Spring Boot集成JPA快速入门demo
1.JPA介绍
JPA (Java Persistence API) 是 Sun 官方提出的 Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术,结束现在 Hibernate,TopLink,JDO 等 ORM 框架各自为营的凌乱局面。JPA 在充分吸收了现有Hibernate,TopLink,JDO 等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从上面的解释中我们可以了解到JPA 是一套规范,而类似 Hibernate,TopLink,JDO这些产品是实现了 JPA 规范。
spring Data JPA 是 Spring 基于 ORM 框架、JPA规范的基础上封装的一套 JPA 应用框架,底层使用了 Hibernate 的 JPA 技术实现,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率。
2.mysql环境搭建
参考代码仓库里面的mysql模块,这里只贴出docker-compose.ymlversion: '3'
services:
mysql:
image: registry.cn-hangzhou.aliyuncs.com/zhengqing/mysql:5.7
container_name: mysql_3306
restart: unless-stopped
volumes:
- "./mysql/my.cnf:/etc/mysql/my.cnf"
- "./mysql/init-file.sql:/etc/mysql/init-file.sql"
- "./mysql/data:/var/lib/mysql"
# - "./mysql/conf.d:/etc/mysql/conf.d"
- "./mysql/log/mysql/error.log:/var/log/mysql/error.log"
- "./mysql/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d" # init sql script directory -- tips: it can be excute when `/var/lib/mysql` is empty
environment: # set environment,equals docker run -e
TZ: Asia/Shanghai
LANG: en_US.UTF-8
MYSQL_ROOT_PASSWORD: root # set root password
MYSQL_DATABASE: demo # init database name
ports: # port mappping
- "3306:3306"docker-compose -f docker-compose.yml -p mysql5.7 up -d3.代码工程
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springboot-demo</artifactId>
<groupId>com.et</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>jpa</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
</project>entity
package com.et.jpa.entity;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GenericGenerator(name = "system-uuid", strategy = "uuid")
@GeneratedValue(generator = "system-uuid")
private String id;
private String name;
private Integer age;
private Boolean sex;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Boolean getSex() {
return sex;
}
public void setSex(Boolean sex) {
this.sex = sex;
}
}- @Entity 是一个类注解,用来注解该类是一个实体类用来进行和数据库中的表建立关联关系,首次启动项目的时候,默认会在数据中生成一个同实体类相同名字的表(table),也可以通过注解中的
name属性来修改表(table)名称, 如@Entity(name=“user”) , 这样数据库中表的名称则是user。该注解十分重要,如果没有该注解首次启动项目的时候你会发现数据库没有生成对应的表。
- @Table 注解也是一个类注解,该注解可以用来修改表的名字,该注解完全可以忽略掉不用,@Entity 注解已具备该注解的功能。
- @Id 类的属性注解,该注解表明该属性字段是一个主键,该属性必须具备,不可缺少。
- @GeneratedValue 该注解通常和 @Id 主键注解一起使用,用来定义主键的呈现形式,该注解通常有多种使用策略,先总结如下:
- @GeneratedValue(strategy= GenerationType.IDENTITY) 该注解由数据库自动生成,主键自增型,在 mysql 数据库中使用最频繁,oracle 不支持。
- @GeneratedValue(strategy= GenerationType.AUTO) 主键由程序控制,默认的主键生成策略,
oracle默认是序列化的方式,mysql默认是主键自增的方式。
- @GeneratedValue(strategy= GenerationType.SEQUENCE) 根据底层数据库的序列来生成主键,条件是数据库支持序列,
Oracle支持,Mysql不支持。
- @GeneratedValue(strategy= GenerationType.TABLE) 使用一个特定的数据库表格来保存主键,较少使用。
application.properties
spring.jpa.hibernate.ddl-auto=update
spring.datasource.url=jdbc:mysql://localhost:3306/demo?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=root
#Camel case naming automatically converts to underline
spring.jpa.hibernate.naming.physical-strategy=org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
#use mysql database
spring.jpa.database=mysql
# show sql
spring.jpa.show-sql=true
server.port=8088spring.jpa.properties.hibernate.hbm2ddl.auto有几种配置:
create:表示每次加载Hibernate时都会删除上一次生成的表(包括数据),然后重新生成新表,即使两次没有任何修改也会这样执行。适用于每次执行单测前清空数据库的场景。
create-drop:表示每次加载Hibernate时都会生成表,但当SessionFactory关闭时,所生成的表将自动删除。
update:最常用的属性值,第一次加载Hibernate时创建数据表(前提是需要先有数据库),以后加载Hibernate时不会删除上一次生成的表,会根据实体更新,只新增字段,不会删除字段(即使实体中已经删除)。
validate:每次加载Hibernate时都会验证数据表结构,只会和已经存在的数据表进行比较,根据model修改表结构,但不会创建新表。
- 不配置此项,表示禁用自动建表功能
spring.jpa.show-sql=true 该配置当在执行数据库操作的时候会在控制台打印 sql 语句,方便我们检查排错等。
controller
package com.et.jpa.controller;
import com.et.jpa.entity.User;
import com.et.jpa.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
public class HelloWorldController {
@Autowired
private UserRepository userRepository;
@RequestMapping("/hello")
@ResponseBody
public Map<String, Object> showHelloWorld(){
Map<String, Object> map = new HashMap<>();
map.put("msg", "HelloWorld");
return map;
}
@RequestMapping("/add")
public User add(String name){
User user = new User();
user.setName(name);
return userRepository.save(user);
}
@RequestMapping("/list")
public Iterable<User> list(){
Iterable<User> all = userRepository.findAll();
return all;
}
}repository
package com.et.jpa.repository;
import com.et.jpa.entity.User;
import org.springframework.data.repository.CrudRepository;
public interface UserRepository extends CrudRepository<User, String> {
}代码仓库
4.测试
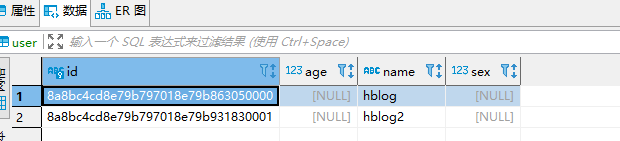
启动spring boot应用,会自动创建表,查看控制台如下:Hibernate: create table user (id varchar(255) not null, age integer, name varchar(255), sex bit, primary key (id)) engine=MyISAM访问http://127.0.0.1:8088/add?name=hblog2,插入一条记录。控制台输出
Hibernate: insert into user (age, name, sex, id) values (?, ?, ?, ?)访问http://127.0.0.1:8088/list,查询表中数据,控制台输出
Hibernate: select user0_.id as id1_0_, user0_.age as age2_0_, user0_.name as name3_0_, user0_.sex as sex4_0_ from user user0_
5.引用
正文到此结束
- 本文标签: Spring Boot JPA
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

