记一次FullGC的排查经历--从FullGC日志到业务代码
问题的发生
简单介绍下我们服务的背景,我们的服务是一个使用类似dubbo的RPC框架以及若干Spring全家桶组合起来的微服务架构,大致结构可以参考下图。
Java服务使用的是CMS的垃圾回收器。
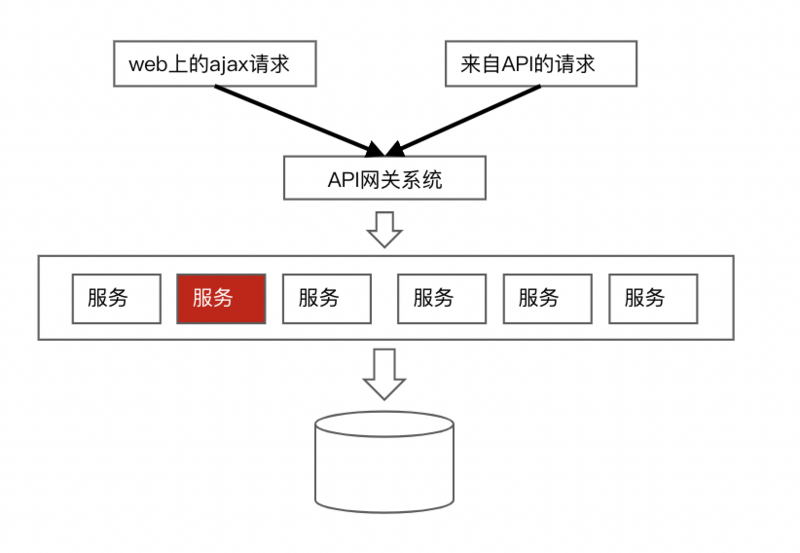
某天突然收到一台实例(即一个Java应用)产生FullGC日志的报警,如上图红色标记的服务,FullGC的日志信息如下:
2020-07-25T14:55:07.481+0800: 155286.031: [GC (CMS Initial Mark) [1 CMS-initial-mark: 13965759K(13965760K)] 16377019K(16496128K), 0.1756459 secs] [Times: user=2.53 sys=0.00, real=0.18 secs] 2020-07-25T14:55:07.657+0800: 155286.207: [CMS-concurrent-mark-start] 2020-07-25T14:55:08.507+0800: 155287.057: [Full GC (Allocation Failure) 2020-07-25T14:55:08.507+0800: 155287.057: [CMS2020-07-25T14:55:11.932+0800: 155290.482: [CMS-concurrent-mark: 4.268/4.275 secs] [Times: user=40.27 sys=1.78, real=4.27 secs] (concurrent mode failure): 13965759K->13965759K(13965760K), 18.4763209 secs] 16496127K->14470127K(16496128K), [Metaspace: 190291K->190291K(1234944K)], 18.4769704 secs] [Times: user=43.71 sys=2.18, real=18.47 secs]
可以看到,这是因为CMS老年代回收并发标记时,发现老年代内存已经不足而触发了FullGC强行
,并且由于应用虽然STW,但是请求确还是在堆积,导致一直在持续FullGC,没有自愈

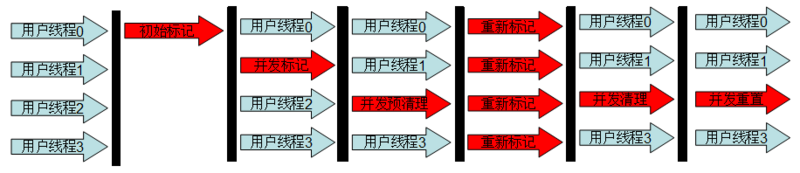
普通CMS老年代回收过程如下图所示。
止损和排查
止损
止损方式很简单,当然就是重启这个应用,在重启的时候应用会从注册中心里被摘掉,流量会被负载均衡到其它的服务上。重启一下,多喝热水。(PS:其实这里是可以有优化的空间的,例如某种机制发现服务在进行FullGC时就将其主动从注册中心中摘掉,然后待其FullGC完毕自愈后再加入到注册中心接受请求,整个过程自动完成无需人工干涉)
原因排查
问题自然要一跟到底,接下开始进行排查

为什么会FullGC?
FullGC的直接原因可能有以下几类:
- 应用中主动调用了
System.gc()
基本不可能是这个原因,首先没有人会闲得去调用这个方法,代码全局搜索后也印证了这个结果了;其次就算真的有人调用了这个 System.gc() 去 建议 JVM去支持FullGC,我们的服务在启动参数中开启了这个参数 -XX:ExplicitGCInvokesConcurrent ,这个参数的含义是将显示调用的 System.gc() 转为CMS的并发GC,所以并不会因此而触发FullGC
- 方法区(元空间)空间不足
这种一般的原因是代码中大量使用动态代理,生成了一大堆的代理类占用了方法区,如果是这个原因引起必然是所有服务都会报FullGC问题,然而其它机器的老年代内存很稳定,所以排查
- 直接内存空间不足
直接内存空间不足一般是用了nio这样的代码导致的
- 老年代空间不足
对象出生于新生代,在挺过了一次次minorGC之后成功熬到了老年代,并且持续在老年代混吃等死,一直到大量的对象都这样在老年代混吃等死把老年代占满之后就会触发FullGC
为什么只有一个实例异常
只有单个服务出现了这样的问题,很有可能不是外部依赖的超时或者方法区空间不足造成,而是因为 某个刚好落在这个服务上的超大请求 占用了大量的内存并且耗时久,一直赖在老年代不走导致。
gc日志在跟我说话
第一次FullGC发生在 2020-07-25 14:51:58 ,观察之前的日志可以发现历史上CMS并发回收一般都会将堆内存稳定在 3608329K->1344447K ,从3.6G左右回收到1.3G左右,但是从某个时间点开始开始 回收效率变差了 。
2020-07-25T14:51:50.866+0800: 155089.417: [GC (Allocation Failure) 2020-07-25T14:51:50.866+0800: 155089.417: [ParNew: 2530368K->281088K(2530368K), 0.9268687 secs] 5001197K->3500201K(16496128K), 0.9272222 secs] [Times: user=15.37 sys=1.02, real=0.92 secs]
可以看到,这次回收从5G回收到3.5G,回收完之后还有这么多被占用!这个时间点 2020-07-25 14:51:50 左右一定发生了什么事情,导致老年代一直保留着一批 老赖 。
大搜查,找出犯罪嫌疑人
定位了时间点之后,接下来的问题就是找出这个时间点附近耗时特别离谱的大请求,好在我们的服务有着详细的AOP包裹起来的请求日志,准确的记录了每个请求的相关信息,从日志中我找到了一个犯罪嫌疑人,请求参数长得离谱(一个请求修改了1000个文件夹的属性,为了隐藏公司业务逻辑以文件夹为例)。
不过光这样还不能给它定罪,因为从经验来看,这么长的请求参数其实并不罕见,可以回到第一张的结构图上看,我们的服务同时接收来自web和api两端的请求,如果是web上用户是没有这样的入口去操作1000个的,但是api的话是用户端写的代码,很有可能出现这样的请求且是正常请求(我们批量编辑的阈值刚好是1000)。
搜集证据,定罪
但是我的直觉告诉我,事情没有那么简单,我又去追查了跟这个请求相关的所有日志,发现这个修改请求查询的数据多的离谱,如果只是1000个文件夹的话,修改只需要3步:
- 根据主键id查出这1000个文件夹的属性
- 修改这1000个文件夹的属性
- 执行修改操作,提交事务
而有一个sql日志查询量大得离谱,隐藏掉业务逻辑后的形式如下:
select xxx, yyy from file where userid=123 and file_id in (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?...)
并且grep到了这个请求相关的异常栈,是执行sql超时触发的回滚异常 AbstractFallbackSQLExceptionTranslator.java ,从异常栈中找到了 查询量大的离谱的原因
还原犯罪过程
原来,业务代码中做了一个这样的逻辑,本来是修改了1000个文件夹的某个属性,但是业务逻辑是如果修改的是某个特殊属性时,会 级联修改这些文件夹下的全部文件 ,文件夹和文件的关系大致如下图
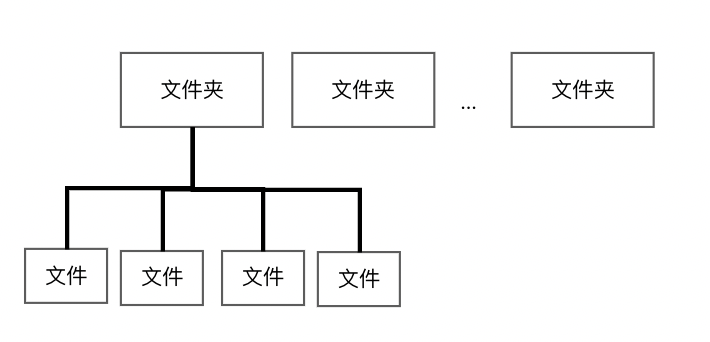
因此,实际上修改了1000个文件夹的请求,背后处理了1000个文件夹+100w个文件,而修改这些属性由于我们使用的框架的限制,100w个文件在修改前会查主属性表+所有辅属性表(内存根据主键id join),请求耗时90s,导致 大量对象 长时间 滞留在堆内存中挺过了一波波的minorGC和CMS GC干满老年代,最终触发了这个问题。
优化的思路
问题已经定位,接下来就是问题优化的思路了:
- 限制此类字段的修改,对于这样需要 级联 修改的情况时进行校验,不允许API用户传太多文件夹(1000个 --> 100个)
- 微服务的思想,在该服务上层再做一个分发服务,对于这样级联修改的请求将1000个的修改拆成10个每次修改100个的请求去并发请求下面的机器,均摊压力
- 异步化队列,修改文件夹本身属性后即立刻返回,后续级联修改的请求拆成n个放入队列,由其它服务订阅到请求后执行
- 能有监控手段在应用FullGC时从注册中心踢掉,待FullGC自愈后再加入,而不是人工干预重启
- 优化ORM框架,就算修改100w个文件的某个属性,也不需要查询出这些文件的全部属性,只查询出主表+需要修改的属性所在的表即可
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

