大数据同步工具之FlinkCDC/Canal/Debezium对比
前言
数据准实时复制(CDC)是目前行内实时数据需求大量使用的技术,随着国产化的需求,我们也逐步考虑基于开源产品进行准实时数据同步工具的相关开发,逐步实现对商业产品的替代。本文把市面上常见的几种开源产品,Canal、Debezium、Flink CDC 从原理和适用做了对比,供大家参考。
Debezium
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
Debezium是一种CDC(Change Data Capture)工具,工作原理类似大家所熟知的Canal, DataBus, Maxwell等,是通过抽取数据库日志来获取变更。
Debezium最初设计成一个Kafka Connect 的Source Plugin,目前开发者虽致力于将其与Kafka Connect解耦,但当前的代码实现还未变动。下图引自Debeizum官方文档,可以看到一个Debezium在一个完整CDC系统中的位置。
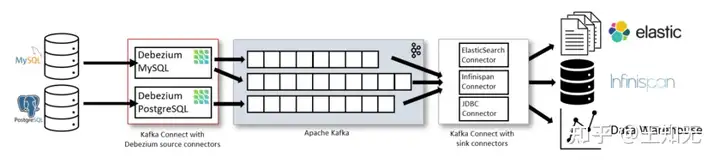
Kafka Connect 为Source Plugin提供了一系列的编程接口,最主要的就是要实现SourceTask的poll方法,其返回List<SourceRecord>将会被以最少一次语义的方式投递至Kafka。
Debezium MySQL 架构
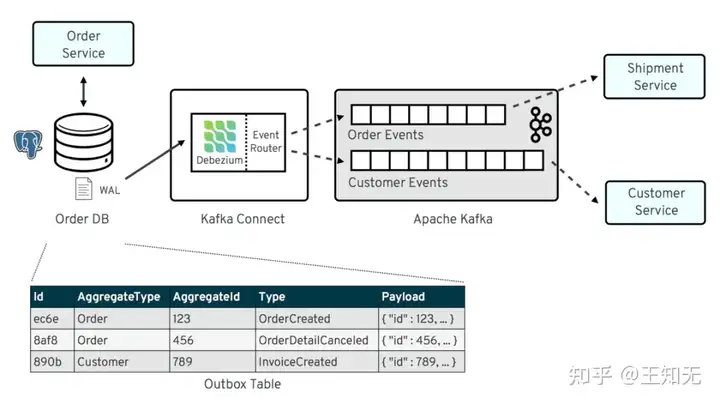
Reader体系构成了MySQL模块中代码的主线,我们的分析从Reader开始。
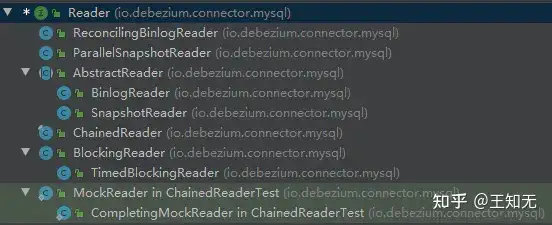
从名字上应该可以看出,真正主要的是SnapshotReader和BinlogReader,分别实现了对MySQL数据的全量读取和增量读取,他们继承于AbstractReader,里面封装了共用逻辑,下图是AbstractReader的内部设计。

可以看到,AbstractReader在实现时,并没有直接将enqueue喂进来的record投递进Kafka,而是通过一个内存阻塞队列BlockingQueue进行了解耦,这种设计有诸多好处:
1.职责解耦
如上的图中,在喂入BlockingQueue之前,要根据条件判断是否接受该record;在向Kafka投递record之前,判断task的running状态。这样把同类的功能限定在特定的位置。
2.线程隔离
BlockingQueue是一个线程安全的阻塞队列,通过BlockingQueue实现的生产者消费者模型,是可以跑在不同的线程里的,这样避免局部的阻塞带来的整体的干扰。如上图中的右侧,消费者会定期判断running标志位,若running被stop信号置为了false,可以立刻停止整个task,而不会因MySQL IO阻塞延迟相应。
3.Single与Batch的互相转化
Enqueue record是单条的投递record,drain_to是批量的消费records。这个用法也可以反过来,实现batch到single的转化。
可能你还知道阿里开源的另一个MySQL CDC工具canal,他只负责stream过程,并没有处理snapshot过程,这也是debezium相较于canal的一个优势。
对于Debezium来说,基本沿用了官方搭建从库的这一思路,让我们看下官方文档描述的详细步骤。
MySQL连接器每次获取快照的时候会执行以下的步骤:
- 获取一个全局读锁,从而阻塞住其他数据库客户端的写操作。
- 开启一个可重复读语义的事务,来保证后续的在同一个事务内读操作都是在一个一致性快照中完成的。
- 读取binlog的当前位置。
- 读取连接器中配置的数据库和表的模式(schema)信息。
- 释放全局读锁,允许其他的数据库客户端对数据库进行写操作。
- (可选)把DDL改变事件写入模式改变topic(schema change topic),包括所有的必要的DROP和CREATEDDL语句。
- 扫描所有数据库的表,并且为每一个表产生一个和特定表相关的kafka topic创建事件(即为每一个表创建一个kafka topic)。
- 提交事务。
- 记录连接器成功完成快照任务时的连接器偏移量。
部署
基于 Kafka Connect
最常见的架构是通过 Apache Kafka Connect 部署 Debezium。Kafka Connect 为在 Kafka 和外部存储系统之间系统数据提供了一种可靠且可伸缩性的方式。它为 Connector 插件提供了一组 API 和一个运行时:Connect 负责运行这些插件,它们则负责移动数据。通过 Kafka Connect 可以快速实现 Source Connector 和 Sink Connector 进行交互构造一个低延迟的数据 Pipeline:
- Source Connector(例如,Debezium):将记录发送到 Kafka
- Sink Connector:将 Kafka Topic 中的记录发送到其他系统
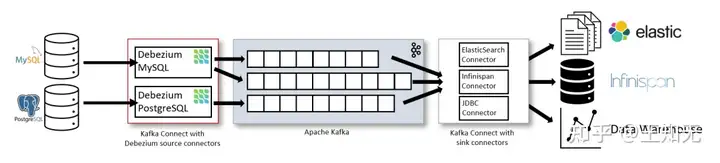
如上图所示,部署了 MySQL 和 PostgresSQL 的 Debezium Connector 以捕获这两种类型数据库的变更。每个 Debezium Connector 都会与其源数据库建立连接:
- MySQL Connector 使用客户端库来访问 binlog。
- PostgreSQL Connector 从逻辑副本流中读取数据。
除了 Kafka Broker 之外,Kafka Connect 也作为一个单独的服务运行。默认情况下,数据库表的变更会写入名称与表名称对应的 Kafka Topic 中。如果需要,您可以通过配置 Debezium 的 Topic 路由转换来调整目标 Topic 名称。例如,您可以:
- 将记录路由到名称与表名不同的 Topic 中
- 将多个表的变更事件记录流式传输到一个 Topic 中
变更事件记录在 Apache Kafka 中后,Kafka Connect 生态系统中的不同 Sink Connector 可以将记录流式传输到其他系统、数据库,例如 Elasticsearch、数据仓库、分析系统或者缓存(例如 Infinispan)。
Debezium Server
另一种部署 Debezium 的方法是使用 Debezium Server。Debezium Server 是一个可配置的、随时可用的应用程序,可以将变更事件从源数据库流式传输到各种消息中间件上。
下图展示了基于 Debezium Server 的变更数据捕获 Pipeline 架构:
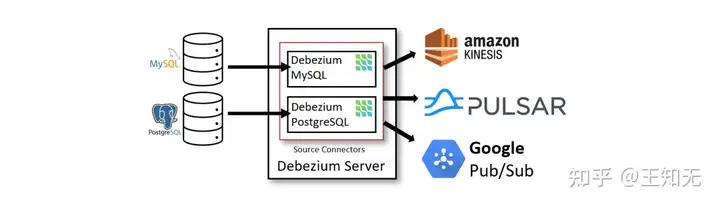
Debezium Server 配置使用 Debezium Source Connector 来捕获源数据库中的变更。变更事件可以序列化为不同的格式,例如 JSON 或 Apache Avro,然后发送到各种消息中间件,例如 Amazon Kinesis、Google Cloud Pub/Sub 或 Apache Pulsar。
嵌入式引擎
使用 Debezium Connector 的另一种方法是嵌入式引擎。在这种情况下,Debezium 不会通过 Kafka Connect 运行,而是作为嵌入到您自定义 Java 应用程序中的库运行。这对于在您的应用程序本身内获取变更事件非常有帮助,无需部署完整的 Kafka 和 Kafka Connect 集群,也不用将变更流式传输到 Amazon Kinesis 等消息中间件上。
特性
Debezium 是一组用于 Apache Kafka Connect 的 Source Connector。每个 Connector 都通过使用该数据库的变更数据捕获 (CDC) 功能从不同的数据库中获取变更。与其他方法(例如轮询或双重写入)不同,Debezium 的实现基于日志的 CDC:
- 确保捕获所有的数据变更。
- 以极低的延迟生成变更事件,同时避免因为频繁轮询导致 CPU 使用率增加。例如,对于 MySQL 或 PostgreSQL,延迟在毫秒范围内。
- 不需要更改您的数据模型,例如 ‘Last Updated’ 列。
- 可以捕获删除操作。
- 可以捕获旧记录状态以及其他元数据,例如,事务 ID,具体取决于数据库的功能和配置。
Flink CDC
- 2020 年 7 月提交了第一个 commit,这是基于个人兴趣孵化的项目;
- 2020 年 7 中旬支持了 MySQL-CDC;
- 2020 年 7 月末支持了 Postgres-CDC;
一年的时间,该项目在 GitHub 上的 star 数已经超过 800。
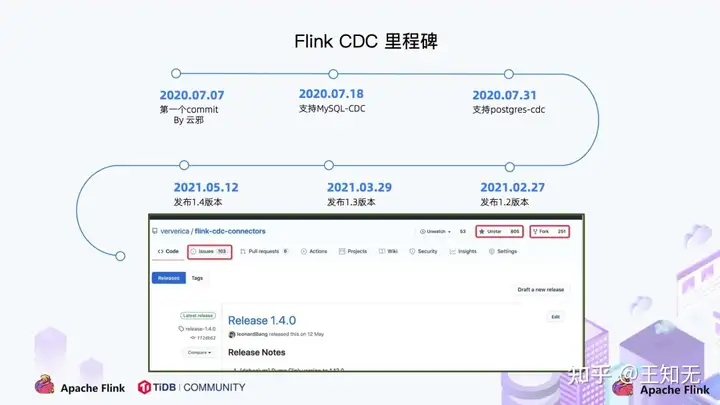
Flink CDC 发展
Flink CDC 底层封装了 Debezium, Debezium 同步一张表分为两个阶段:
- 全量阶段:查询当前表中所有记录;
- 增量阶段:从 binlog 消费变更数据。
大部分用户使用的场景都是全量 + 增量同步,加锁是发生在全量阶段,目的是为了确定全量阶段的初始位点,保证增量 + 全量实现一条不多,一条不少,从而保证数据一致性。从下图中我们可以分析全局锁和表锁的一些加锁流程,左边红色线条是锁的生命周期,右边是 MySQL 开启可重复读事务的生命周期。
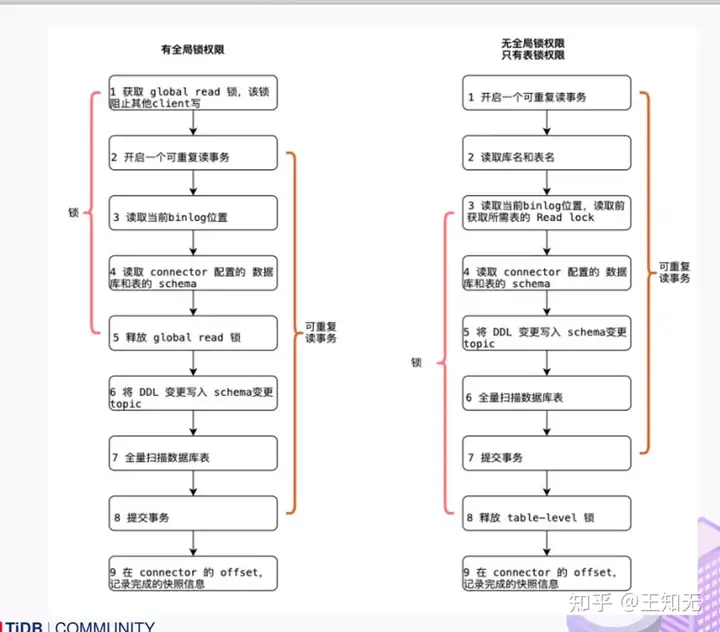
以全局锁为例,首先是获取一个锁,然后再去开启可重复读的事务。这里锁住操作是读取 binlog 的起始位置和当前表的 schema。这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 是可以对应上的,因为表的 schema 是会改变的,比如如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动 BinlogReader 从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户只有表锁。表锁锁的时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。
经过上面分析,接下来看看这些锁到底会造成怎样严重的后果:

Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述 hang 住数据的风险。
Flink CDC 1.x得到了很多用户在社区的反馈,主要归纳为三个:

- 全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
- 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
- 全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
通过上面的分析,可以知道 2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展、checkpoint。

目前,Flink CDC 2.0 也已经正式发布,此次的核心改进和提升包括:
- 并发读取,全量数据的读取性能可以水平扩展;
- 全程无锁,不对线上业务产生锁的风险;
- 断点续传,支持全量阶段的 checkpoint。
Canal
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的canal支持源端MySQL版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
工作原理
MySQL主备复制原理
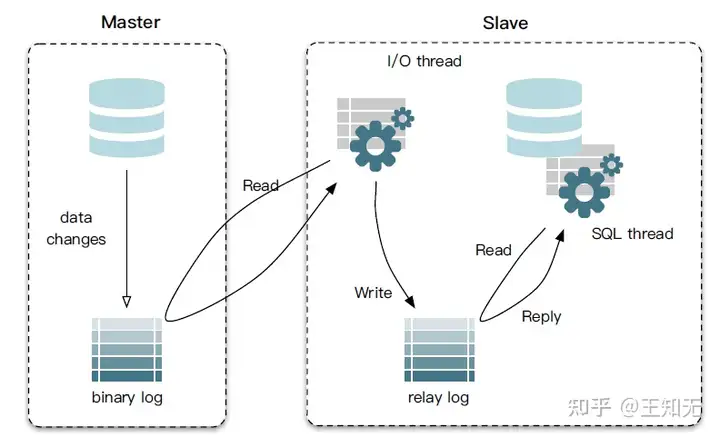
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议
- MySQL master收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
Binlog获取详解
Binlog发送接收流程,流程如下图所示:
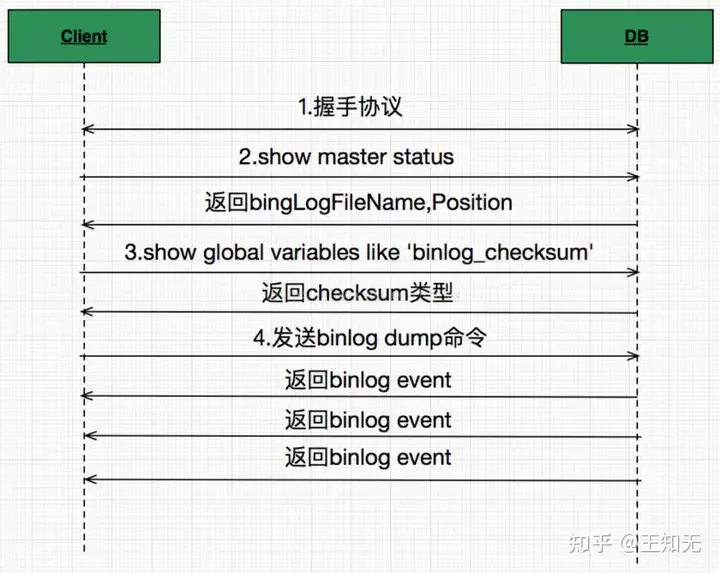
首先,我们需要伪造一个slave,向master注册,这样master才会发送binlog event。注册很简单,就是向master发送COM_REGISTER_SLAVE命令,带上slave相关信息。这里需要注意,因为在MySQL的replication topology中,都需要使用一个唯一的server id来区别标示不同的server实例,所以这里我们伪造的slave也需要一个唯一的server id。
接着实现binlog的dump。MySQL只支持一种binlog dump方式,也就是指定binlog filename + position,向master发送COM_BINLOG_DUMP命令。在发送dump命令的时候,我们可以指定flag为BINLOG_DUMP_NON_BLOCK,这样master在没有可发送的binlog event之后,就会返回一个EOF package。不过通常对于slave来说,一直把连接挂着可能更好,这样能更及时收到新产生的binlog event。
Dump命令包图如下所示:

如上图所示,在报文中塞入binlogPosition和binlogFileName即可让master从相应的位置发送binlog event。
canal结构
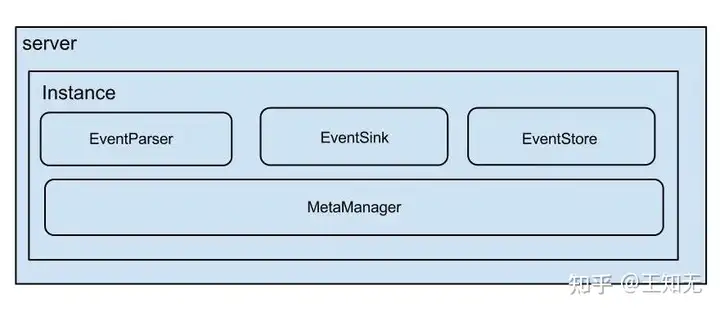
说明:
- server代表一个canal运行实例,对应于一个jvm,也可以理解为一个进程
- instance对应于一个数据队列 (1个server对应1..n个instance),每一个数据队列可以理解为一个数据库实例。
Server设计
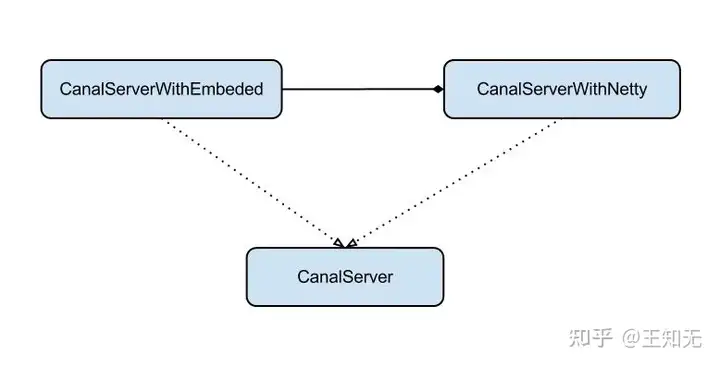
server代表了一个canal的运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式) / Netty(网络访问)的两种实现
- Embeded : 对latency和可用性都有比较高的要求,自己又能hold住分布式的相关技术(比如failover)
- Netty : 基于netty封装了一层网络协议,由canal server保证其可用性,采用的pull模型,当然latency会稍微打点折扣,不过这个也视情况而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠拢,push在数据量大的时候会有一些问题)
Instance设计
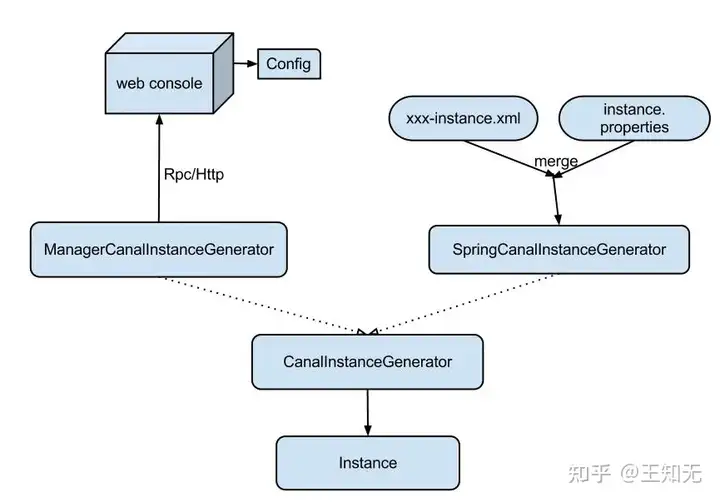
instance代表了一个实际运行的数据队列,包括了EventPaser,EventSink,EventStore等组件。
抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:
manager方式:和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用,Otter采用这种方式) spring方式:基于spring xml + properties进行定义,构建spring配置.
下面是canalServer和instance如何运行:
canalServer.setCanalInstanceGenerator(new CanalInstanceGenerator() {
public CanalInstance generate(String destination) {
Canal canal = canalConfigClient.findCanal(destination);
// 此处省略部分代码 大致逻辑是设置canal一些属性
CanalInstanceWithManager instance = new CanalInstanceWithManager(canal, filter) {
protected CanalHAController initHaController() {
HAMode haMode = parameters.getHaMode();
if (haMode.isMedia()) {
return new MediaHAController(parameters.getMediaGroup(),
parameters.getDbUsername(),
parameters.getDbPassword(),
parameters.getDefaultDatabaseName());
} else {
return super.initHaController();
}
}
protected void startEventParserInternal(CanalEventParser parser, boolean isGroup) {
//大致逻辑是 设置支持的类型
//初始化设置MysqlEventParser的主库信息,这处抽象不好,目前只支持mysql
}
};
return instance;
}
});
canalServer.start(); //启动canalServer
canalServer.start(destination);//启动对应instance
this.clientIdentity = new ClientIdentity(destination, pipeline.getParameters().getMainstemClientId(), filter);
canalServer.subscribe(clientIdentity);// 发起一次订阅,当监听到instance配置时,调用generate方法注入新的instance
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
EventParser设计
大致过程:
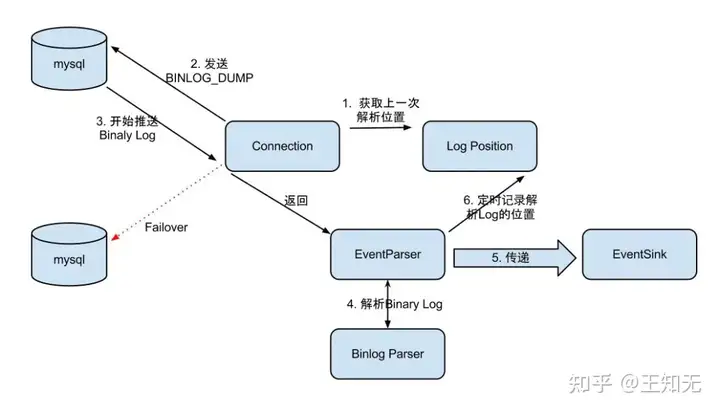
整个parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,发送BINLOG_DUMP指令
// 0. write command number
// 1. write 4 bytes bin-log position to start at
// 2. write 2 bytes bin-log flags
// 3. write 4 bytes server id of the slave
// 4. write bin-log file name
- Mysql开始推送Binaly Log
- 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息(补充字段名字,字段类型,主键信息,unsigned类型处理)
- 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
- 存储成功后,由CanalLogPositionManager定时记录Binaly Log位置
EventSink设计
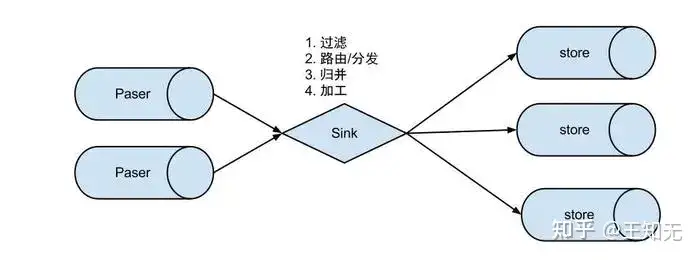
说明:
- 数据过滤:支持通配符的过滤模式,表名,字段内容等
- 数据路由/分发:解决1:n (1个parser对应多个store的模式)
- 数据归并:解决n:1 (多个parser对应1个store)
- 数据加工:在进入store之前进行额外的处理,比如join
数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注。
数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并。
EventStore设计
- 目前仅实现了Memory内存模式,后续计划增加本地file存储,mixed混合模式。
- 借鉴了Disruptor的RingBuffer的实现思路
RingBuffer设计:
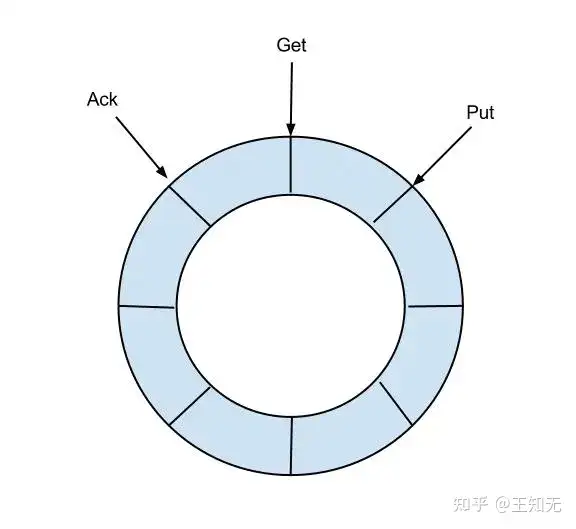
定义了3个cursor
Put : Sink模块进行数据存储的最后一次写入位置 Get : 数据订阅获取的最后一次提取位置 Ack : 数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
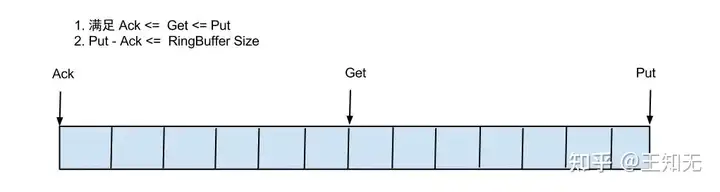
实现说明:
Put/Get/Ack cursor用于递增,采用long型存储buffer的get操作,通过取余或者与操作。(与操作:cusor & (size - 1) , size需要为2的指数,效率比较高)
HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),可以看下我之前zookeeper的相关文章。
Canal Server:
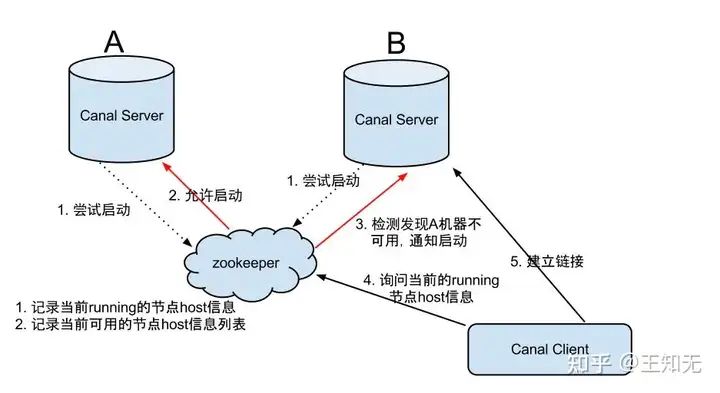
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制。
总结
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
基于查询的 CDC:
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
对比常见的开源 CDC 方案,我们可以发现:

- 对比增量同步能力:
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。- 对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
- 而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
- 在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

