mongodb聚合排序的一个巨坑
现象:
mongodb cpu动不动要100%,如下图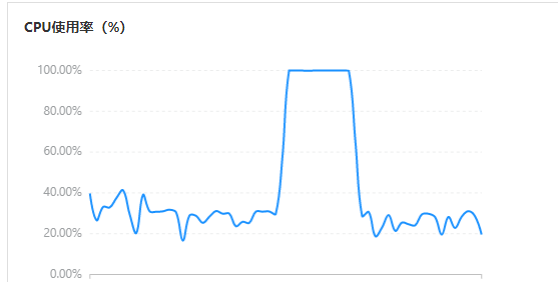
分析原因:
查看慢日志发现,很多条这样的查询,一直未执行行完成,占用大量的CPU[
{
$match: {
"tags.taskId": "64dae0a9deb52d2f9a1bd71e",
grnty: "minute",
"tags.type": "task",
"tags.taskRecordId":
"64e5c004133738231bc36906",
},
},
{
$sort: {
_id: -1,
},
},
{
$limit: 5,
},
{
$unwind: "$ss",
},
{
$group: {
_id: "$ss.vs.inputQps",
qps: {
$avg: "$ss.vs.inputQps",
},
},
},
]Criteria criteria = new Criteria();
tags.forEach((k,v)->{
String format = String.format(TAG_FORMAT, k);
criteria.and(format).is(v);
});
criteria.and(MeasurementEntity.FIELD_GRANULARITY).is(Granularity.GRANULARITY_MINUTE);
MatchOperation match = Aggregation.match(criteria);
SortOperation sort = Aggregation.sort(Sort.by(Sort.Direction.DESC, "_id"));
LimitOperation limit = Aggregation.limit(5);
UnwindOperation unwind = Aggregation.unwind("ss", false);
GroupOperation group = Aggregation.group().avg("ss.vs.inputQps").as("qps");
Aggregation aggregation = Aggregation.newAggregation(match, sort, limit, unwind, group);
已经使用了 $match 和 $sort 操作来筛选和排序文档。仍然对整个集合进行了排序?
这可能是由于 MongoDB 的查询优化器在执行查询时做出的决策。 在 MongoDB 中,查询优化器会尝试根据查询计划和索引来优化查询性能。在某些情况下,优化器可能会选择在 $match 操作之后对整个集合进行排序,而不仅仅是对 $match 操作筛选出的文档进行排序。这可能是因为优化器认为在整个集合上进行排序的成本更低,或者由于其他优化策略。 如果你希望只对 $match 操作筛选出的文档进行排序,可以尝试使用索引来优化查询。确保你的查询条件和排序字段都有适当的索引,这样可以帮助优化器做出更好的决策,以便只对筛选结果进行排序。解决方案
在这种情况下,你可以尝试创建一个复合索引,包含筛选条件和排序字段。例如,你可以创建一个包含 "tags.taskId","grnty","tags.typ","tags.taskRecordId","_id" 字段的复合索引。这样,MongoDB 在执行查询时可以使用该索引来加速筛选和排序操作。总结
为了只对筛选结果进行排序,你可以尝试以下步骤:- 创建一个复合索引,包含筛选条件和排序字段。
- 确保查询条件和排序字段在索引中的顺序与聚合管道中的顺序一致。
- 使用 explain() 方法来查看查询的执行计划和索引使用情况,以便进行优化。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

