Java Lambda表达式知多少
1. 匿名内部类实现
匿名内部类仍然是一个类,只是不需要程序员显示指定类名,编译器会自动为该类取名。因此如果有如下形式的代码,编译之后将会产生两个class文件:
public class MainAnonymousClass {
public static void main(String[] args) {
new Thread(new Runnable(){
@Override
public void run(){
System.out.println("Anonymous Class Thread run()");
}
}).start();;
}
}
编译之后文件分布如下,两个class文件分别是主类和匿名内部类产生的:
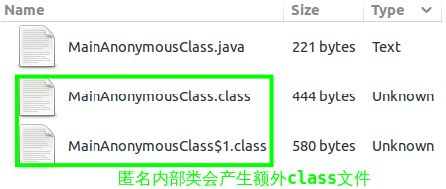
进一步分析主类MainAnonymousClass.class的字节码,可发现其创建了匿名内部类的对象:
// javap -c MainAnonymousClass.class
public class MainAnonymousClass {
...
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/Thread
3: dup
4: new #3 // class MainAnonymousClass$1 /*创建内部类对象*/
7: dup
8: invokespecial #4 // Method MainAnonymousClass$1."<init>":()V
11: invokespecial #5 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
14: invokevirtual #6 // Method java/lang/Thread.start:()V
17: return
}
2. Lambda表达式实现
Lambda表达式通过 invokedynamic 指令实现,书写Lambda表达式不会产生新的类 。如果有如下代码,编译之后只有一个class文件:
public class MainLambda {
public static void main(String[] args) {
new Thread(
() -> System.out.println("Lambda Thread run()")
).start();;
}
}
编译之后的结果:
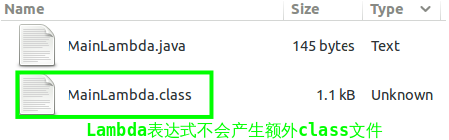
通过javap反编译命名,我们更能看出Lambda表达式内部表示的不同:
// javap -c -p MainLambda.class
public class MainLambda {
...
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/Thread
3: dup
4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable; /*使用invokedynamic指令调用*/
9: invokespecial #4 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
12: invokevirtual #5 // Method java/lang/Thread.start:()V
15: return
private static void lambda$main$0(); /*Lambda表达式被封装成主类的私有方法*/
Code:
0: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #7 // String Lambda Thread run()
5: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}
反编译之后我们发现Lambda表达式被封装成了主类的一个私有方法,并通过 invokedynamic 指令进行调用。
3. Streams API(I)
你可能没意识到Java对函数式编程的重视程度,看看Java 8加入函数式编程扩充多少功能就清楚了。Java 8之所以费这么大功夫引入函数式编程,原因有二:
- 代码简洁 函数式编程写出的代码简洁且意图明确,使用 stream 接口让你从此告别 for 循环。
-
多核友好
,Java函数式编程使得编写并行程序从未如此简单,你需要的全部就是调用一下
parallel()方法。
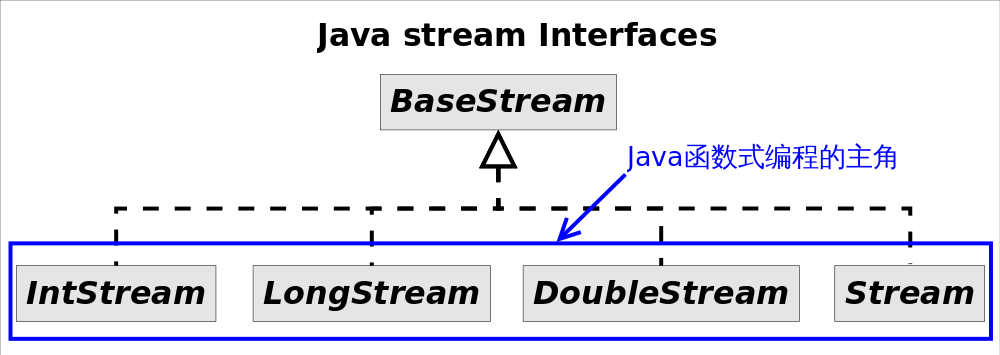
图中4种 stream
接口继承自 BaseStream
,其中 IntStream, LongStream, DoubleStream
对应三种基本类型( int, long, double
,注意不是包装类型), Stream
对应所有剩余类型的 stream
视图。为不同数据类型设置不同 stream
接口,可以1.提高性能,2.增加特定接口函数。
虽然大部分情况下 stream
是容器调用 Collection.stream()
方法得到的,但 stream
和 collections
有以下不同:
- 无存储 。 stream 不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生 。对 stream 的任何修改都不会修改背后的数据源,比如对 stream 执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新 stream 。
- 惰式执行 。 stream 上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性 。 stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
对 stream 的操作分为为两类, 中间操作( intermediate operations )和结束操作( terminal operations ) ,二者特点是:
- 中间操作总是会惰式执行 ,调用中间操作只会生成一个标记了该操作的新 stream ,仅此而已。
- 结束操作会触发实际计算 ,计算发生时会把所有中间操作积攒的操作以 pipeline 的方式执行,这样可以减少迭代次数。计算完成之后 stream 就会失效。
如果你熟悉Apache Spark RDD,对 stream 的这个特点应该不陌生。
下表汇总了 Stream
接口的部分常见方法:
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为 stream 的大都是中间操作,否则是结束操作。
flatMap()
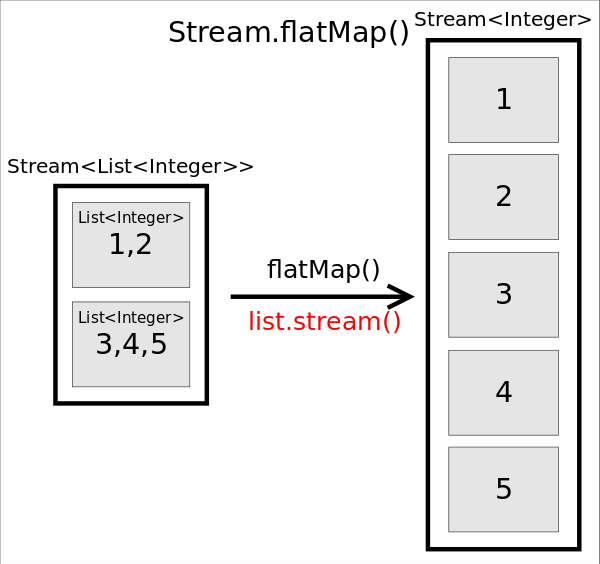
函数原型为 <R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper)
,作用是对每个元素执行 mapper
指定的操作,并用所有 mapper
返回的 Stream
中的元素组成一个新的 Stream
作为最终返回结果。说起来太拗口,通俗的讲 flatMap()
的作用就相当于把原 stream
中的所有元素都”摊平”之后组成的 Stream
,转换前后元素的个数和类型都可能会改变。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
上述代码中,原来的 stream
中有两个元素,分别是两个 List<Integer>
,执行 flatMap()
之后,将每个 List
都“摊平”成了一个个的数字,所以会新产生一个由5个数字组成的 Stream
。所以最终将输出1~5这5个数字。
截止到目前我们感觉良好,已介绍 Stream
接口函数理解起来并不费劲儿。如果你就此以为函数式编程不过如此,恐怕是高兴地太早了。下一节对 Stream
规约操作的介绍将刷新你现在的认识。
多面手reduce()
reduce
操作可以实现从一组元素中生成一个值, sum()
、 max()
、 min()
、 count()
等都是 reduce
操作,将他们单独设为函数只是因为常用。 reduce()
的方法定义有三种重写形式:
Optional<T> reduce(BinaryOperator<T> accumulator) T reduce(T identity, BinaryOperator<T> accumulator) <U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
虽然函数定义越来越长,但语义不曾改变,多的参数只是为了指明初始值(参数 identity
),或者是指定并行执行时多个部分结果的合并方式(参数 combiner
)。 reduce()
最常用的场景就是从一堆值中生成一个值。用这么复杂的函数去求一个最大或最小值,你是不是觉得设计者有病。其实不然,因为“大”和“小”或者“求和”有时会有不同的语义。
需求: 从一组单词中找出最长的单词 。这里“大”的含义就是“长”。
// 找出最长的单词
Stream<String> stream = Stream.of("I", "love", "you", "too");
Optional<String> longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
//Optional<String> longest = stream.max((s1, s2) -> s1.length()-s2.length());
System.out.println(longest.get());
上述代码会选出最长的单词 love
,其中 Optional
是(一个)值的容器,使用它可以避免 null
值的麻烦。当然可以使用 Stream.max(Comparator<? super T> comparator)
方法来达到同等效果,但 reduce()
自有其存在的理由。

需求: 求出一组单词的长度之和 。这是个“求和”操作,操作对象输入类型是 String ,而结果类型是 Integer 。
// 求单词长度之和
Stream<String> stream = Stream.of("I", "love", "you", "too");
Integer lengthSum = stream.reduce(0, // 初始值 // (1)
(sum, str) -> sum+str.length(), // 累加器 // (2)
(a, b) -> a+b); // 部分和拼接器,并行执行时才会用到 // (3)
// int lengthSum = stream.mapToInt(str -> str.length()).sum();
System.out.println(lengthSum);
上述代码标号(2)处将i. 字符串映射成长度,ii. 并和当前累加和相加。这显然是两步操作,使用 reduce()
函数将这两步合二为一,更有助于提升性能。如果想要使用 map()
和 sum()
组合来达到上述目的,也是可以的。
reduce()
擅长的是生成一个值,如果想要从 Stream
生成一个集合或者 Map
等复杂的对象该怎么办呢?终极武器 collect()
横空出世!
终极武器collect()
不夸张的讲,如果你发现某个功能在 Stream
接口中没找到,十有八九可以通过 collect()
方法实现。 collect()
是 Stream
接口方法中最灵活的一个,学会它才算真正入门Java函数式编程。先看几个热身的小例子:
// 将Stream转换成容器或Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1)
// Set<String> set = stream.collect(Collectors.toSet()); // (2)
// Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length)); // (3)
上述代码分别列举了如何将 Stream 转换成 List 、 Set 和 Map 。虽然代码语义很明确,可是我们仍然会有几个疑问:
-
Function.identity()是干什么的? -
String::length是什么意思? - Collectors 是个什么东西?
接口的静态方法和默认方法
Function是一个接口,那么 Function.identity()
是什么意思呢?这要从两方面解释:
-
Java 8允许在接口中加入具体方法。接口中的具体方法有两种, default
方法和 static
方法,
identity()就是 Function 接口的一个静态方法。 -
Function.identity()返回一个输出跟输入一样的Lambda表达式对象,等价于形如t -> t形式的Lambda表达式。
上面的解释是不是让你疑问更多?不要问我为什么接口中可以有具体方法,也不要告诉我你觉得 t -> t
比 identity()
方法更直观。我会告诉你接口中的 default
方法是一个无奈之举,在Java 7及之前要想在定义好的接口中加入新的抽象方法是很困难甚至不可能的,因为所有实现了该接口的类都要重新实现。试想在 Collection
接口中加入一个 stream()
抽象方法会怎样? default
方法就是用来解决这个尴尬问题的,直接在接口中实现新加入的方法。既然已经引入了 default
方法,为何不再加入 static
方法来避免专门的工具类呢!
方法引用
诸如 String::length
的语法形式叫做方法引用( method references
),这种语法用来替代某些特定形式Lambda表达式。如果Lambda表达式的全部内容就是调用一个已有的方法,那么可以用方法引用来替代Lambda表达式。方法引用可以细分为四类:
| 方法引用类别 | 举例 |
|---|---|
| 引用静态方法 |
Integer::sum
|
| 引用某个对象的方法 |
list::add
|
| 引用某个类的方法 |
String::length
|
| 引用构造方法 |
HashMap::new
|
我们会在后面的例子中使用方法引用。
收集器
相信前面繁琐的内容已彻底打消了你学习Java函数式编程的热情,不过很遗憾,下面的内容更繁琐。但这不能怪Stream类库,因为要实现的功能本身很复杂。
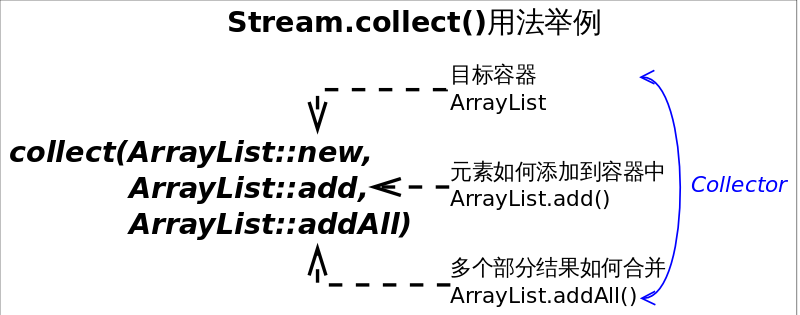
收集器( Collector
)是为 Stream.collect()
方法量身打造的工具接口(类)。考虑一下将一个 Stream
转换成一个容器(或者 Map
)需要做哪些工作?我们至少需要两样东西:
- 目标容器是什么?是 ArrayList 还是 HashSet ,或者是个 TreeMap 。
-
新元素如何添加到容器中?是
List.add()还是Map.put()。
如果并行的进行规约,还需要告诉 collect() 3. 多个部分结果如何合并成一个。
结合以上分析, collect()
方法定义为 <R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner)
,三个参数依次对应上述三条分析。不过每次调用 collect()
都要传入这三个参数太麻烦,收集器 Collector
就是对这三个参数的简单封装,所以 collect()
的另一定义为 <R,A> R collect(Collector<? super T,A,R> collector)
。 Collectors
工具类可通过静态方法生成各种常用的 Collector
。举例来说,如果要将 Stream
规约成 List
可以通过如下两种方式实现:
https://objcoding.com/2019/03...
本篇文章由一文多发平台 ArtiPub 自动发布
正文到此结束
- 本文标签: entity id HashSet mina map 程序员 Collection stream remote 功夫 App src IO lambda tab cat CTO dist mapper 构造方法 编译 find 需求 consumer 函数式编程 静态方法 apache tar 代码 参数 文章 字节码 java API list 删除 ArrayList rmi https IDE Collections http HashMap 2019 ip 数据 遍历
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

