就因为没看这篇文章面试失败了
前言
熬夜整理了一份java基础面试题,希望大家支持,如果文中有错误希望大家指正;
公众号:知识追寻者
知识追寻者(Inheriting the spirit of open source, Spreading technology knowledge;)
一 java基础面试
1.1面向对象和面向过程的区别
- 面向过程:
优点: 性能比面向对象高 ,因为类调用时需要实例化,开销比较大,比较消耗 资源
应用场景:单片机、嵌入式开发、Linux/Unix ;
缺点:没有面向对象易维护、易复用、易扩展
- 面向对象
优点:因为面向对象有封装、继承、多态性的特 性,可以设计出低耦合的系统,故易维护、易复用、易扩展;
应用场景:网页开发,后台开发等;
缺点:性能比面向过程低
1.2 面向对象的特性
- 封装 : 将一个对象的属性私有化,并提供一个对外访问的方法;
- 继承 :在已有类的基础上建立新类;提供继承信息的类被称为父类(超类、基类);得到继 承信息的类被称为子类(派生类)
- 多态 :一个对象的多种表现形态;用同样的对象引用调用同样的方法但是做了不同的事情;可以向上转型和向下转型
多态实现形式:
重写:子类对父类方法的重写;
覆盖:实现接口,并覆盖方法;
1.3 抽象
抽象是指将对象抽象为具体类的过程;抽象只关注对象有哪些属性和行为(方法);
1.4 Java语言特点
- 简单易学;
- 面向对象(封装,继承,多态);
- 跨平台(Java虚拟机实现平台无关性);
- 可靠性;
- 安全性;
- 支持多线程
- 支持编译与解释;
- 支持网络编程
1.5 JDK,JRE,JVM之间的区别
JDK: java开发工具包;包含JRE, javac等调优诊断工具;能够创建和编译程序;
JRE: java运行环境; 包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件;不能创建程序;
JVM:java虚拟机,提供运行字节码文件(.class)的环境支持;
jdk 包含jre ; jre 包含 jvm
1.6 面向对象五大基本原则
- 单一职责原则SRP(Single Responsibility Principle);设计类时要功能单一;
- 开放封闭原则OCP(Open-Close Principle);一个模块对于拓展是开放的,对于修改是封闭;
- 里式替换原则LSP(the Liskov Substitution Principle LSP);子类可以替换父类;
- 依赖倒置原则DIP(the Dependency Inversion Principle DIP);高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象;
- 接口分离原则ISP(the Interface Segregation Principle ISP);设计类时,功能接口拆分为多个;
开发设计类时需考虑的事情,面试中如果碰见能答几个就几个;
1.7 什么是java主类
java主类是java代码运行的入口,即包含 main方法的类;
1.8 构造器能否被重写
子类无法继承父类的构造器,所以构造器不能被重写(overidde),但可以被重载(overload);
1.9 重载和重写的区别
重写 :
-
发生在父类与子类之间
-
方法名,参数列表,必须相同,返回值小于等于父类;
-
访问修饰符大于等于父类(public>protected>default>private);父类方法为private,则无法重写;
-
重抛出异常的范围要小于等于父类异常;
重载 :
- 发生在同一个类中
- 方法名相同参数列表不同(参数类型不同、个数不同、顺序不同);
- 方法返回值和访问修饰符可以不同;
1.10 equals与==的区别
==: 判定是否是相同一个对象 ,比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,;
equals: equals用来比较的是两个对象的内容是否相等; 但Object中的equals方法返回的却是==的判断 ;
1.11什么是hashCode
hashCode() 的作用是获取哈希码,也称为散列码;它实际上一个int整数;哈希码的作用是确定该对象在哈希表中的索引位置;散列表存储的是键值对(key-value),即能根据键获取值;
当一个对象插入散列表时先会比较对象与散列表中已有的对象hash值,若不同,则直接插入散列表,若相同(hash碰撞),则会调用equals 方法检查是否真的相同, 如果equal()判断不相等,直接将该元素放入集合中,否则不放入;
对象中hashCode()与equals()的关系
- 如果两个对象相等,则hashcode也相等;
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们不一定是同一个对象;
- equals 方法被覆盖过,则 hashCode 方法也必须被覆盖;
1.12 什么是值传递和引用传递
值传递:传递了对象的一个副本,即使副本被改变,也不会影响源对象;
引用传递:着传递的并不是实际的对象,而是对象的引用;对外部对象的改变会反映到实际对象;
一般认为,Java 内的传递都是值传递,Java 中实例对象的传递是引用传递;
1.13 什么是抽象类与接口
-
抽象类是对类的抽象,是一种模板设计; 而接口是行为的抽象,可以理解为行为的规范;
-
抽象类中可以包含非抽象方法;而接口是绝对的抽象方法;
-
接口默认是public 方法,java8中接口支持默认(default)方法;
-
一个类可以实现多个接口,但只能实现一个抽象类;
-
抽象类不能使用final修饰(final修饰的类为固定类,无法被继承)
1.14String、String StringBuffer 和 StringBuilder 的区别
- String是只读字符串,并不是基本数据类型,而是一个对象;其无法改变;每次操作都会产生新对象;
- StringBuilder 并没有对方法进行加同步锁,线程不安全;
- StringBuffer 对方法加了同步锁,线程安全;
tip: 数据量少的时候使用 String; 单线程使用StringBuilder ; 多线程使用 StringBuffer ; 使用StringBuilder 性能比 StringBuffer 性能 提升大概有 10%~15%;
1.15 用最有效率的方法计算 2 乘以 8
2 << 3 = 8 ; 2 左移3位
1.16 & 与 && 的区别
& 运算符 按位与;
&& 运算符是短路与:&& 左边的表达式的值是 false,右边的表达式会被直接短路掉,不会进行运算
1.17 static 关键字
static 变量在 Java 中属于类的,它在所有的实例中具有相同的值。当类被 Java 虚拟机载入的时候,会对 static 变量进行初始化;故需要用实例来访问 static 变量;
1.18 Java 支持的数据类型
- 整数值型:byte,short,int,long;
- 字符型:char;
- 浮点类型:float,double;
- 布尔型:boolean;
| 类型 | 位数 | 字节数 |
|---|---|---|
| short | 2 | 16 |
| int | 4 | 32 |
| long | 8 | 64 |
| float | 4 | 32 |
| double | 8 | 64 |
| char | 2 | 16 |
1.19 final, finally, finalize 的区别
- final:用于声明属性,方法和类, 分别表示属性不可变, 方法不可覆盖, 类不可继承.
- finally:异常处理语句结构的一部分,表示最后总是会执行.
- finalize:Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法;
1.20 instanceof 关键字
instanceof 严格来说是Java中的一个双目运算符,用来检查一个对象是否为一个类的实例;
1.21 为什么不能用浮点型表示金额
浮点数为非精确值,应该使用BigDecimal来修饰金额;
1.22 自动装箱与拆箱
- 装箱:自动将基本数据类型转换为包装器类型,调用 Integer的valueOf(int) 方法;
- 拆箱:自动将包装器类型转换为基本数据类型。调用Integer的intValue方法
tip: int 是基础数据类型,占用空间小; Integer 是对象占用空间大;
1.23 switch中能否使用string做参数
在idk 1.7之前,switch只能支持byte, short, char, int或者其对应的封装类以及Enum类型。从idk 1.7之后switch开始支持String。
可以用在byte上,但是不能用在long上。
1.24 java 创建对象的几种方式
- 采用new
- 通过反射
- 采用clone
- 通过序列化机制
1.25 如何将byte转为String
可以使用 String 接收 byte[] 参数的构造器来进行转换, 但编码必须正确;
1.26 final有哪些用法
1.被final修饰的类不可以被继承
2.被final修饰的方法不可以被重写
3.被final修饰的变量不可以被改变。
5.被final修饰的常量,在编译阶段会存入常量池中。
1.27 java当中的四种引用
- 强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象。
- 软引用:在使用软引用时,如果内存的空间足够,软引用就能继续被使用,而不会被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收。
- 弱引用:具有弱引用的对象拥有的生命周期更短暂。因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。
- 虚引用:如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收。
1.28 Math. round(-1. 5) 等于多少?
Math.round(-1.5)的返回值是-1。四舍五入的原理是在参数上加0.5然后做向下取整
1.29 String str="i"与 String str=new String("i")一样吗?
tring str="i"的方式,Java 虚拟机会将其分配到常量池中;而 String str=new String("i") 则会被分到堆内存中;所以一个是常量,一个是对象,不一样;
1.30char 型变量中能不能存储一个中文汉字
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode,一个 char 类型占 2 个字节,所以能放一个中文。
1.31 break 和 continue 的区别
- break 跳出整个循环。
- continue 用于跳过本次循环,执行下次循环。
1.32 内部类与静态内部类的区别
内部类:
1、内部类中的变量和方法不能声明为静态。
2、内部类实例化:B是A的内部类,实例化B: A.B b = new A().new B() 。
3、内部类可以引用外部类的静态或者非静态属性及方法。
静态内部类:
1、静态内部类属性和方法可以声明为静态的或者非静态的。
2、实例化静态内部类:B是A的静态内部类, A.B b = new A.B() 。
3、静态内部类只能引用外部类的静态的属性及方法。
1.33 throw和throws的区别?
- throw用于主动抛出java.lang.Throwable 类的一个实例化对象,即通过关键字 throw 抛出一个 Error 或者 一个Exception;
- throws 的作用是作为方法声明和签名的一部分;
1.34 error和exception的区别
- Error类和Exception类的父类都是throwable类
- Error类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。直接终止程序即可;
- Exception类表示程序可以处理的异常,可以捕获和有可能恢复。需要程序员手动处理;
1.35 什么时候用断言(assert)
断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为true;如果表达式的值为false,那么系统会报告一个AssertionError。
断言有两种形式:
assert Expression1 assert Expression1 : Expression2
assert false; assert i == 0:"123";// 当 i不等于0 时会输出错误信息
1.36 常见的五种运行时异常
- ClassCastException(类转换异常)
- IndexOutOfBoundsException(数组越界)
- NullPointerException(空指针异常)
- ArrayStoreException(数据存储异常,操作数组是类型不一致)
- BufferOverflowException(缓存溢出异常)
二 IO流面试
2.1 序列化的含义
- 序列化:将对象写入到IO流中
- 反序列化:从IO流中恢复对象
序列化机制将序列化的Java对象转换为位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象,通常被序列化的要实现Serializable接口,并指定序列值
Externalizable 可以控制整个序列化过程,指定特定的二进制格式,增加安全机制
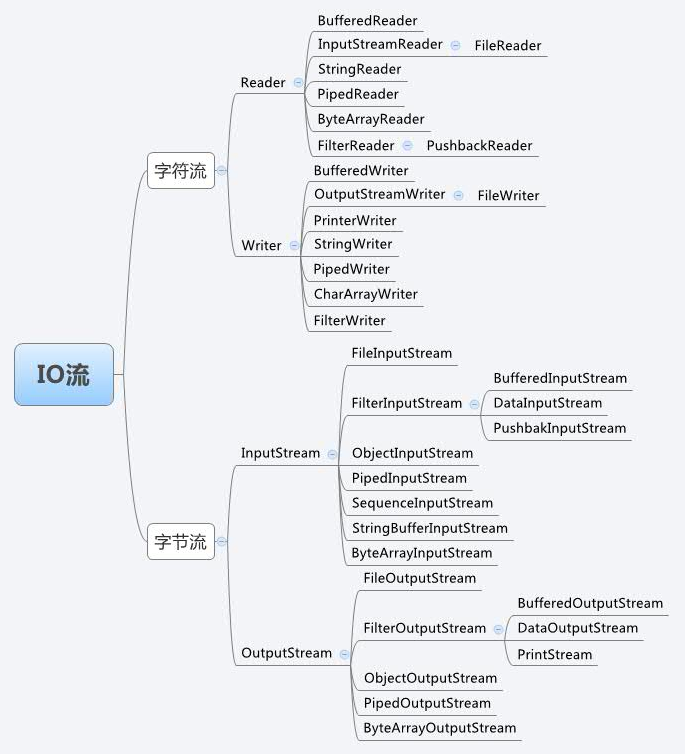
2.2 java 中 IO 流分类
-
按照流的流向分,可以分为输入流和输出流;
-
按照操作单元划分,可以划分为字节流和字符流;
-
按照流的角色划,可以分为节点流和处理流。
-
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
-
OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
图片来源网络:
2.3 BIO、NIO、AIO的区别
- BIO 就是传统的
java.io包,它是基于流模型实现的,交互的方式是同步、 阻塞方式IO ; 在读入输入流或者输出流时,在读写完成之前,线程会一直处于阻塞状态。 - NIO (New IO)是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序。
- AIO(Asynchronous IO) 是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO,异步 IO 是基于事件和回调机制实现。
三 集合面试
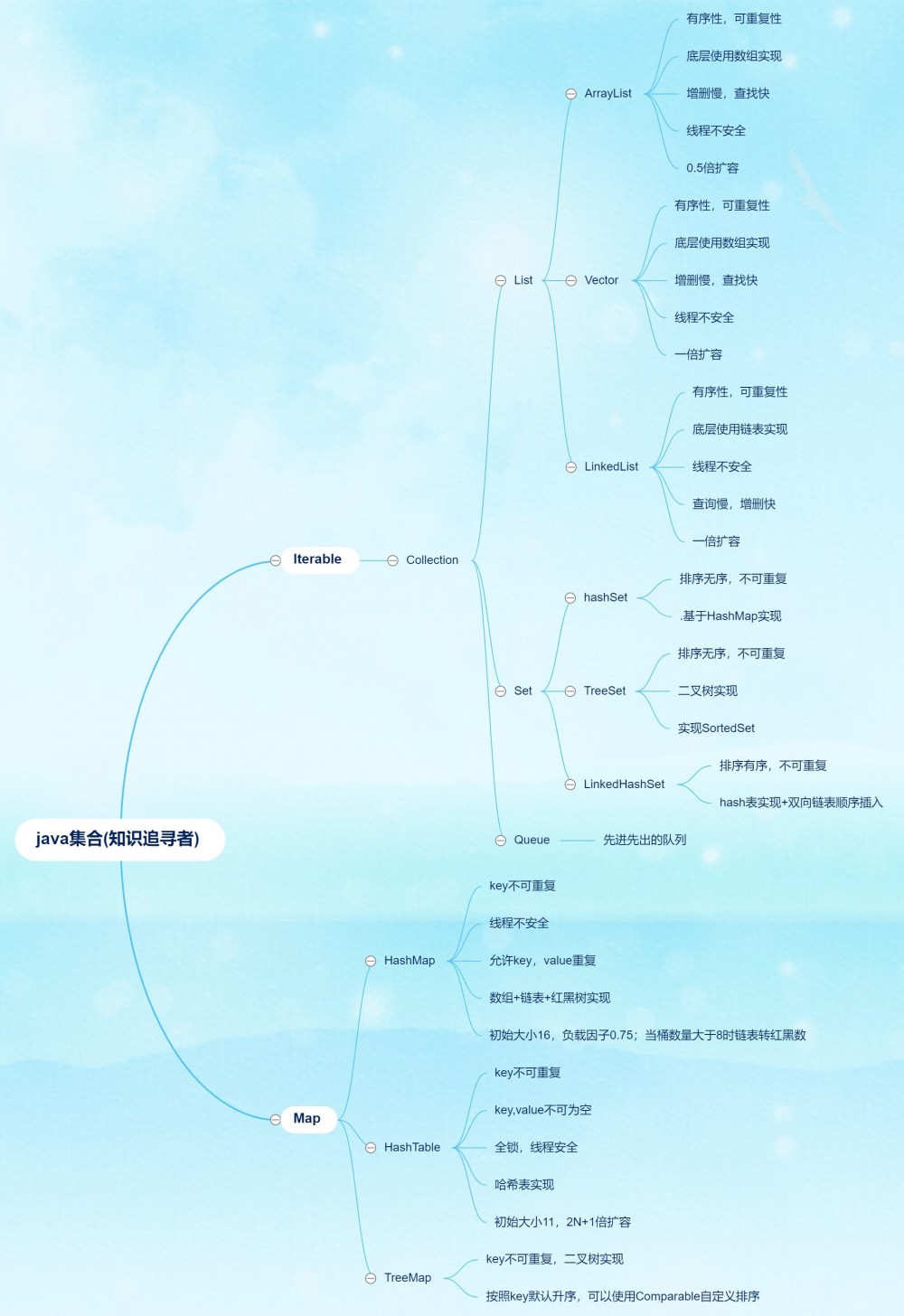
3.1 java 集合架构
3.2 Collection 和 Collections的区别
Collection:是java.uitl 下的接口,他是各种集合的父接口;
Conllecitons:是个java.util下的类,是针对集合的工具类,提供一系列静态方法对集合的搜索、查找、同步等操作;
3.3 ArrayList和Vector的区别
- 共同点:都实现了List接口,为有序的集合,底层基于数组实现,通过索引取值,允许元素重复和为null;都是实现 fail-fast机制;
- 区别:ArrayList不同步,Vector是同步(ArrayList 比 Vector 快,不会过载);Vector扩容原来的一倍,ArrayList扩容原来的0.5倍;
3.4List,Set,Map 三者的区别?
List Set Map
3.5 ArrayList,LinkedList区别
共同点:
ArrayList 和 LinkedList 都是线程不安全;
区别:
- ArrayList的底层是数组实现,LinkedList的底层是双向链表实现。
- ArrayList 通过索引获取值,查询快;LinkedList通过遍历链表获取值查询慢;
- ArrayList 增删慢,LinkedList 增删快;
3.6Enumeration和iterator接口的区别
- iterator是Enumeration接口的替代品,只提供了遍历vector和HashTable类型集合元素的功能;
- Enumeration速度是iterator的2倍,同时占用更少的内存。
- terator有fail-fast机制,比Enumeration更安全
- Iterator能够删除元素,Enumeration并不能删除元素
3.7 简述Iterator 迭代器
Iterator迭代器可以对集合进行遍历, 遍历方式都是 hasNext() 和 next() 方法,,在当前遍历集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常;
3.8 HashMap和Hashtable的区别
共同点: 都实现 Map接口;
区别:
- HashMap不同步;Hashtable同步;HashMap效率比Hashtable高;
- HashMap允许为null ;Hashtable不允许为null
- Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1,HashMap 默认的初始化大小为 16;
- HashMap 在 jdk1.8 改变了数据结构为 数组 + 链表 + 红黑树方式; HashTable使用全表锁,效率低下;
3.9HashSet 和 HashMap 的区别
- HashMap 实现了Map接口;HashSet实现了Set接口
- HashMap储存键值对;HashSet仅仅存储对象
- HashMap使用put()方法将元素放入map中;HashSet使用add()方法将元素放入set中;
- HashMap中使用键对象来计算hashcode值;ashSet使用成员对象来计算hashcode值;
- HashSet较HashMap来说比较慢;
3.10 HashMap和TreeMap区别
TreeMap实现SortMap接口,能够将记录根据键排序(默认升序排序),也可以指定排序的比较器Comparator,当用Iterator 遍历TreeMap时得到排序后的结果;
对于插入、删除和定位元素等操作,选择HashMap;如果对一个有序的key集合进行遍历,选择TreeMap
3.11 并发集合和普通集合区别
并发集合常见的有 ConcurrentHashMap 、 ConcurrentLinkedQueue 、 ConcurrentLinkedDeque 等。并发集合位于 java.util.concurrent 包下,是 jdk1.5 之后才有;其相比与普通集合添加了 synchronized 同步锁,线程安全,但效率低;
3.12 ConcurrentHashMap1.7和1.8的区别
jdk1.8的实现不再使用jdk1.7的Segment+ HashEntry分段锁机制实现,利用 Node数组 + CAS+Synchronized 来保证线程安全;底层采用 数组+链表+红黑树 的存储结构;
ConcurrentHashMap1.7
 dk1.7
dk1.7
ConcurrentHashMap1.8

3.13HashMap 的长度为什么是2的幂次方
目的是为了能让 HashMap 存取高效,尽量减少Hash碰撞,尽量使Hash算法的结果均匀分布,每个链表/红黑树长度大致相同;
算法实际是取模,hash%length,计算机中求余效率不如位移运算,源码中做了优化hash&(length-1);
hash%length==hash&(length-1)的前提是length是2的n次方
3.14 ArrayList集合如何高效加入10万条数据
直接在初始化的时候就指定ArrayList的容量值;
3.15 如何选用集合
根据集合的特点来选用集合;根据键获取值选用 Map 接口下的集合;需要排序选择 TreeMap ,不需要排序选择 HashMap ,需要线程安全选 ConcurrentHashMap 。
只存放元素值时,就选择实现 Collection 接口的集合;需要元素唯一时选择实现 Set 接口的集合,如TreeSet 或 HashSet; 不需要元素唯一性就选择实现 List 接口,如 ArrayList 或 LinkedList ;
3.16 快速失败(fail-fast)和安全失败(fail-safe)的区别是什么
-
快速失败:当你在迭代一个集合的时候,如果有另一个线程正在修改你正在访问的那个集合时,就会抛出一个 ConcurrentModification 异常。 在 java.util 包下的都是快速失败。
-
安全失败:你在迭代的时候会去底层集合做一个拷贝,所以你在修改上层集合的时候是不会受影响的,不会抛出 ConcurrentModification 异常。在java.util.concurrent 包下的全是安全失败的。
附:
HashMap 源码分析: https://blog.csdn.net/youku1327/article/details/105332136;
ArrayList源码分析https://blog.csdn.net/youku1327/article/details/105314040
tip: 需要懂 HashMap,ArrayList,LinkedList,ConcurrentHashMap底层实现原理
正文到此结束
- 本文标签: CTO HashMap list 静态方法 升级版本 http 代码 Collection Select LinkedList final 缓存 tab map 文章 CEO 模型 value 字节码 java src HashSet https SDN IO 遍历 索引 锁 AIO unix 安全 ACE 空间 id key JVM linux build 并发 ip 多线程 NIO HTML ConcurrentHashMap 开发 BIO 源码 cat 生命 基本原则 希望 Collections equals 同步 stream 占用空间 数据 图片 程序员 HashTable 参数 synchronized 编译 删除 线程 时间 垃圾回收 实例 ArrayList java基础 zab node UI queue
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

