SpringBoot2.x系列教程之整合Hazelcast实现分布式缓存
前言
在以上一篇教程中,壹哥 带大家认识了Hazelcast框架,接下来我们就利用该框架实现分布式缓存功能。
一. 分布式缓存代码实现步骤
1. 创建Web项目
我们按照之前的经验,创建一个Web程序,并将之改造成Spring Boot项目,具体过程略。
2. 添加依赖包
在pom.xml文件中添加Hazelcast的核心依赖包。
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
</dependency>
3. 创建application.yml配置文件
创建application.yml配置文件,可以在这里设置服务器端口号。
server:
port: 8081
4. 添加Hazelcast配置类
创建一个Hazelcast的配置类,对Hazelcast进行必要的配置。
package com.yyg.boot.config;
import com.hazelcast.config.*;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import com.hazelcast.core.ITopic;
import com.yyg.boot.interceptor.IMapInterceptor;
import com.yyg.boot.interceptor.MapListener;
import com.yyg.boot.interceptor.TopicListener;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author 一一哥Sun
* @Date Created in 2020/4/23
* @Description Description
*/
@Configuration
public class HazelcastConfiguration {
@Bean
public Config hazelCastConfig() {
Config config = new Config();
//解决同网段下,不同库项目
GroupConfig gc=new GroupConfig("hazelGroup");
config.setInstanceName("hazelcast-instance")
.addMapConfig(new MapConfig()
.setName("configuration")
// Map中存储条目的最大值[0~Integer.MAX_VALUE]。默认值为0。
.setMaxSizeConfig(new MaxSizeConfig(200, MaxSizeConfig.MaxSizePolicy.FREE_HEAP_SIZE))
//数据释放策略[NONE|LRU|LFU]。这是Map作为缓存的一个参数,用于指定数据的回收算法。默认为NONE。LRU:“最近最少使用“策略。
.setEvictionPolicy(EvictionPolicy.LRU)
//数据留存时间[0~Integer.MAX_VALUE]。缓存相关参数,单位秒,默认为0。
.setTimeToLiveSeconds(-1))
.setGroupConfig(gc);
return config;
}
}
5. 关于配置说明
5.1 eviction-policy
数据释放策略[NONE|LRU|LFU]。这是Map作为缓存的一个参数,用于指定数据的回收算法,默认为NONE。
- NONE:当设置为NONE时,不会发生数据回收,同时max-size会失效。但是任然可以使用time-to-live-seconds和max-idle-seconds参数来控制数据留存时间。
- LRU:“最近最少使用“策略。
- LFU:“最不常用的使用”策略。
5.2 time-to-live-seconds(TTL)
数据留存时间[0~Integer.MAX_VALUE]。缓存相关参数,单位秒,默认为0。这个参数决定了一条数据在map中的停留时间。当数据在Map中留存超过这个时间并且没有被更新时,它会根据指定的回收策略从Map中移除。值为0时,意味着无求大。
6. 创建Controller接口方法
我们创建一个Controller,在里面定义几个测试接口方法。
package com.yyg.boot.web;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IList;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.Map;
import java.util.Queue;
/**
* @Author 一一哥Sun
* @Date Created in 2020/4/23
* @Description Description
*/
@Slf4j
@RestController
@RequestMapping("/hazelcast")
public class HazelcastController {
@Autowired
private HazelcastInstance hazelcastInstance;
@PostMapping(value = "/save")
public String saveMapData(@RequestParam String key, @RequestParam String value) {
Map<String, String> hazelcastMap = hazelcastInstance.getMap("hazelcastMap");
hazelcastMap.put(key, value);
return "success";
}
@GetMapping(value = "/get")
public String getMapData(@RequestParam String key) {
Map<String, String> hazelcastMap = hazelcastInstance.getMap("hazelcastMap");
return hazelcastMap.get(key);
}
@GetMapping(value = "/all")
public Map<String, String> readAllDataFromHazelcast() {
return hazelcastInstance.getMap("hazelcastMap");
}
@GetMapping(value = "/list")
public String saveList(@RequestParam(required = false) String value) {
// 创建集群List
IList<Object> clusterList = hazelcastInstance.getList("myList");
clusterList.add(value);
return "success";
}
@GetMapping(value = "/showList")
public IList<Object> showList() {
return hazelcastInstance.getList("myList");
}
@GetMapping(value = "/clearList")
public String clearList() {
IList<Object> clusterList = hazelcastInstance.getList("myList");
clusterList.clear();
return "success";
}
@GetMapping(value = "/queue")
public String saveQueue(@RequestParam String value) {
// 创建集群Queue
Queue<String> clusterQueue = hazelcastInstance.getQueue("myQueue");
clusterQueue.offer(value);
return "success";
}
@GetMapping(value = "/showQueue")
public Queue<String> showQueue() {
Queue<String> clusterQueue = hazelcastInstance.getQueue("myQueue");
for (String obj : clusterQueue) {
log.warn("value=" + obj);
}
return clusterQueue;
}
@GetMapping(value = "/clearQueue")
public String clearQueue() {
Queue<String> clusterQueue = hazelcastInstance.getQueue("myQueue");
clusterQueue.clear();
return "success";
}
}
7. 创建入口类
最后创建项目的入口类。
package com.yyg.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Author 一一哥Sun
* @Date Created in 2020/4/23
* @Description Description
*/
@SpringBootApplication
public class HazelcastApplication {
public static void main(String[] args){
SpringApplication.run(HazelcastApplication.class,args);
}
}
二. 启动项目进行测试
代码编写完毕后,我们就把项目启动起来进行测试。
1. 启动项目集群
程序启动时,控制台会输出如下信息:
[hazelGroup] [3.12.6] Prefer IPv4 stack is true, prefer IPv6 addresses is false
2020-04-24 11:37:45.790 INFO 5820 --- com.hazelcast.instance.AddressPicker
[hazelGroup] [3.12.6] Picked [192.168.87.102]:5702, using socket ServerSocket[addr=/0:0:0:0:0:0:0:0,localport=5702], bind any local is true
这一段输出说明了当前 Hazelcast 的网络环境。首先是检测IPv4可用且检查到当前的IPv4地址是192.168.87.102。然后使用IPv6启用socket。在某些无法使用IPv6的环境上,需要强制指定使用IPv4,增加jvm启动参数:-Djava.net.preferIPv4Stack=true 即可。
[192.168.87.102]:5702 [hazelGroup] [3.12.6] Hazelcast 3.12.6 (20200130 - be02cc5) starting at [192.168.87.102]:5702
com.hazelcast.system : [192.168.87.102]:5702 [hazelGroup] [3.12.6] Copyright (c) 2008-2020, Hazelcast, Inc. All Rights Reserved.
这一段输出说明了当前实例的初始化端口号是5701。Hazelcast 默认使用5701端口。如果发现该端口被占用,会+1查看5702是否可用,如果还是不能用会继续向后探查直到5800。Hazelcast 默认使用5700到5800的端口,如果都无法使用会抛出启动异常。
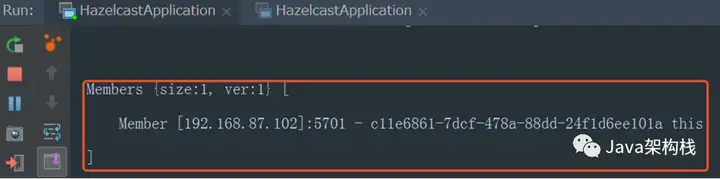
我们先在8081端口上进行启动,在控制台会发现此时Members数量只有1,个,Hazelcast运行在5701端口上。
然后我们在8082端口上,再次启动第2个进程。此时在控制台,会发现Members数量变成了2个,意味着一个新的Hazelcast实例加入到了集群中。
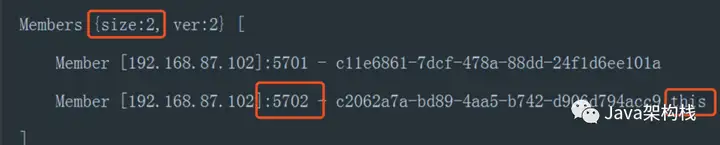
Members[2]表示当前集群只有2个节点,2个节点都在ip为192.168.87.102的这台设备上,2个节点分别占据了5701端口和5702端口。端口后面的this说明这是当前节点,而未标记this的是其他接入集群的节点。
由此可见,Hazelcast实现集群非常的简单,会自动把不同进程添加到集群中。
2. 测试map结构
我们先在8081端口的进程上存储一个数据到map中。
然后我们在8081上取数据,会发现数据已经获取到了。
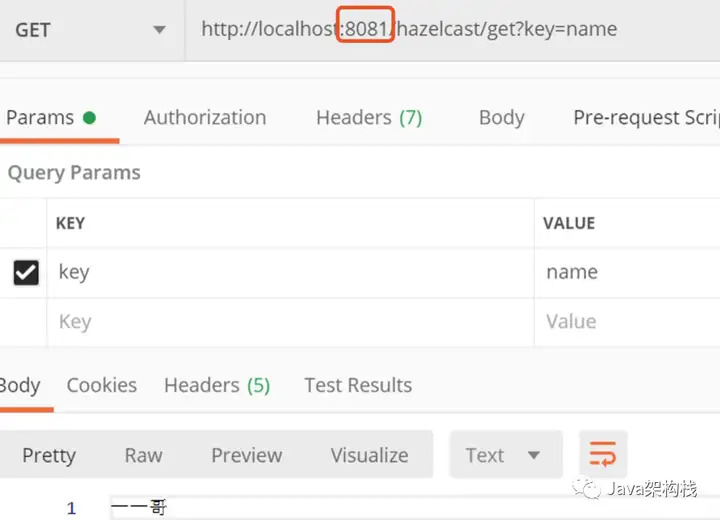
然后我们在8082端口的进程上获取数据,发现同样也可以获取到之前存储的数据。说明在Hazelcast中只要在一个服务器节点上存储了数据,就可以自动实现从其他集群节点中获取到另一个节点中存储的数据。
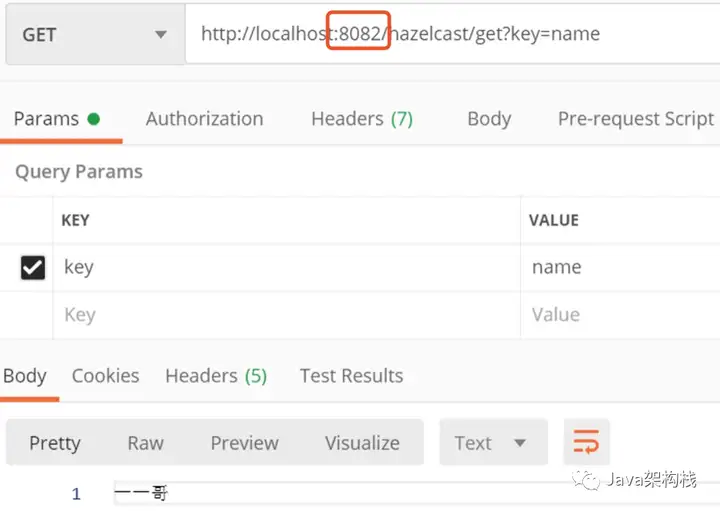
3. 测试list结构
我们先在8081端口的进程上存储一个数据到list中。
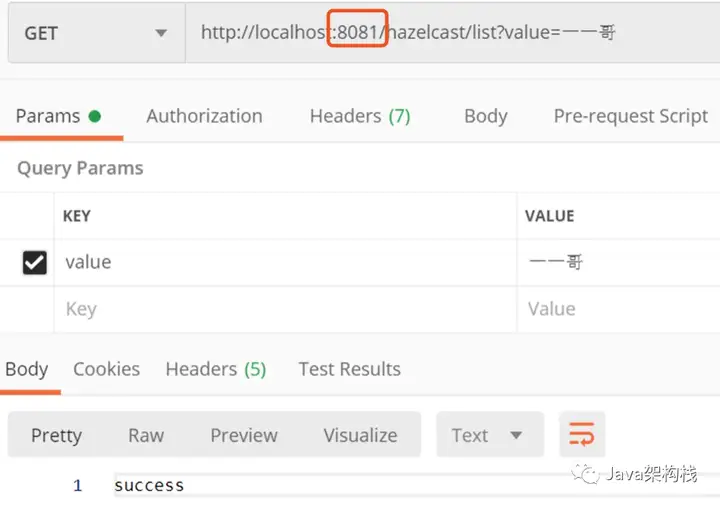
然后我们在8082上取数据,会发现数据已经获取到了。
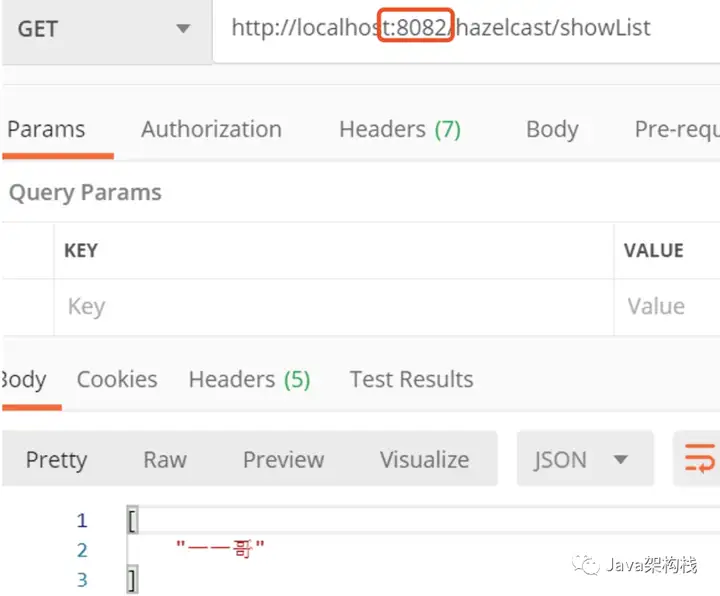
同样的实现了集群数据共享。
4. 测试queue结构
我们先在8081端口的进程上存储一个数据到queue中。
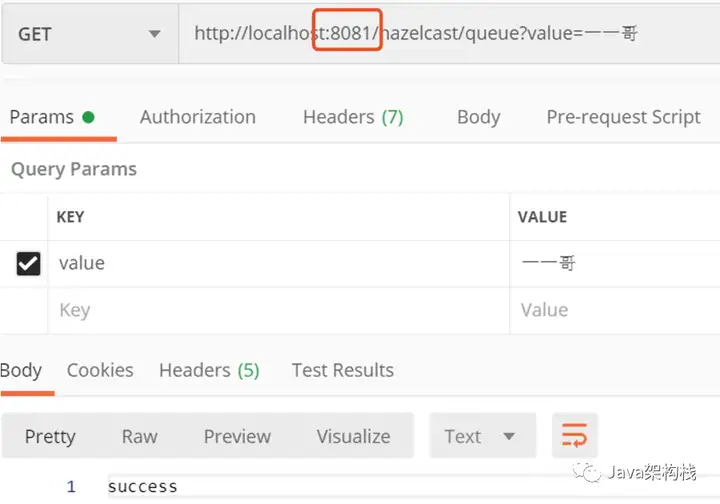
然后我们在8082上取数据,会发现数据已经获取到了。
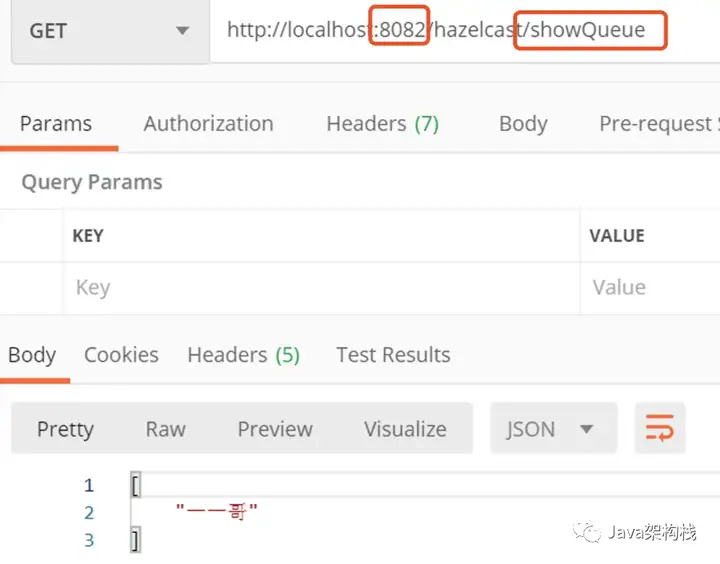
同样的实现了集群数据共享。
三. 进行Hazelcast的高级配置
1. 添加Hazelcast监听器配置
我们在上面的HazelcastConfiguration配置类中添加一些监听器类。
@Bean
public HazelcastInstance hazelcastInstance(Config config) {
HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance(config);
//分布式map监听
IMap<Object, Object> imap = hzInstance.getMap("hazelcastMap");
imap.addLocalEntryListener(new MapListener());
//拦截器(没写内容)
imap.addInterceptor(new IMapInterceptor());
//发布/订阅模式
ITopic<String> topic = hzInstance.getTopic("hazelcastTopic");
topic.addMessageListener(new TopicListener());
return hzInstance;
}
此时完整的HazelcastConfiguration类代码为:
package com.yyg.boot.config;
import com.hazelcast.config.*;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import com.hazelcast.core.ITopic;
import com.yyg.boot.interceptor.IMapInterceptor;
import com.yyg.boot.interceptor.MapListener;
import com.yyg.boot.interceptor.TopicListener;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author 一一哥Sun
* @Date Created in 2020/4/23
* @Description Description
*/
@Configuration
public class HazelcastConfiguration {
@Bean
public Config hazelCastConfig() {
Config config = new Config();
//解决同网段下,不同库项目
GroupConfig gc=new GroupConfig("hazelGroup");
config.setInstanceName("hazelcast-instance")
.addMapConfig(new MapConfig()
.setName("configuration")
// Map中存储条目的最大值[0~Integer.MAX_VALUE]。默认值为0。
.setMaxSizeConfig(new MaxSizeConfig(200, MaxSizeConfig.MaxSizePolicy.FREE_HEAP_SIZE))
//数据释放策略[NONE|LRU|LFU]。这是Map作为缓存的一个参数,用于指定数据的回收算法。默认为NONE。LRU:“最近最少使用“策略。
.setEvictionPolicy(EvictionPolicy.LRU)
//数据留存时间[0~Integer.MAX_VALUE]。缓存相关参数,单位秒,默认为0。
.setTimeToLiveSeconds(-1))
.setGroupConfig(gc);
return config;
}
@Bean
public HazelcastInstance hazelcastInstance(Config config) {
HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance(config);
//分布式map监听
IMap<Object, Object> imap = hzInstance.getMap("hazelcastMap");
imap.addLocalEntryListener(new MapListener());
//拦截器(没写内容)
imap.addInterceptor(new IMapInterceptor());
//发布/订阅模式
ITopic<String> topic = hzInstance.getTopic("hazelcastTopic");
topic.addMessageListener(new TopicListener());
return hzInstance;
}
}
2. 重新启动8081和8082项目进程测试
此时我们可以8081进程的map结构中添加一个新的key与value,如下所示:
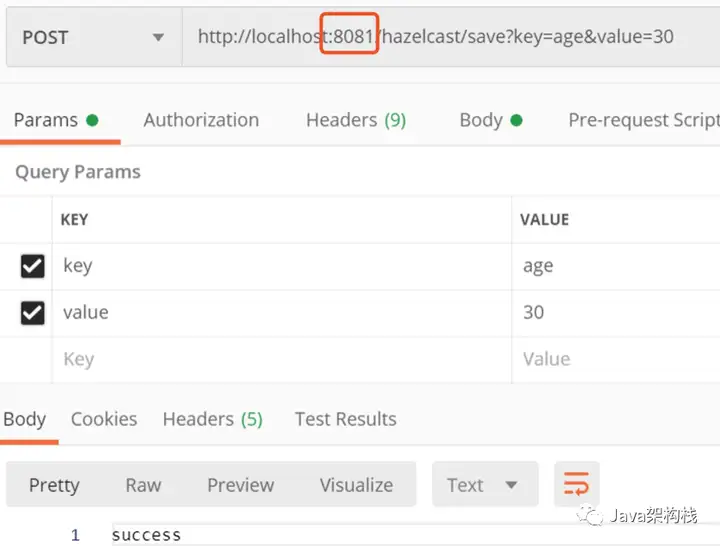
然后在控制台可以看到我们之前Map结构的监听器类中,打印的log输 出如下:

说明我们的IMap的拦截器生效了。而且8082进程中也获取到了存储的age值。
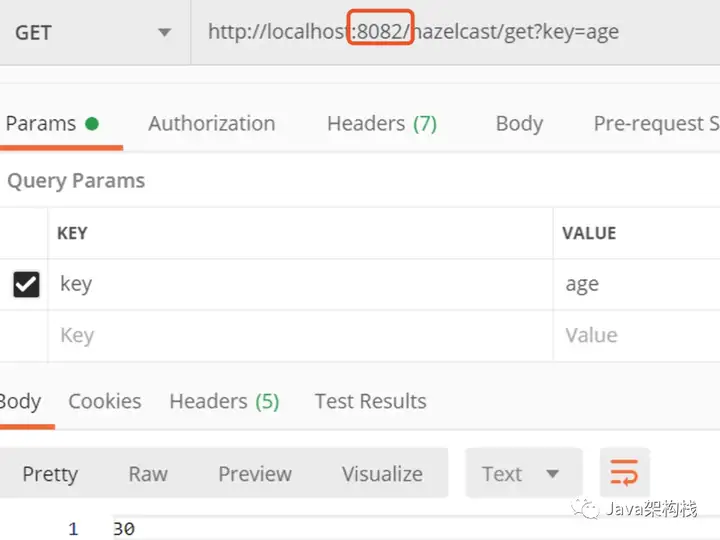
因为Hazelcast是集群的,数据可以在许多应用程序实例之间共享。
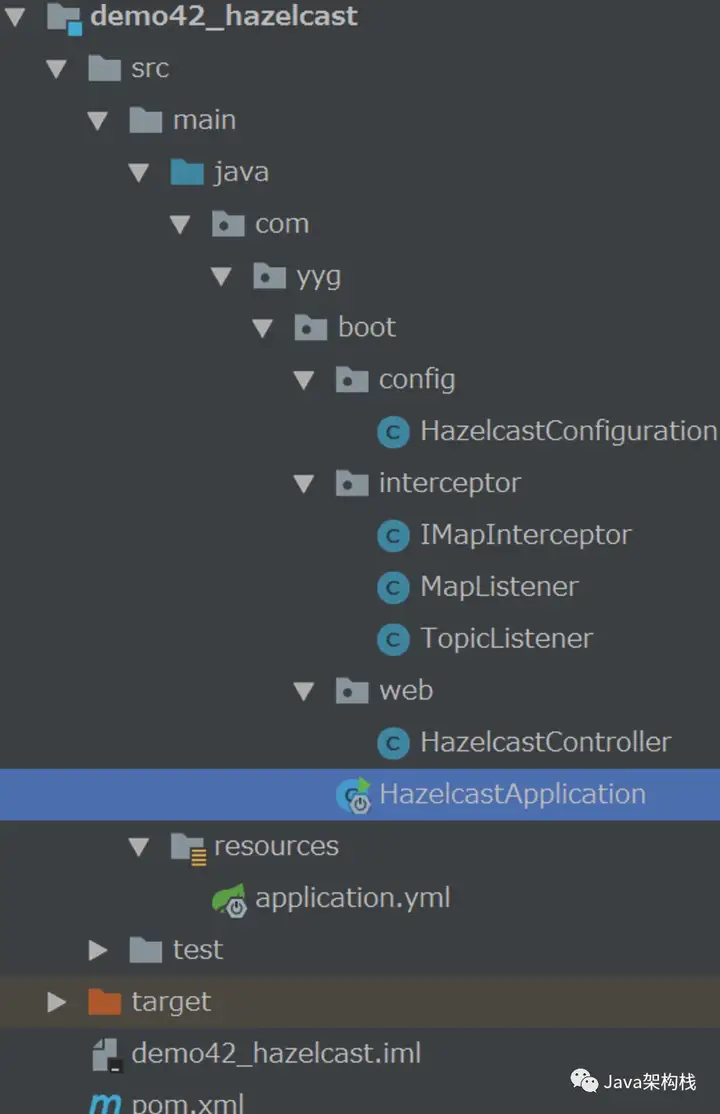
3. 完整项目结构
最终完整的项目结构如下图所示,大家可以参考创建:
四. hazelcast管理终端
hazelcast其实为我们提供了一个管理中心程序,可以帮助我们查看hazelcast中缓存的数据,当然这个管理中心可以不用安装,它只是帮我们查看缓存状态的一个工具而已。
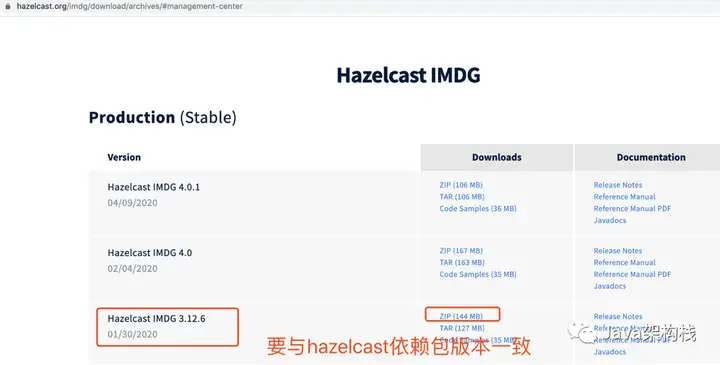
1. 下载hazelcast管理中心
https://hazelcast.org/download/archives/#management-center
2. 解压之后,进入根目录进行启动
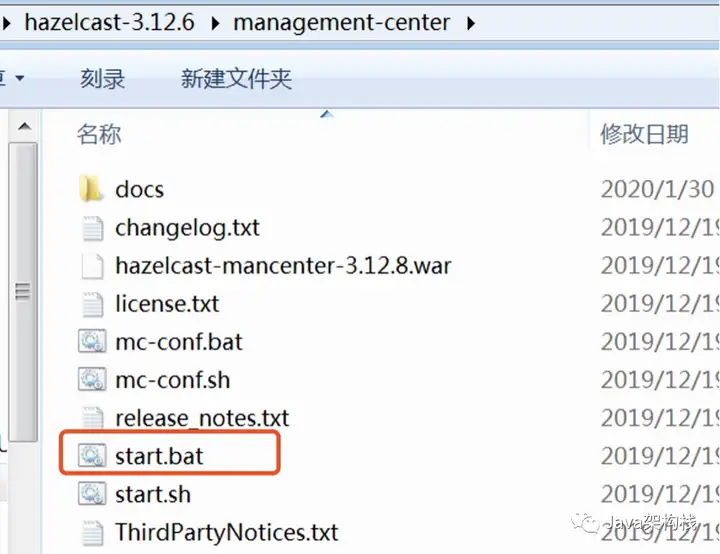
3. 启动start.bat命令
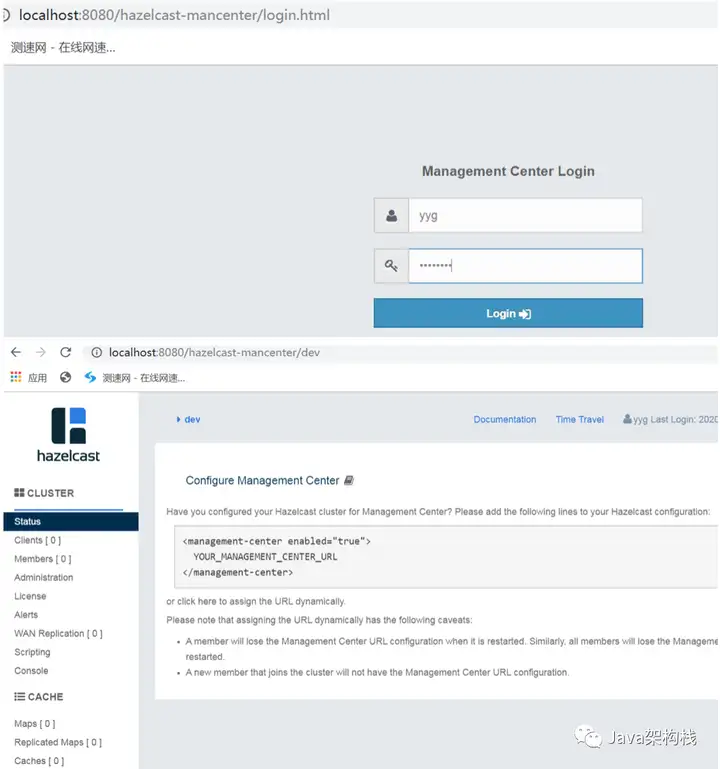
4. 打开管理中心mancenter
一开始会要求先注册一个管理员用户,密码需要8位以上,然后进行登录。
结语
至此,壹哥就带各位利用Hazelcast框架实现了分布式缓存效果,我们会发现利用该框架实现分布式缓存是比较方便的,而且功能也比较强大。
正文到此结束
- 本文标签: hazelcast springboot
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

