Elasticsearch高级查询及分词器
1. ES操作方法
1、在可视化界面Kibana上执行代码:GET _search
{
"query": {
"match_all": {}
}
}
PUT /mytest/user/1
{
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
GET /mytest/user/1{
"_index": "mytest",
"_type": "user",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
}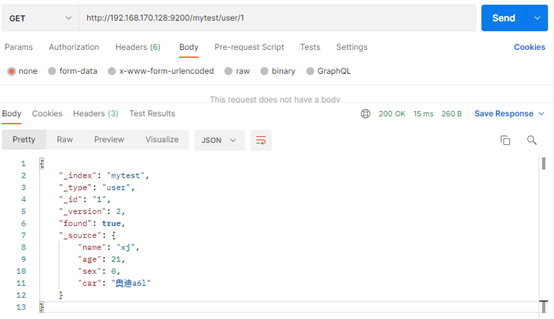 说明:实际上Kibana也是通过restful请求的,其中url在配置文件中配置了。
说明:实际上Kibana也是通过restful请求的,其中url在配置文件中配置了。
2. Elasticsearch倒排索引原理
全文检索底层采用倒排索引。 倒排索引比数据库中的B-tree树查询效率快。 分析倒排索引: 正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。 文档内容:| 序号 | 文档内容 |
| 1 | 小俊是一家科技公司创始人,开的汽车是奥迪a8l,加速爽。 |
| 2 | 小薇是一家科技公司的前台,开的汽车是保时捷911 |
| 3 | 小红买了小薇的保时捷911,加速爽。 |
| 4 | 小明是一家科技公司开发主管,开的汽车是奥迪a6l,加速爽。 |
| 5 | 小军是一家科技公司开发,开的汽车是比亚迪速锐,加速有点慢 |
| 单词ID | 单词 | 倒排列表docId |
| 1 | 小 | 1,2,3,4,5 |
| 2 | 一家 | 1,2,4,5 |
| 3 | 科技公司 | 1,2,4,5 |
| 4 | 开发 | 4,5 |
| 5 | 汽车 | 1,2,4,5 |
| 6 | 奥迪 | 1,4 |
| 7 | 加速爽 | 1,3,4 |
| 8 | 保时捷 | 2,3 |
| 9 | 保时捷911 | 2 |
| 10 | 比亚迪 | 5 |
3. Elasticsearch高级查询(重点)
3.1 数据插入:POST、PUT
# POST 插入数据,可以不加idPOST /mytest/user/
{
"name": "xj_2",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
# 结果:
{
"_index": "mytest",
"_type": "user",
"_id": "cycedXwBx9h5nuD8Z6Xh",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
 说明:POST生成的id是ES自动生成的不重复标志
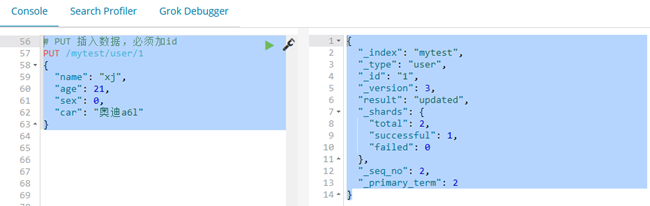
# PUT 插入数据,必须加id
说明:POST生成的id是ES自动生成的不重复标志
# PUT 插入数据,必须加id
PUT /mytest/user/1
{
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
# 结果:
{
"_index": "mytest",
"_type": "user",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
3.2 数据查询:GET
### 简单查询# 根据id进行查询
GET /mytest/user/1
# 查当前索引下所有数据
GET /mytest/user/_search
# 查当前索引下多个id的数据
GET /mytest/user/_mget
{
"ids": ["1","2"]
}
# 查询年龄age为21
GET /mytest/user/_search?q=age:21
# 查询年龄age为30岁到60岁之间
GET /mytest/user/_search?q=age[30 TO 60]&sort=age:desc
# 查询年龄age为30岁到60岁之间&倒序排列
GET /mytest/user/_search?q=age[20 TO 60]&sort=age:desc
# 查询年龄age为30岁到60岁之间&倒序排列&分页显示前2条
GET /mytest/user/_search?sort=age:desc&size=2
# 查询年龄age为30岁到60岁之间&倒序排列&分页显示:从第3条开始查2条
GET /mytest/user/_search?sort=age:desc&from=2&size=2
3.3 DSL语言查询与过滤
3.3.1 什么是DSL语言
1、ES中的查询请求有两种方式: (1)简易版的查询 (2)使用JSON完整的请求体,叫做结构化查询(DSL) 2、由于DSL查询更为直观也更为简易,所以大都使用这种方式。 3、DSL查询是POST过去一个JSON,由于POST的请求是JSON格式的,所以存在很多灵活性,也有很多形式。3.3.2 具体查询示例
1、term查询:精确匹配,不会做分词匹配GET mytest/user/_search
{
"query": {
"term": {
"name": "xy"
}
}
}
GET mytest/user/_search
{
"query": {
"match": {
"car": "奥迪"
}
}
}
GET mytest/user/_search
{
"query": {
"match": {
"car": "奥迪a4l"
}
}
}
GET mytest/user/_search
{
"query": {
"match": {
"car": "a4l"
}
}
}
GET mytest/user/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"car": "奥迪"
}
}
}
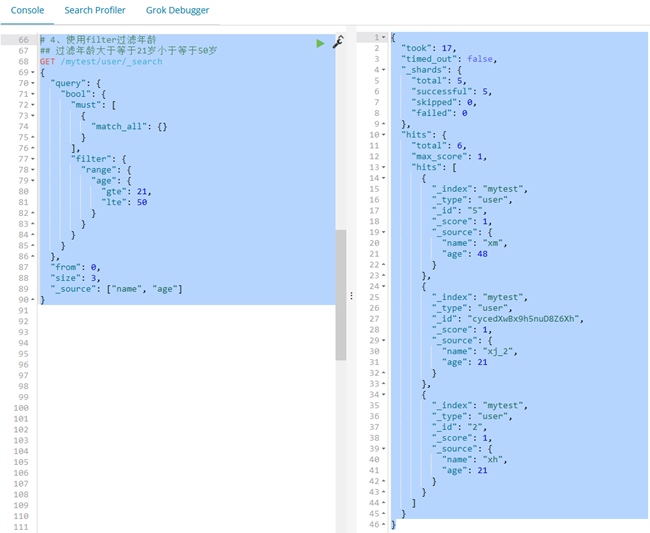
GET /mytest/user/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"range": {
"age": {
"gte": 21,
"lte": 50
}
}
}
}
},
"from": 0,
"size": 3,
"_source": ["name", "age"]
}
# 结果
{
"took": 17,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 6,
"max_score": 1,
"hits": [
{
"_index": "mytest",
"_type": "user",
"_id": "5",
"_score": 1,
"_source": {
"name": "xm",
"age": 48
}
},
{
"_index": "mytest",
"_type": "user",
"_id": "cycedXwBx9h5nuD8Z6Xh",
"_score": 1,
"_source": {
"name": "xj_2",
"age": 21
}
},
{
"_index": "mytest",
"_type": "user",
"_id": "2",
"_score": 1,
"_source": {
"name": "xh",
"age": 21
}
}
]
}
}
4. ElasticsearchIK分词器原理(重点)
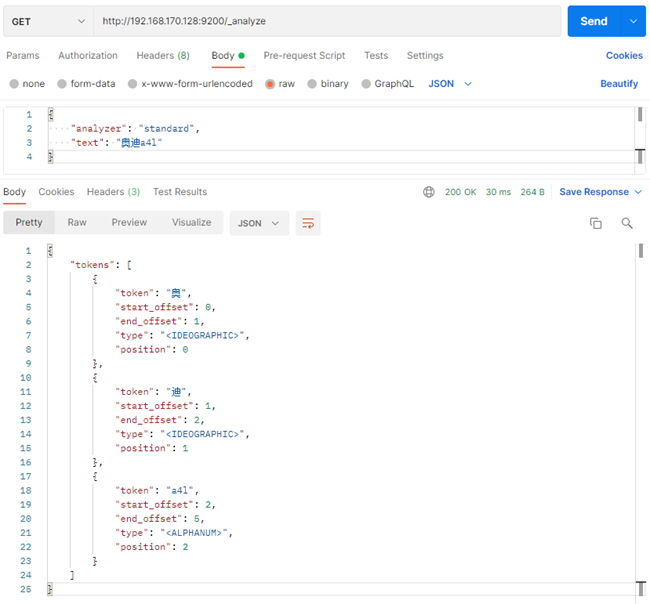
4.1 传统分词器原理
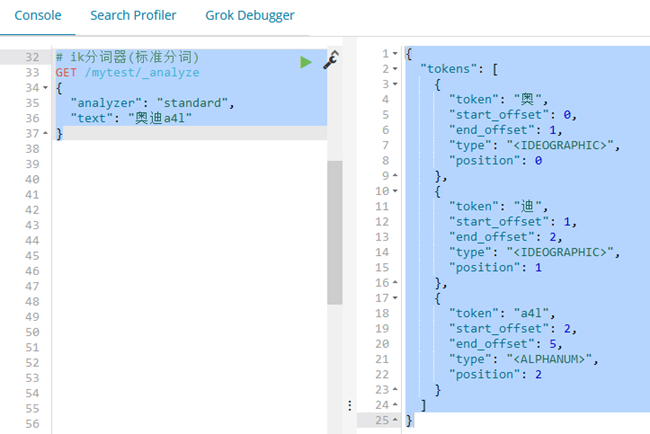
默认分词器:文字按单个字为一个单词,英文可以以一个单词为单词http://192.168.170.128:9200/_analyze
{
"analyzer": "standard",
"text": "奥迪a4l"
}
# 结果
{
"tokens": [
{
"token": "奥",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "迪",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "a4l",
"start_offset": 2,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 2
}
]
}
5. ElasticsearchIK中文分词器
5.1 为什么中文分词器
因为Elasticsearch中默认的标准分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉字作为单词。因此引入中文分词器elasticsearch-analysis-ik插件5.2 中文分词器下载安装
5.2.1 下载地址
https://github.com/medcl/elasticsearch-analysis-ik/releases 注意:es-ik分词插件的版本一定要和es安装的版本对应。5.2.2 安装步骤
(1)将下载es的IK插件,解压并重命名为ik (2)上传到/usr/local/elasticsearch-6.4.3/plugins/ (3)重启elasticsearch 检查安装结果: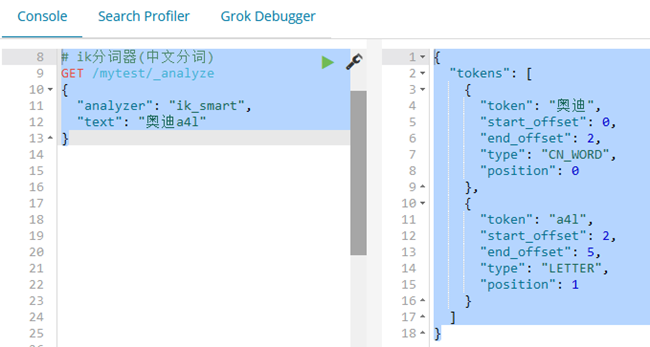
6. IK自定义中文词典热词
步骤: 1、打开ik配置文件目录:cd /usr/local/elasticsearch-6.4.3/plugins/ik/config/ 2、新建文件:touch custom/new_word.dic 3、添加分词:vi custom/new_word.dic 王者荣耀 一带一路 4、修改配置文件:vi IKAnalyzer.cfg.xml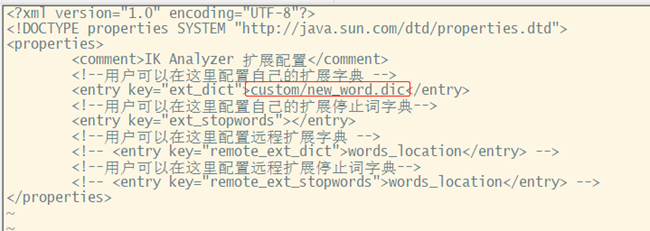 5、重启elasticsearch
在重启日志中可以看到加载了new_word.dic
5、重启elasticsearch
在重启日志中可以看到加载了new_word.dic
 6、测试
6、测试
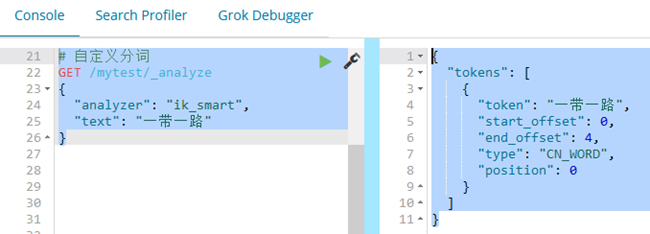
7. Elasticsearch Mapping映射
7.1 文档映射的概念
已经把ElasticSearch的核心概念和关系数据库做了一个对比,索引(index)相当于数据库,类型(type)相当于数据表,映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。 文档映射就是给文档中的字段指定字段类型、分词器。 使用GET /mymayikt/user/_mapping7.2 映射的分类
7.2.1 动态映射
我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。7.2.1 静态映射
在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。 自动映射类型:PUT /mytest/user/1
{
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
# 文档映射
POST /mytest/_mapping/user
{
"user": {
"properties": {
"age": {
"type": "integer"
},
"sex": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"car": {
"type": "keyword"
}
}
}
}
 报错:不能给已经创建好并且有内容的索引添加映射类型。
新建一个索引,再设置映射:
报错:不能给已经创建好并且有内容的索引添加映射类型。
新建一个索引,再设置映射:
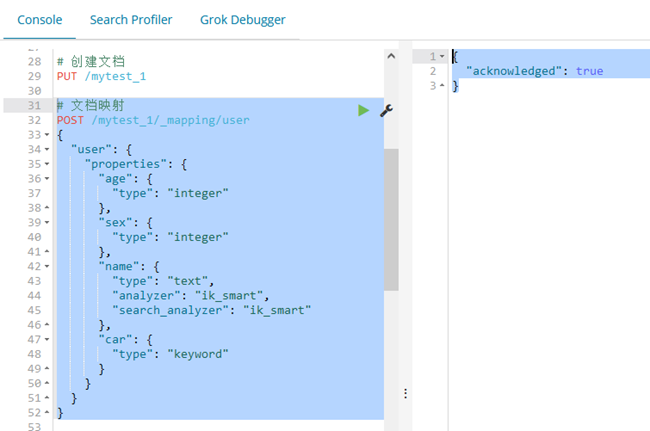
# 创建文档
PUT /mytest_1
# 文档映射
POST /mytest_1/_mapping/user
{
"user": {
"properties": {
"age": {
"type": "integer"
},
"sex": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"car": {
"type": "keyword"
}
}
}
}
# 插入数据
PUT /mytest_1/user/1
{
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
PUT /mytest_1/user/2
{
"name": "xh",
"age": 21,
"sex": 1,
"car": "保时捷911"
}
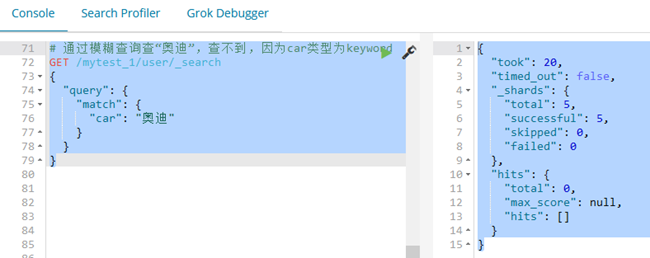
# 通过模糊查询查“奥迪”,查不到,因为car类型为keyword
GET /mytest_1/user/_search
{
"query": {
"match": {
"car": "奥迪"
}
}
}
# 修改文档映射类型(不可以直接修改,先删除索引再重新创建)
DELETE /mytest_1
PUT /mytest_1
POST /mytest_1/_mapping/user
{
"user": {
"properties": {
"age": {
"type": "integer"
},
"sex": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"car": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
# 插入数据
PUT /mytest_1/user/1
{
"name": "xj",
"age": 21,
"sex": 0,
"car": "奥迪a6l"
}
PUT /mytest_1/user/2
{
"name": "xh",
"age": 21,
"sex": 1,
"car": "保时捷911"
}
PUT /mytest_1/user/3
{
"name": "xx",
"age": 23,
"sex": 0,
"car": "奥迪a4l"
}
# 再次通过模糊查询查“奥迪”,能查到2条,因为car类型改为了text
GET /mytest_1/user/_search
{
"query": {
"match": {
"car": "奥迪"
}
}
}
7.3 ES支持的数据类型
7.3.1 基本类型
字符串:string,string类型包含 text 和 keyword。 text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。 keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)。 注意: keyword类型不能分词,Text类型可以分词查询 数值型:long、integer、short、byte、double、float 日期型:date 布尔型:boolean 二进制型:binary 数组类型(Array datatype)7.3.2 复杂类型
地理位置类型(Geo datatypes) 地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标 地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状7.3.3 特定类型(Specialised datatypes)
Pv4 类型(IPv4 datatype):ip 用于IPv4 地址 Completion 类型(Completion datatype):completion 提供自动补全建议 Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少 mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值 附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等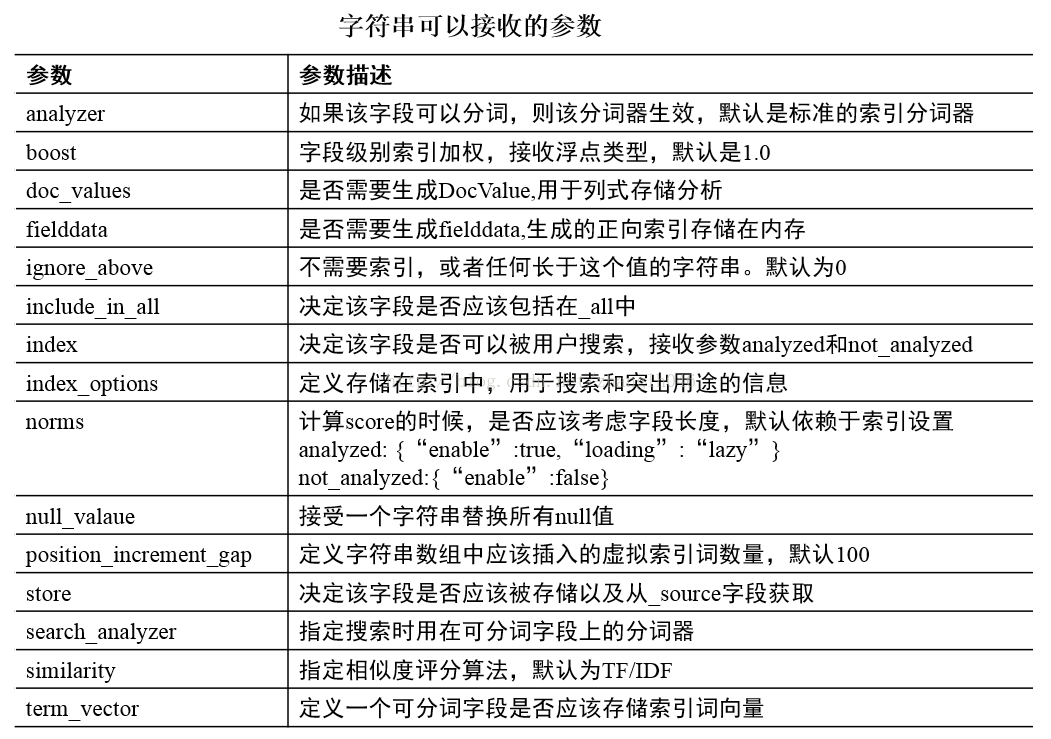 Analyzer 索引分词器,索引创建的时候使用的分词器 比如ik_smart
Search_analyzer 搜索字段的值时,指定的分词器
Analyzer 索引分词器,索引创建的时候使用的分词器 比如ik_smart
Search_analyzer 搜索字段的值时,指定的分词器
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

