mysql三种读取模式(普通、流式、游标)
在与MySQL数据库交互时,数据的读取方式有多种选择,包括流式读取、游标读取和普通读取。每种方式都有其独特的原理、优势和劣势。本文将对这三种读取方式进行详细介绍,
1. 普通读取
介绍
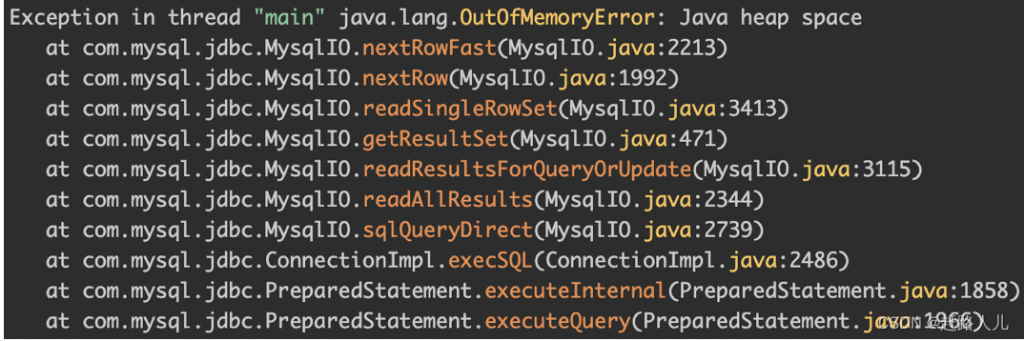
普通读取是指通过JDBC的Statement或PreparedStatement执行SQL查询,JDBC驱动会阻塞的一次性读取全部查询的数据到 JVM 内存中。这种方式适用于小型数据集的读取。
原理
在普通读取中,当执行查询时,JDBC会将整个结果集从数据库加载到内存中。开发者可以通过ResultSet对象逐行访问数据。
示例代码
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
String url = "jdbc:mysql://localhost:3307/test?useSSL=false";
connection = DriverManager.getConnection(url, user, password);
statement = connection.createStatement();
resultSet = statement.executeQuery("SELECT * FROM table_name");
while (resultSet.next()) {
System.out.println(resultSet.getString("column_name"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// close
if (resultSet != null) resultSet.close();
if (statement != null) statement.close();
if (connection != null) connection.close();
}优势
- 简单易用:代码结构简单,易于理解和使用。
- 适合小数据集:对于小型数据集,性能良好,读取速度快。
劣势
- 内存消耗:对于大型数据集,可能导致内存消耗过大,甚至引发
OutOfMemoryError。 - 不适合实时处理:无法实时处理数据,需等待整个结果集加载完成。
2. 游标读取
介绍
游标读取是指通过JDBC的Statement或PreparedStatement使用游标逐行读取数据。游标允许在结果集中移动,适合处理较大的数据集。
原理
游标读取通过在数据库中维护一个指向结果集的指针,允许逐行访问数据。每次读取一行数据,游标向前移动,直到结果集结束。
示例代码
- 在连接参数中需要拼接useCursorFetch=true;
- 创建Statement时需要设置ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY
- 设置fetchSize控制每一次获取多少条数据
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
String url ="jdbc:mysql://localhost:3307/test?useSSL=false&useCursorFetch=true";
connection = DriverManager.getConnection(url, user, password);
preparedStatement = connection.prepareStatement("SELECT * FROM table_name", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
preparedStatement.setFetchSize(100); //set fetchSize
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("column_name"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// close reources
if (resultSet != null) resultSet.close();
if (preparedStatement != null) preparedStatement.close();
if (connection != null) connection.close();
}优势
- 内存效率:只在内存中保留当前行,适合处理大型数据集。
- 逐行处理:可以逐行读取和处理数据,适合实时数据处理场景。
劣势
- 复杂性:相较于普通读取,代码结构稍复杂。
- 性能开销:在某些情况下,逐行读取可能会导致性能下降。
游标查询需要注意的点:
由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时空间来存放需要拿走的数据。因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:- IOPS飙升 (IOPS (Input/Output Per Second):磁盘每秒的读写次数)
- 磁盘空间飙升
- 客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数据
- 在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS由“读写”转变为“读取”。
- CPU和内存会有一定比例的上升
3. 流式读取
介绍
流式读取是指通过JDBC的Statement或PreparedStatement以流的方式读取数据,适合处理非常大的数据集。
原理
流式读取通过设置ResultSet的类型和并发模式,允许在不将整个结果集加载到内存的情况下,逐行读取数据。通常结合setFetchSize()方法来控制每次从数据库中获取的行数。
示例代码
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
String url = "jdbc:mysql://localhost:3307/test?useSSL=false";
connection = DriverManager.getConnection(url, user, password);
preparedStatement = connection.prepareStatement("SELECT * FROM table_name", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
preparedStatement.setFetchSize(1000); // 设置每次读取的行数
//OR USEING com.mysql.jdbc.StatementImpl
//((StatementImpl) statement).enableStreamingResults();
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("column_name"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (resultSet != null) resultSet.close();
if (preparedStatement != null) preparedStatement.close();
if (connection != null) connection.close();
}优势
- 极高的内存效率:适合处理超大数据集,内存占用极低。
- 实时处理能力:可以实时处理数据,适合流式数据分析。
劣势
- 复杂性:实现相对复杂,需要合理设置
fetch size。 - 性能问题:在某些情况下,频繁的数据库访问可能导致性能下降。
流式查询应该注意的坑
WARN ] 2024-12-26 09:36:50.365 [] job-file-log-676bc326966a463e08520799 - [srtosr][sr35] - Query 'his_config_info_exp' snapshot row size failed: java.lang.RuntimeException: io.tapdata.flow.engine.V2.exception.node.NodeException: Query table 'his_config_info_exp' count failed: No operations allowed after connection closed.
java.util.concurrent.CompletionException: java.lang.RuntimeException: io.tapdata.flow.engine.V2.exception.node.NodeException: Query table 'his_config_info_exp' count failed: No operations allowed after connection closed.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java:1643)
at java.util.concurrent.CompletableFuture$AsyncRun.exec(CompletableFuture.java:1632)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)MySQL Connector/J 5.1 Developer Guide中原文:
There are some caveats with this approach. You must read all of the rows in the result set (or close it) before you can issue any other queries on the connection, or an exception will be thrown. 也就是说当通过流式查询获取一个ResultSet后,通过next迭代出所有元素之前或者调用close关闭它之前,不能使用同一个数据库连接去发起另外一个查询,否者抛出异常(第一次调用的正常,第二次的抛出异常)。总结
在选择MySQL的数据读取方式时,需要根据具体的应用场景和数据集大小来决定:
- 普通读取适合小型数据集,简单易用,但内存消耗较大。
- 游标读取适合中型数据集,内存效率较高,逐行处理。
- 流式读取适合超大数据集,内存占用极低,实时处理能力强,但实现复杂。
根据实际需求,选择合适的读取方式可以提高应用程序的性能和可扩展性。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

