antlr入门
先看下面这段用于识别像hello world那样的短语的简单文法:
 以下是TestRig可用的所有参数:
以下是TestRig可用的所有参数:
grammar Hello; // 定义文法的名字
s : 'hello' ID ; // 匹配关键字hello和标志符
ID : [a-z]+ ; // 标志符由小写字母组成
WS : [ \t\r\n]+ -> skip ; // 跳过空格、制表符、回车符和换行符
$ ./antlr Hello.g
$ ls Hello*
Hello.tokens HelloLexer.interp HelloLexer.java HelloBaseListener.java Hello.g
Hello.interp HelloLexer.tokens HelloParser.java HelloListener.java
#!/bin/sh
javac -cp antlr-4.7.1-complete.jar $*
$ ./compile Hello*.java
#!/bin/sh
java -cp .:$PWD/antlr-4.7.1-complete.jar org.antlr.v4.gui.TestRig $*
$ ./grun Hello s -tokens # Hello是文法的名字。s是开始的规则名字。
hello world # 输入并按回车
EOF # Linux系统输入Ctrl+D或Windows系统输入Ctrl+Z并按回车
[@0,0:4='hello',<1>,1:0]
[@1,6:10='world',<2>,1:6]
[@2,13:12='<EOF>',<-1>,2:0]
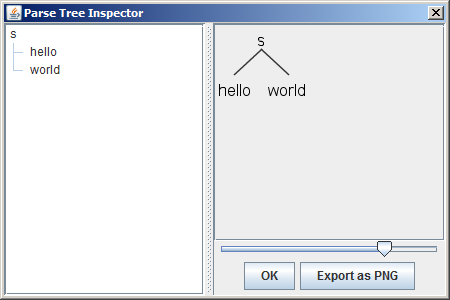
$ ./grun Hello s -tree
(s hello world)
$ ./grun Hello s -gui
- -tokens 打印出记号流。
- -tree 以LISP风格的文本形式打印出语法分析树。
- -gui 在对话框中可视化地显示语法分析树。
- -ps file.ps 在PostScript中生成一个可视化的语法分析树表示,并把它存储在file.ps文件中。
- -encoding encodingname 指定输入文件的编码。
- -trace 在进入/退出规则前打印规则名字和当前的记号。
- -diagnostics 分析时打开诊断消息。此生成消息仅用于异常情况,如二义性输入短语。
- -SLL 使用更快但稍弱的分析策略。
正文到此结束
热门推荐










相关文章







Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

