Flink基于两阶段聚合及Roaringbitmap的实时去重方案
去重是大数据计算中的常见场景,本文介绍了Flink结合数据倾斜问题的一般性解决方案——两阶段聚合,以及位图(Bitmap)的优化版数据结构——Roaringbitmap给出的一种实时去重解决方案,并在最后与其他方案进行了对比。
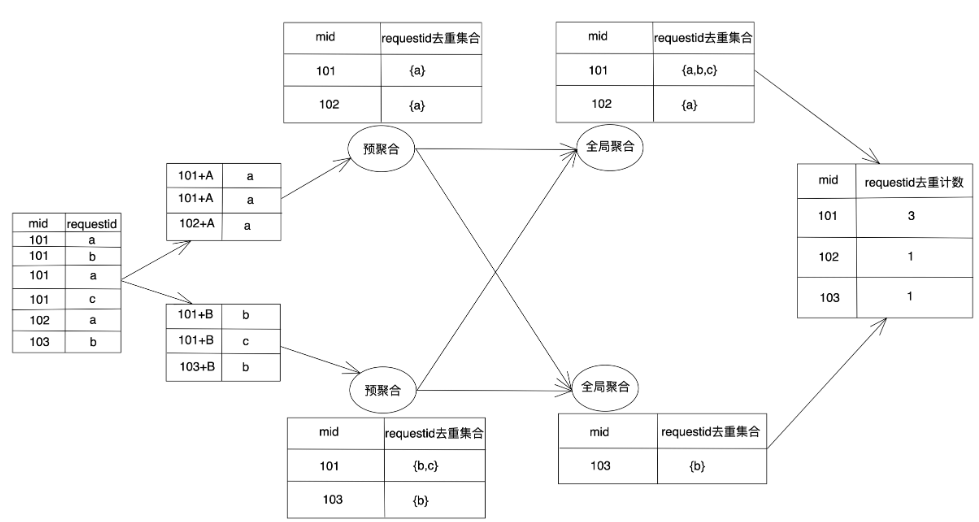
即按照媒体应用id(mid)及时间分钟维度分组聚合,对request_id及request_id+creative_id进行去重统计,还有对ad_count进行累加等指标。
在实现方式上,我们选择了JAR的方式。若简单地按mid分组(keyBy()),结合具体业务场景分析,不同媒体应用的请求量差异较大,某个媒体的请求数据会分发到集群中特定的一个节点,则大媒体的请求数据会集中于某一个节点上,造成该节点处理的数据量过大,也就是我们通常所说的数据倾斜问题。从实际的Flink UI监控中能很清晰地印证上述分析,同一时刻的不同SubTask接收到的数据量差异极大:
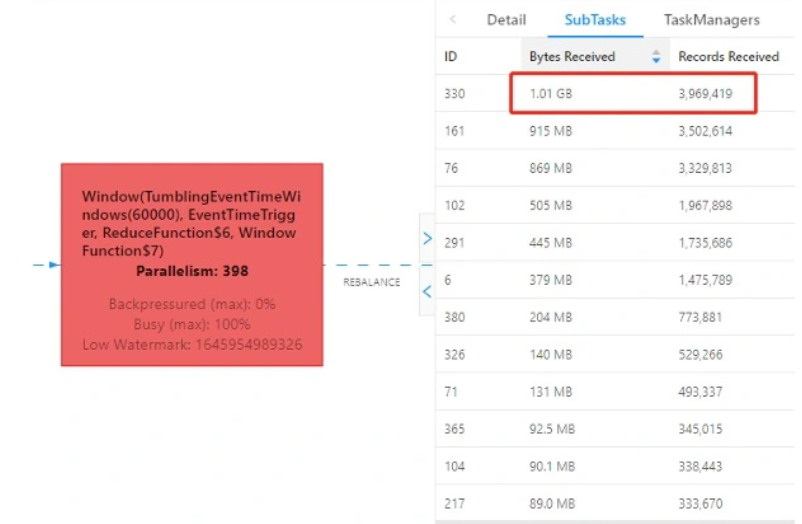
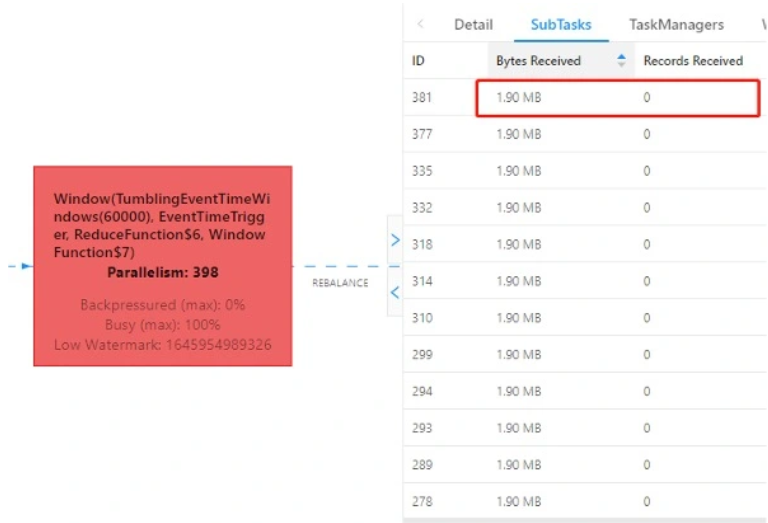
遇到分组后的数据倾斜问题,有通用的解决方案——两阶段聚合,其实现原理为:将原本相同的key通过附加随机数的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去掉随机数,再次进行全局聚合,就可以得到最终的正确结果。具体到我们的实时场景,在第一次调用keyBy()的key中增加一个随机数,将数据随机打散后开一分钟滚动窗口使用ReduceFunction()聚合,并在第一阶段局部聚合后在WindowFunction()中得到窗口结束时间标识该条预聚合数据属于哪个窗口,在第二阶段全局聚合再次调用keyBy()分组时根据窗口结束时间(以及其他所需的分组维度字段,如此处的mid)将属于同一窗口的数据分发到一个并行度处理,具体处理中使用到了ReducingState做聚合并注册了1s的定时器等待所有上游算子预聚合结果到达。大致流程如下图所示:
从上表可见,Hashset、Bitmap及HyperLogLog都无法以较低的内存占用支持精确去重。那么有没有一种数据结构既支持精确去重占用的内存又较小呢?有的,这便是下面要介绍的Roaringbitmap。
图中示出了三个container:
接着只需要在第一阶段聚合之前针对每个需要去重的指标在DataStream API中定义数据的Java Bean(即DataStream<T>的泛型)中创建一个对应的Roaringbitmap存放需要去重的字段即可。如此处需求中的request_count和response_ad_count,我们可以在Java Bean中创建如下两个属性去表示:
然后在将每条数据封装进Java Bean的时候将需要去重的字段放入对应Roaringbitmap中,如下所示:
注意到这里需要去重的request_id和creative_id实际数据为String类型,故将高运算性能、低碰撞率的MurmurHash3 32位版本封装成了如下哈希函数将String映射为int(Roaringbitmap存放的是int类型数据):
在后续使用ReduceFunction()聚合时将两条数据的Roaringbitmap合并到一起,代码如下(t1,t2为两条数据对应的Java Bean):
因为在前后两阶段聚合对应的算子间传递数据时需要序列化与反序列化,故在第一阶段聚合后WindowFunction()中调用上文提到的optimize优化Roaringbitmap的内存占用(以下t均为一条数据对应的Java Bean):
最后在第二阶段全局聚合后取出Roaringbitmap中被设置为1的比特数量(基数)即为所求取的去重计数指标:
使用上述方案在我们平台上实际跑动业务,资源消耗及能稳定支撑的数据量如下:
大数据去重的两种思路
我们知道,离线大数据计算有很多框架,如hive、spark-sql、clickhouse、impala、kylin、presto等等,各个框架在处理去重计数即count distinct的思路是不同的。大多数框架如hive、impala、clickhouse、presto、kylin等都是使用基于内存的计算,即在内存中使用某些具备去重能力的数据结构完成全局去重及计数,这也是本文将采用的思路(下称内存方案)。而spark-sql并非是在内存中对字段进行去重及计数,而是先对字段进行去重,然后再进行计数(下称非内存方案)。延伸到实时去重场景,spark这种非内存的count distinct计算方式已有文章介绍,本文将采用基于内存的计算来实现实时去重的需求,在文章最后也会对这两者做个对比。需求场景介绍
在具体分析方案之前,对我们面对的需求场景做一个简要的介绍。我们的数据BI看板中有一个请求主题实时需求,可以简化抽象成如下sql:SELECT
TUMBLE_START(timestamp, INTERVAL '1' MINUTE) AS timestamp,
mid,
count(distinct request_id) AS request_count,
count(distinct request_id + creative_id) AS response_ad_count,
sum(ad_count) AS ad_count
FROM
t
GROUP BY
TUMBLE(timestamp, INTERVAL '1' MINUTE),
mid图1-1 某一时刻按接收到的字节数逆序排列第一的SubTask
图1-2 同一时刻按接收到的字节数顺序排列第一的SubTask
图2 两阶段聚合解决数据倾斜问题
去重数据结构选择
解决了数据倾斜问题后,既然选择了基于内存计算来实现去重统计,我们接下来就需要考虑数据结构的选择问题。注意到前述的两阶段聚合过程中第一阶段算子处理后的数据会经过再次分组分发到下游第二阶段算子,这其中涉及网络传输,必然有数据的序列化和反序列化过程,因此内存占用大小是考虑因素之一。同时去重统计也分为精确去重和非精确去重,同时考虑这两点,思考哪些数据结构具备去重能力,我们会很自然地想到以下这些:|
数据结构
|
是否支持精确去重
|
内存占用(序列化及反序列化成本)
|
|---|---|---|
|
HashSet
|
是
|
高
|
|
Bitmap
|
是
|
中
|
|
HyperLogLog
|
否
|
低
|
Roaringbitmap介绍
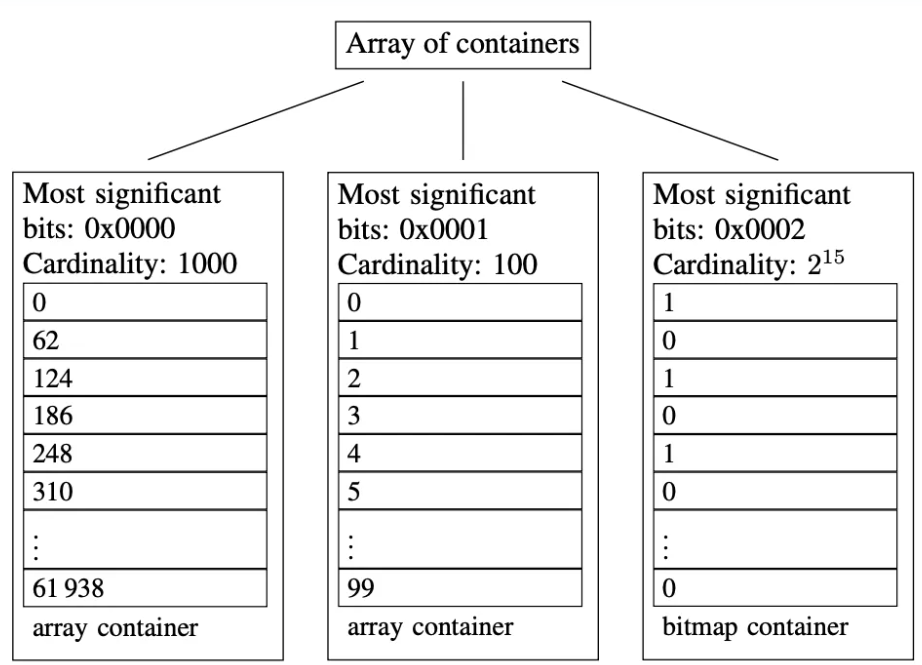
上文提到,Bitmap支持精确去重,其思想为:第0个比特表示数字0,第1个比特表示数字1,以此类推。如果某个数位于集合内,就将它对应的位图内的比特置为1,否则保持为0。将集合中的数对应的位图中的比特依次置为1后,去重计数即为位图中为1的比特数。位图去重有很多优点,比如内存占用较少,位操作效率高等,但是不管业务中实际的元素基数有多少,它占用的内存空间都恒定不变,数据越稀疏,空间浪费越严重。 而Roaringbitmap是bitmap的一种优化算法,它于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出,官网在这里。它的主要思路是:将32位无符号整数按照高16位分桶,即最多可能有216=65536个桶,论文内称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中。也就是说,一个Roaringbitmap就是很多container的集合。可以借助论文中的示例图加以理解:
图3 Roaringbitmap中的container介绍
- 高16位为0000H的container,存储有前1000个62的倍数。
- 高16位为0001H的container,存储有[216, 216+100)区间内的100个数。
- 高16位为0002H的container,存储有[2×216, 3×216)区间内的所有偶数,共215个。
- 当桶内数据的基数不大于4096时会采用ArrayContainer存储,其本质上是一个unsigned short类型的有序数组,时间复杂度为O(logN),空间复杂度与基数(c)有关,为(2 + 2c)B。
- 当桶内数据的基数大于4096时会采用BitmapContainer存储,其本质上是一个长度固定为1024的unsigned long型数组表示的普通位图,时间复杂度为O(1),空间复杂度恒定为8192B。
- RunContainer使用可变长度的unsigned short数组存储用行程长度编码(RLE)压缩后的数据,其压缩效果可好可坏,时间复杂度为O(logN),空间复杂度与它存储的连续序列数(r)有关,为(2 + 4r)B。
结合两阶段聚合及Roaringbitmap实现实时去重
两阶段聚合在上文已经讨论过,结合Roaringbitmap实现实时去重方案首先需要导入相关Maven依赖:<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>0.9.21</version>
</dependency>RoaringBitmap request_count_bitmap = new RoaringBitmap();
RoaringBitmap response_ad_count_bitmap = new RoaringBitmap();request_count_bitmap.add(hashToInt(sspRequest.getRequest_id()));
response_ad_count_bitmap.add(hashToInt(sspResponse.getRequest_id() + sspResponse.getCreative_id()));public static int hashToInt(String str) {
return Hashing.murmur3_32().hashString(str, Charsets.UTF_8).asInt();
}t1.getRequest_count_bitmap().or(t2.getRequest_count_bitmap());
t1.getResponse_ad_count_bitmap().or(t2.getResponse_ad_count_bitmap());t.getRequest_count_bitmap().runOptimize();
t.getResponse_ad_count_bitmap().runOptimize();t.getRequest_count_bitmap().getLongCardinality();
t.getResponse_ad_count_bitmap().getLongCardinality();- CPU:20核
- 内存:80G
- TPS(条/秒):20万
后续改进及与非内存方案对比
改进:
细心的同学可能已经发现,在上述使用Roaringbitmap实现实时去重的方案中,在将需要去重的字段放入Roaringbitmap之前使用了Hash函数将String类型数据转换为int类型。Hash函数由于实现原理的问题,一定会存在一定概率的哈希冲突,那就有可能将不同的字段映射为了同一个int,尽管MurmurHash3算法碰撞率较低,但仍可能造成去重数据不准确(一定程度偏小)。如果希望精确去重的话,就需要对去重的字段维护一个全局的id mapping映射,以实现去重的字段与int值的一一映射(例如:{a:1,b:2,c:3})。后续考虑结合Redis与Redisson进行改进,基本思路是:在Redis中利用Hash数据结构(Redisson中为Rmap)保存去重字段与id(int值)的映射关系(RMap可以分片),RMap的key为去重字段,value为id。然后在Flink去重前增加一个map()算子,在该算子中尝试获取每条数据去重字段对应的id,如获取到则封装进数据并发送到下游,如获取不到则利用Redisson的锁和RAtomicLong全局生成一个自增1的id放入RMap中。 至于去重字段本身为int型的数据则直接放入Roaringbitmap即可,如若为long型也可以使用Roaringbitmap的64位版本Roaring64NavigableMap。对比:
下面谈谈本文使用的内存方案与上文提到的非内存方案的对比。首先简单介绍下非内存方案,该方案将去重计数拆分为了去重和计数两个步骤去完成。先将去重字段作为Flink keyBy()中key的一部分参与到数据分发的过程中,然后在下游各个subTask上利用Flink中的MapState中的key天然支持去重的特性对去重字段进行去重后计数:- 若某条数据的去重字段已经存在于MapState的key中则认为相同数值的去重字段(在当前时间周期内)之前已经到达,该条数据对应的去重指标赋值0并发送到下游;
- 若某条数据的去重字段未存在于MapState的key中则认为相同数值的去重字段(在当前时间周期内)之前从未到达,该条数据对应的去重指标赋值1并发送到下游;
- 在下游算子按需求中时间周期(如一分钟)进行开窗聚合计算,使用类似ReduceFunction()聚合窗口中的各条数据,累加去重指标作为最终的去重计数结果;
- 上述过程中的MapState需要注册定时器在每个时间周期结束时(如每分钟末尾)触发定时器去清理MapState中的状态数据。
- 仔细思考,非内存方案将去重字段作为key的一部分对数据进行分发,将去重字段值相同的数据分发到下游同一个节点上进行去重处理,这其中实际上恰好利用了某些业务场景下去重字段本身数据分布的随机性将倾斜数据进行均匀打散。但是假如在另一些业务场景下,去重字段本身不具备数据分布的随机性,例如我们的业务场景中需要按creative_id去重,但是实际数据中某个creative_id数据量比其他的大很多,那么该creative_id分发到的节点负载会非常高,可能造成数据倾斜并进一步造成Flink任务反压,最终导致作业重启。这里本文介绍的内存方案是使用了加随机数打散,能确保任意场景下数据分布的随机性。
- 还是因为非内存方案将去重字段作为key的一部分对数据进行分发的原因,如我们此处的业务场景,需要按多个不同字段进行去重(request_id及request_id+creative_id),那么该方案势必需要对多个不同去重字段进行keyBy(),实际上是对数据进行了分流,不同的流按各自的去重字段分别进行去重计数,最终还需要增加一步多流join的操作将多个去重指标按相同维度关联到一条结果数据中,这里多流join操作会一定程度上影响数据时效性以及准确性。内存方案对多个不同字段进行去重是在一条流中使用了多个Roaringbitmap实现的,不存在还需要多流join的情况。
- 注意到非内存方案需要保持MapState中的数据生命周期和下游窗口聚合计算的时间周期一致,如果不一致可能造成去重计数不准确(例如开一分钟窗口计算,某个MapState的生命周期从00:00:30到00:01:30,那么假设其保存的某个去重字段值只在00:00:45和00:01:15出现了,则在计算00:01:00-00:02:00的窗口该去重指标时,这个去重字段计为了0,然而正确的结果应该是1)。为了保持这种时间周期的一致,需要注册定时器在每个时间周期结束时(如每分钟末尾)清理MapState中的状态数据,这里如果Flink使用事件时间语义并允许一定程度的数据时间乱序的话,就可能造成清理MapState时将提前到达的数据清除了,造成下一周期统计不准确(例如允许5s的时间乱序,在计算00:01:00-00:02:00的窗口时在Watermark到达00:02:00前已经有事件时间为00:02:03的数据到达了)。内存方案中处理数据时间乱序是交给Flink框架的开窗操作的,可以保证允许时间乱序的情况下将数据归入正确的窗口。
- 如果去重字段不是int或者long类型,那么就需要引入外部数据库如Redis去维护全局的id mapping,在TPS(每秒数据量)较高的情况下还可能在生成全局递增id时有性能瓶颈,需要利用离线历史数据提前构建好id映射关系,成本较高。
- 内存方案使用了数据倾斜时的一般处理思路——加随机数将数据打散后两阶段聚合,会将一些中小媒体的数据也分布到第一阶段的多个节点上,在多个节点上都需要保留去重字段的原始信息维护一份局部去重数据以便第二阶段全局聚合时得到正确的结果,这里相对于非内存方案会造成一定的内存消耗。
- 非内存方案中使用了MapState进行字段去重,天然地将去重字段数据放到了状态中保存,Checkpoint或者Savepoint时会将本地状态数据保存到HDFS以便做故障恢复。内存方案则在第一阶段预聚合时没有将数据放入状态的过程,假如任务在某个时间周期内停止(例如开一分钟窗口计算,任务在00:00:30停止)并做Savepoint,那么任务从断点恢复的时候该时间周期内断点之前的数据就丢失了,造成该时间周期统计数据不准确(这里其实无论内存还是非内存方案在任务第一次启动的时候都存在这个问题,只是非内存方案在后续从断点恢复的时候可以从状态中获取某个时间周期内断点之前的数据)。
结语:
限于作者本人才疏学浅,对Flink框架及上述实时去重的两种方案还有理解不到位的地方,只是将工作中的实践经验及一些相关思考分享给大家。各位大佬如发现其中有错误,恳请批评指正,希望能在不同观点的碰撞中一起进步!正文到此结束
- 本文标签: RoaringBitmap Flink
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

