流操作读取MySQL数据
一、业务场景
开发过程中经常会使用MySQL存储数据,有时需要操作大批量数据,如迁移数据、导出数据。因此需要考虑使用高效、速度快且可靠的数据读取方式。二、处理方式
1、常规查询:
一次性读取全量数据到JVM内存中; 分页读取,每次读取10000条;2、流式查询:
每次读取一条加载到JVM内存进行业务处理;三、测试
1.常规查询
默认查询情况下,完整的检索结果集会存储在内存中。在大多数情况下,这是最有效的操作方式,更易于实现。 代码如下(示例):package com.cxb.demotest;
import com.google.common.base.Stopwatch;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.concurrent.TimeUnit;
import javax.annotation.Resource;
import javax.sql.DataSource;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@Slf4j
@SpringBootTest(classes = QuickStartDemoStart.class)
@RunWith(SpringRunner.class)
public class StreamQueryTest {
@Resource
private DataSource dataSource;
@Test
public void testQueryAll() throws Exception {
String sql = "SELECT * from nucleic_acid_test_result_copy2 LIMIT 1000000";
//从数据源拿到链接
Connection connection = dataSource.getConnection();
//根据链接创建statement进行sql提交
PreparedStatement statement = connection.prepareStatement(sql);
ResultSet resultSet = null;
int count = 0;
Stopwatch stopwatch = Stopwatch.createStarted();
try {
resultSet = statement.executeQuery();
while (resultSet.next()) {
String id = resultSet.getString("id");
count++;
System.out.println(id);
}
} catch (Exception e){
log.error("普通读取报错:", e);
}
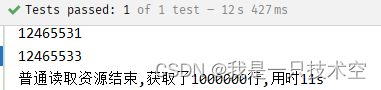
System.out.println("普通读取资源结束,获取了" + count + "行,用时" + stopwatch.elapsed(TimeUnit.SECONDS) + "s");
//先开后关
resultSet.close();
statement.close();
connection.close();
}
}
查询结果:
2.流式查询
流式查询,其查询会独占连接(注意必须先读取或关闭结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常)。代码如下:@Test
public void testStreamQuery() throws Exception {
String sql = "SELECT * from nucleic_acid_test_result_copy2 LIMIT 1000000 ";
//从数据源拿到链接
Connection connection = dataSource.getConnection();
//根据链接创建statement进行sql提交,做一些statement配置
PreparedStatement statement = connection.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
/**
* createStreamingResultSet
* We only stream result sets when they are forward-only, read-only,
* and the fetch size has been set to Integer.MIN_VALUE
* 源码中:我们仅在结果集为 forward-only、read-only且提取大小已设置为 Integer.MIN_VALUE 时才对其进行流式处理
* protected boolean createStreamingResultSet() {
* return ((this.query.getResultType() == Type.FORWARD_ONLY)
* && (this.resultSetConcurrency == java.sql.ResultSet.CONCUR_READ_ONLY)
* && (this.query.getResultFetchSize() == Integer.MIN_VALUE));
* }
*/
statement.setFetchSize(Integer.MIN_VALUE);
//====================statement执行sql======================
Stopwatch stopwatch = Stopwatch.createStarted();
ResultSet resultSet = statement.executeQuery();//期间不会阻塞 直接返回结果行,过多的缓存在驱动内存中
//================================================
int count = 0;
while (resultSet.next()) {
String id = resultSet.getString("id");
count++;
System.out.println(id);
}
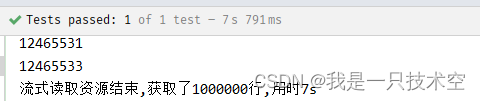
System.out.println("流式读取资源结束,获取了" + count + "行,用时" + stopwatch.elapsed(TimeUnit.SECONDS) + "s");
//先开后关
resultSet.close();
statement.close();
connection.close();
}
查询结果:
四、测试结果
从测试结果对比,从MySQL查询100W条数据,使用流式读取速度快了将近一倍五、总结
流式读取的优点:
可以解决内存资源紧张的情况的下,导致的OOM。 对数据可以平滑的处理,匹配数据资源获取非阻塞。 内存资源的使用上,避免了内存消耗突然提高的风险。 避免了在需要大数据读取场景下的,手动分页去多次请求读取,一次查询,流式读取。应用场景
我们可以做一些大量的数据读取后,做数据分析。以及我们需要做大量的数据下载到本地的时候,都可以以流式读取后输出到本地。参考资料
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

