共享内存中,所以其他线程不会访问它们。
在Java内存模型中,只有可以被多个线程访问的共享内存才会发生问题。
下图展示了6种操作(action)。这些操作是我们把定义内存模型时使用到的处理分类而成的。
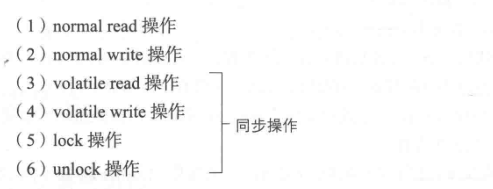
这里,(3)~(6)的操作是进行同步(synchronization)的同步操作(synchronization action)。进行同步的操作具有防治重排序,控制可见性的效果。
normal read/normal write操作表示的是对普通字段(volatile以外的字段)的读写。如上图所示,这些操作是通过缓存来执行的。因此,通过normal read读取到的值并不一定是最新的值,通过normal write写入的值也不一定会立即对其他线程可见。
volatile read/volatile write操作表示的是对volatile字段的读写。由于这些操作并不是通过缓存来执行的,所以通过volatile read读取到的值一定是最新的值,通过volatile write写入的值也会立即对其他线程可见。
lock/unlock操作是当程序中使用了synchronized关键字时进行虎池处理的操作。lock操作可以获取实例的锁,unlock操作可以释放实例的锁。
之所以在normal read/normal write操作中使用缓存,是为了提高性能。
如果这里完全不考虑缓存的存在,定义规范是“某个线程执行的写操作的结果都必须立即对其他线程可见”。那么,由于这项限制太过严格,Java编译器以及Java虚拟机的开发人员进行优化的余地就会变的非常少。
在Java内存模型中,某个线程写操作的结果对其他线程可见是有条件的。因此,Java编译器和Java虚拟机的开发人员可以在满足条件的范围内自由地进行优化。前面讲解的重排序就是一种优化。
那么,线程的写操作对其他线程可见的条件究竟是什么,应该怎样编写程序才好呢?
为了便于大家理解这些内容,下面将按照顺序讲解synchronized、volatile以及final这些关键字。
synchronized
synchronized具有“线程的互斥处理”和“同步处理”两种功能。
线程的互斥处理
如果程序中有synchronized关键字,线程就会进行lock/unlock操作。线程会在synchronized开始时获取锁,在synchronized终止时释放锁。
进行lock/unlock的部分并不仅仅是程序中写有synchronized的部分。当线程wait方法内部等待的时候也会释放锁。此外,当线程从wait方法中出来的时候还必须重新获取锁后才能继续进行。
只有一个线程能够获取某个实例的锁。因此,当线程A正准备获取锁时,如果其他线程已经获取了锁,那么线程A就会进入等待队列。这样就实现了线程的互斥(mutal exclusion)。
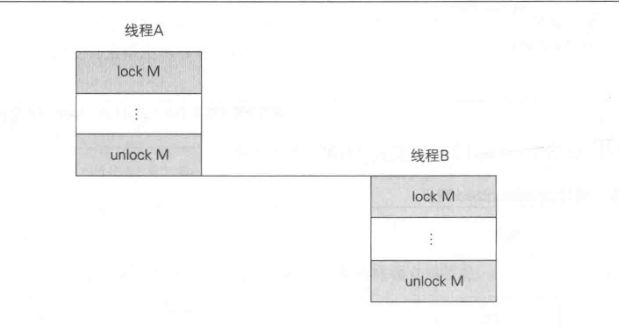
synchronized的互斥处理如下图所示,当线程A执行了unlock操作但是还没有从中出来时,线程B就无法执行lock操作。图中的unlock M和lock M中都写了一个M,这表示unlock操作和lock操作是对同一个实例的监视器进行的操作。
同步处理
synchronized(lock/unlock操作)并不仅仅进行线程的互斥处理。Java内存模型确保了某个线程在进行unlock M操作前进行的所有写入操作对进行lock M操作的线程都是可见的。
下面,我们使用示例程序3进行说明,将示例程序1中的write和read修改为synchronized方法,这是一段能够正确地进行同步的程序,绝对不可能显示出x < y。
class Something {
private int x = 0;
private int y = 0;
public synchronized void write() {
x = 100;
y = 50;
}
public synchronized void read() {
if(x < y) {
System.out.println("x < y");
}
}
}
public class Main {
public static void main(String[] args) {
final Something obj = new Something();
// 写数据的线程A
new Thread() {
public void run() {
obj.write();
}
}.start();
// 读数据的线程B
new Thread() {
public void run() {
obj.read();
}
}.start();
}
}
通过synchronized进行同步的情形如下图所示:
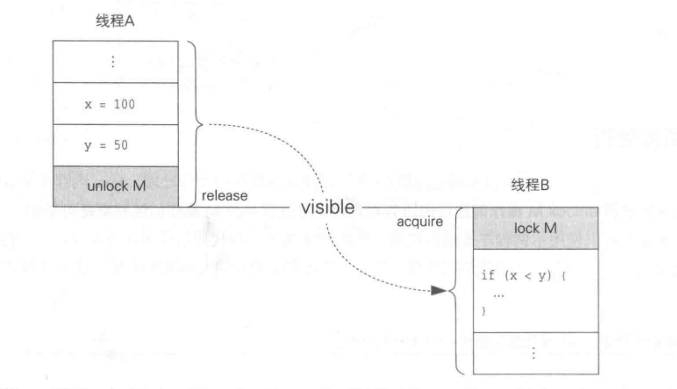
在进行如下操作时,线程A的写操作对线程B是可见的。
- 线程A对字段x和y写值(normal write操作)
- 线程A进行unlock操作
- 线程B对同一个监视器M进行lock操作
- 线程B读取字段x和y的值(normal read)
大体来说就是:
- 进行unlock操作后,写入缓存的内容会被强制的写入到共享内存中
- 进行lock操作后,缓存中的内容会先失效,然后共享内存中的最新内容会被强制重新读取到缓存中
在示例程序3中不可能显示出x < y的原因有以下两个:
- 互斥处理可以防止read方法中断write方法的处理。虽然在write方法内部会发生重排序,但是该重排序不会对read方法产生任何影响。
- 同步处理可以确保write方法向字段x、y写入的值对运行read方法的线程B是可见的。
上图中的release和acquire表示进行同步处理的两端(synchronized-with edge)。unlock操作是一种release,lock操作是一种acquire。Java内存模型可以确保处理是按照“release终止后对应的acquire才开始”的顺序进行的。
总结起来就是。只要用synchronized保护会被多个线程读写的共享字段,就可以避免这些共享字段受到重排序和可见性的影响。
volatile
volatile具有“同步处理”和“对long和double的原子操作”这两种功能。
同步处理
某个线程对volatile字段进行的写操作的结果对其他线程立即可见。换言之,对volatile字段的写入处理并不会被缓存起来。
示例程序4是将示例程序2中的quit修改为volatile字段后的程序。
class Runner extends Thread {
private volatile boolean quit = false;
public void run() {
while(!quit) {
// ...
}
System.out.println("Done");
}
public void shutdown() {
quit = true;
}
}
public class Main {
public static void main(String[] args) {
Runner runner = new Runner();
// 启动线程
runner.start();
// 终止线程
runner.shutdown();
}
}
volatile字段并非只是不缓存读取和写入。如果线程A向volatile字段写入的值对线程B可见,那么之前向其他字段写入的所有值都对线程B是可见的。此外,在向volatile字段读取和写入后不会发生重排序。
示例程序5
class Something {
private int x = 0;
private volatile boolean valid = false;
public void write() {
x = 123;
valid = true;
}
public void read() {
if(valid) {
System.out.println(x);
}
}
}
public class Main {
public static void main(String[] args) {
final Something obj = new Something();
// 写数据的线程A
new Thread() {
public void run() {
obj.write();
}
}.start();
// 读数据的线程B
new Thread() {
public void run() {
obj.read();
}
}.start();
}
}
如示例程序5所示,Something类的write发方法在将非volatile字段x赋值为123后,接着又将volatile字段valid赋值为了true。
在read方法中,当valid的值为true时,显示x。
Main类的main方法会启动两个线程,写数据的线程A会调用write方法,该数据的线程B会调用read方法。示例程序5是一段可以正确地进行同步处理的程序。
由于valid是volatile字段,所以以下两条赋值语句不会被重排序。
x = 123; // [normal write] valid = true; // [normal write]
另外,下面两条语句也不会被重排序。
if(valid) { // [volatile read]
System.out.println(x); // [normal write]
}
从volatile的使用目的来看,volatile阻止重排序是理所当然的。如示例程序5所示,volatile字段多被用作判断实例是否变为了特定状态的标志。因此,当要确认volatile字段的值是否发生了变化时,必须确保非volatile的其他字段的值已经被更新了。
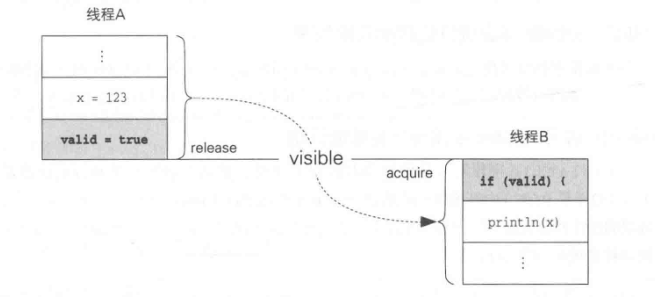
如上图所示,在进行如下处理时,线程A向x以及valid写入的值对线程B是可见的。
- 线程A向字段x写值(normal write)
- 线程A向volatile字段valid写值(volatile write)
- 线程B读取volatile字段valid的值(volatile read)
- 线程B读取字段x的值(normal read)
对long和double的原子操作
Java规范无法确保对long和double的赋值操作的原子性。但是,即使是long和double的字段,只要它是volatile字段,就可以确保赋值操作的原子性。
指南:使用synchronized或volatile来保护在多个线程之间共享的字段
final
final字段与构建线程安全的实例
使用final关键字声明的字段只能被初始化一次。final字段在创建不允许被改变的对象时起到了非常重要的作用。
final字段的初始化只能在“字段声明时”或是“构造函数中”进行。那么,当final字段的初始化结束后,无论在任何时候,它的值对其他线程都是可见的。Java内存模型可以确保被初始化后的final字段在构造函数的处理结束后是可见的。也就是说,可以确保一下事情:
-
如果构造函数的处理结束了
- final字段初始化后的值对所有线程都是可见的
- 在final字段可以追溯到的所有范围内都可以看到正确的值
-
在构造函数的处理结束前
- 可能会看到final字段的值是默认的初始值(0、false或是null)
指南:将常量字段设置为final
Java内存模型可以确保final字段在构造函数执行结束后可以正确的被看到。这样就不再需要通过synchronized和volatile进行同步了。因此,请将不希望被改变的字段设为final。
指南:不要从构造函数中泄露this
在构造函数中执行结束前,我们可能会看到final字段的值发生变化。也就是说,存在首先看到“默认初始值”,然后看到“显式地初始化的值”的可能性。
下面来看示例程序6,有一个final字段x的一个静态字段last。
在构造函数中,final字段x被显式地初始化为了123,而静态字段last中保存的则是this,我们可以理解为将最后创建的实例保存在了last中。
在静态方法print中,如果静态字段last部位null(即现在实例已经创建完成了),这个实例的final字段的值就会显示出来。
Main类的main方法会启动两个线程。线程A会创建Something类的实例,而线程B则会调用Something.print方法来显示final字段的值。
这里的问题是,运行程序后会显示出0吗?
class Something {
// final的实例字段
private final int x;
// 静态字段
private static Something last = null;
// 构造函数
public Something() {
// 显式的初始化final字段
x = 123;
// 在静态字段中保存正在创建中的实例(this)
last = this;
}
// 通过last显式final字段的值
public static void print() {
if(last !=null) {
System.out.println(last.x);
}
}
}
public class Main {
public static void main(String[] args) {
final Something obj = new Something();
// 写数据的线程A
new Thread() {
public void run() {
new Something();
}
}.start();
// 读数据的线程B
new Thread() {
public void run() {
Something.print();
}
}.start();
}
}
我们并没有使用synchronized和volatile对线程Ahead线程B进行同步,因此不知道它们会按照怎样的顺序执行。所以,我们必须考虑各种情况。
如果线程B在执行print方法时,看到last的值为null,那么if语句中的条件就会变成false,该程序什么都不会显示。
那么如果线程B在执行print方法时,看到last的值不是null会怎样呢?last.x的值一定是123吗?答案是否定的。根据Java内存模型,这时看到的last.x的值也可能会是0.因为线程B在print方法中看到的last的值,是在构造函数处理结束前获取的this。
Java内存模型可以确保构造函数处理结束时final字段的值被正确的初始化,对其他线程是可见的。总而言之,如果使用通过new Something()获取的实例,final字段是不会发生可见性问题的。但是,如果在构造函数的处理过程中this还没有创建完毕,就无法确保final字段的正确的值对其他线程是可见的。
如下面实例代码7这样修改后,就不可能会显示出0了。修改如下:
- 将构造函数修改为private,让外部无法调用
- 编写一个名为create的静态方法,在其中使用new关键字创建实例
- 将静态字段last赋值为上面使用new关键字创建的实例
这样修改后,只有当那个构造函数处理结束后静态字段last才会被赋值,因此可以确保final字段被正确的初始化。
class Something {
// final的实例字段
private final int x;
// 静态字段
private static Something last = null;
// 构造函数
public Something() {
// 显式的初始化final字段
x = 123;
}
// 将使用new关键字创建的实例赋值给this
publicstatic Something create() {
last = new Something();
return last;
}
// 通过last显式final字段的值
public static void print() {
if(last !=null) {
System.out.println(last.x);
}
}
}
public class Main {
public static void main(String[] args) {
final Something obj = new Something();
// 写数据的线程A
new Thread() {
public void run() {
Something.create();
}
}.start();
// 读数据的线程B
new Thread() {
public void run() {
Something.print();
}
}.start();
}
}
通过上面可以知道,在构造函数中将静态字段赋值为this是非常危险的。因为其他线程可能会通过这个静态字段访问正在创建中的实例。同样的,向静态字段保存的数组和集合中保存的this也是非常危险的。
另外,在构造函数中进行方法调用时,以this为参数的方法调用也是非常危险的。因为该方法可能会将this放在其他线程可以访问到的地方。
Double-Checked Locking模式的危险性
Double-Checked Locking模式原本适用于改善Single Threaded Execution模式的性能的方法之一,也被称为test-and-test-and-set。
不过,在Java中使用Double-Checked Locking模式是很危险的。
示例程序
我们实现一个具有以下特性的MySystem类。
- MySystem类的实例是唯一的
- 可以通过静态方法getInstance获取MySystem类的实例
- MySystem类的实例中有一个字段(date)是java.util.Date类的实例。它的值是创建MySystem类的实例的时间
- 可以通过MySystem类的实例方法getDate获取date字段的值
我们会采取三种方式来实现上述MySystem类:
- Single Threaded Execution模式
- Double-Checked Locking模式
- Initialization On Demand Holder模式
实现方式1:Single Threaded Execution模式
考虑到可能会有多个线程访问getInstance方法,我们将getInstance方法定义为了synchronized方法。由于instance字段被synchronized保护着,所以即使多个线程调用getInstance方法,也可以确保MySystem类的实例是唯一的。
程序虽然与我们的要求一致,但是getInstance是synchronized的,因此性能并不好。
import java.util.Date;
public class MySystem {
private static MySystem instance = null;
private Date date = new Date();
private MySystem() {
}
public Date gteDate() {
return date;
}
public static synchronized MySystem getInstance() {
if(instance == null) {
instance = new MySystem();
}
return instance;
}
}
实现方式2:Double-Checked Locking模式
Double-Checked Locking模式是用于改善实现方式1中的性能问题的模式。
getInstance方法不再是synchronized方法。取而代之的时if语句中编写的一段synchronized代码块。
// X无法确保能够正确地运行
import java.util.Date;
public class MySystem {
private static MySystem instance = null;
private Date date = new Date();
private MySystem() {
}
public Date gteDate() {
return date;
}
public static synchronized MySystem getInstance() {
if(instance == null) { // (a)第一次test
synchronized(MySystem.class) { // (b)进入synchronized代码块
if(instance == null) { // (c)第二次test
instance = new MySystem();// (d) set
}
} // (e)退出synchronized代码块
}
return instance; // (f)
}
}
下图解释了为什么上述代码可能会无法正确的运行。

注意上图中的(A-4),这里写着“在(d)处创建MySystem的实例并将其赋值给instance字段”,即代码中的以下部分:
instance = new MySystem();
这里创建了一个MySystem的实例。在创建MySystem的实例时,new Date()的值会被赋给实例字段date。如果线程A从synchronized代码块退出后,线程B才进入synchronized代码块,那么线程B也可以看见date的值。但是在(A-4)这个阶段,我们无法确保线程B可以看见线程A写入date字段的值。
接下来,我们再假设线程B在(B-1)这个阶段的判断结果是instance != null。这样的话,线程B将不进入synchronized代码块,而是立即将instance的值作为返回值return出来。这之后,线程B会在(B-3)这个阶段调用getInstance的返回值的getDate方法。getDate方法的返回值就是date字段的值,因线程B会引用date字段的值。但是,线程A还没有从synchronized代码块中退出,线程B也没有进入synchronized代码块。因此,我们无法确保date字段的值对线程B可见。
实现方式3:Initialization On Demand Holder模式
Initialization On Demand Holder模式既不会像Single Threaded Execution模式那样降低性能,也不会带来像Double-Checked Locking模式那样的危险性。
Holder类是MySystem的嵌套类,有一个静态字段instance,并使用new MySystem()来初始化该字段。
MySystem类的静态方法getInstance的返回值是Holder.instance。
这段程序会使用Holder的“类的初始化”来创建唯一的实例,并确保线程安全。
我们使用了嵌套类的延迟初始化(lazy initialization)。Holder类的初始化在线程刚刚要使用该类时才会开始进行。也就是说,在调用MySystem.getInsta方法前,Holder类不会被初始化,甚至连MySystem的实例都不会创建。因此,使用该模式可以避免内存浪费。
import java.util.Date;
public class MySystem {
private static class Holder {
public static MySystem instance = new MySystem();
}
private Date date = new Date();
private MySystem() {
}
public Date getDate() {
return date;
}
public static MySystem getInstance() {
return Holder.instance;
}
}
很遗憾的说,推酷将在这个月底关闭。人生海海,几度秋凉,感谢那些有你的时光。
原文 https://segmentfault.com/a/1190000023309613正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

