【实战】五个Docker监控工具的对比
【编者的话】这篇文章作者是Usman,他是服务器和基础架构工程师,在各种云平台上构建大规模分布式服务有丰富的经验。该篇文章主要分析评估了五种Docker监控工具:Docker Stats、CAdvisor、Scout、Data Dog以及Sensu。还有另外两个工具:Prometheus与Sysdig Cloud会在下一篇做介绍分析,请读者敬请期待。你可以在 techtraits.com 阅读他的更多文章,或者在twitter上添加他 @usman_ismail 或是在 GitHub 。
由于一些大型部署使用的是Docker,因此获取Docker环境的状态与健康的可视化就显得尤为重要了。在这篇文章中,我的目标是重温一些用来监测容器的常用工具。我会基于以下标准来评估这些工具:
1. 易于部署
2. 呈现信息的详细级别
3. 整个部署信息的综合水平
4. 可以从数据生成警报
5. 可以监测非Docker的资源
6. 成本
虽然这个名单不是很全面,但是我试图强调的是最常用的工具以及优化此六项评估标准的工具。
Docker Stats命令
文中的所有命令都专门在亚马逊网络服务EC2上运行的RancherOS实例上测试过。不过,今天所提到的工具应该在任何Docker部署上都能使用。
我将讨论的第一个工具是Docker本身。你可能不知道Docker客户端已经提供了基本的命令行工具来检查容器的资源消耗。想要查看容器统计信息只需运行 docker stats [CONTAINER_NAME] 。这样就可以查看每个容器的CPU利用率、内存的使用量以及可用内存总量。请注意,如果您没有对容器限制内存,那么该命令将显示您的主机的内存总量。但它并不意味着你的每个容器都能访问那么多的内存。另外你还能看到由容器通过网络发送和接收的数据总量。
$ docker stats determined_shockley determined_wozniak prickly_hypatia
CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
determined_shockley 0.00% 884 KiB/1.961 GiB 0.04% 648 B/648 B
determined_wozniak 0.00% 1.723 MiB/1.961 GiB 0.09% 1.266 KiB/648 B
prickly_hypatia 0.00% 740 KiB/1.961 GiB 0.04% 1.898 KiB/648 B
对于更详细的容器统计信息还可以使用Docker远程API 通过netcat来查看(见下文)。发送一个HTTP GET请求 /containers/[CONTAINER_NAME] ,其中 CONTAINER_NAME 是你想要统计的容器名称。你可以从 这里 看到一个容器统计请求的详细信息。在上述的例子中你会得到缓存、交换空间以及内存的详细信息。如果要了解什么是metrics,那么你就需要精读Docker文档的 Run Metrics部分 。
评分:
1. 易于部署程度:※※※※※
2. 信息详细程度:※※※※※
3. 集成度:无
4. 生成警报的能力:无
5. 监测非Docker的资源的能力:无
6. 成本:免费
CAdvisor
Docker stats 命令和远程API用于命令行上的信息获取,但是,如果您想要在图形界面中访问信息,那么你就需要一个工具,如 CAdvisor 。CAdvisor提供了早前Docker stats命令所显示的数据的可视化界面。运行以下Docker命令,在浏览器里访问 http://<your-hostname>:8080/ 可以看到CAdvisor的界面。你将看到一些图标包括:全部CPU的使用率、内存使用率、网络吞吐量以及磁盘空间利用率。然后,您可以通过点击在网页顶部的 Docker Containers 链接,然后选择某个容器去深入了解此容器的使用情况统计。除了这些统计信息,CAdvisor还显示容器的限制,如果有的话,被放置在容器中,用分离部。
docker run /
--volume=/:/rootfs:ro /
--volume=/var/run:/var/run:rw /
--volume=/sys:/sys:ro /
--volume=/var/lib/docker/:/var/lib/docker:ro /
--publish=8080:8080 /
--detach=true /
--name=cadvisor /
google/cadvisor:latest

CAdvisor是有用且很容易设置的工具,我们可以不用ssh就能连接到服务器来查看资源的消耗,而且它还给我们生成了图表。此外,当群集需要额外的资源时,压力表提供了快速预览。而且,与本文中的其他的工具不一样的是CAdvisor是免费的,因为它是开源的,同时它运行已配置群集的硬件上,最后,除了一些进程资源,CAdvisor并没有额外的消耗成本。但是,它有它的局限性;它只能监控一个Docker主机,因此,如果你有一个多节点部署,那么统计数据将是不相交的而且分散你的集群。值得注意的是,如果你使用的是Kubernetes,你可以使用 heapster 来监控多节点集群。在图表中的数据仅仅是时长一分钟的移动窗口,并没有方法来查看长期趋势。如果资源使用率在危险水平,它却没有生成警告的机制。如果在Docker节点的资源消耗方面,你没有任何可视化界面,那么CAdvisor是一个不错的开端来带你步入容器监控,然而如果你打算在你的容器中运行任何关键任务,那么更强大的工具或者方法是必要的。需要注意的是 Rancher 在每个连接的主机上运行CAdvisor,并通过UI公开了一组有限的统计数据,并且通过API公开了所有的系统统计数据。
评分:(忽略了heapster,因为它仅支持Kubernetes)
1. 易于部署程度:※※※※※
2. 信息详细程度:※※
3. 集成度:※
4. 生成警报的能力:无
5. 监测非Docker的资源的能力:无
6. 成本:免费
Scout
下一个Docker监控的方法是Scout,它解决了几个CAdvisor的局限。 Scout是聚合来自多个主机和容器的托管监控服务并且它有更长时间的数据呈现。它也可以基于这些指标生成警报。要获取Scout并运行,第一步,在 scoutapp.com 注册一个Scout帐户,免费的试用账号足以用来集成测试。一旦你创建了自己的帐户并登录,点击右上角您的帐户名称,然后点击Account Basics来查看你的Account Key,你需要这个Key从我们的Docker服务器来发送指标。
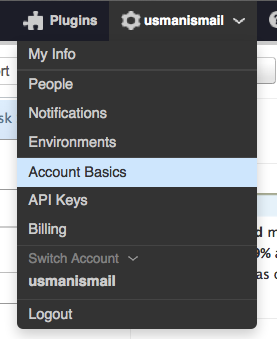
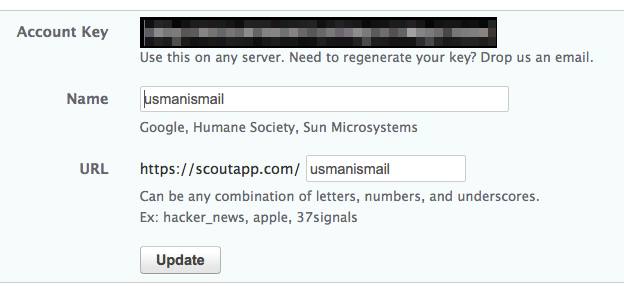
现在在你的主机上,创建一个名为scouts.yml的文件并将下面的文字复制到该文件中,用上边得到的Key替换到account_key。您可以对主机指定任何有意义的变量:display_name、environment与roles等属性。当他们在scout界面上呈现时,这些将用于分离各种指标。我假设有一组网站服务器列表正在运行Docker,它们都将采用如下图所示的变量。
account_key is the only required value
account_key: YOUR_ACCOUNT_KEY
hostname: web01-host
display_name: web01
environment: production
roles: web
现在,你可以使用scout配置文件通过Docker-scout插件来运行scout。
docker run -d --name scout-agent /
-v /proc:/host/proc:ro /
-v /etc/mtab:/host/etc/mtab:ro /
-v /var/run/docker.sock:/host/var/run/docker.sock:ro /
-v `pwd`/scoutd.yml:/etc/scout/scoutd.yml /
-v /sys/fs/cgroup/:/host/sys/fs/cgroup/ /
--net=host --privileged /
soutapp/docker-scout
这样你查看Scout网页就能看到一个条目,其中display_name参数(web01)就是你在scoutd.yml里面指定的。

如果你点击它(web01)就会显示主机的详细信息。其中包括任何运行在你主机上的进程计数、cpu使用率以及内存利用率,值得注意的是在docker内部并没有进程的限制。
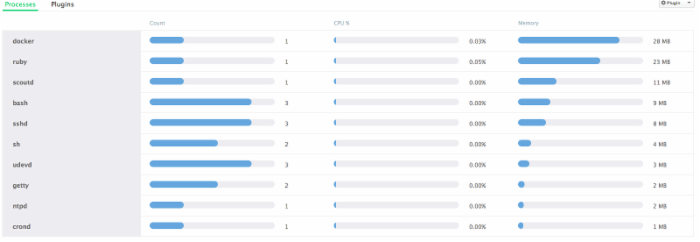
如果要添加Docker监控服务,需要单击Roles选项卡,然后选择所有服务。现在点击+插件模板按钮,接下来的Docker监视器会加载详细信息视图。一旦详细信息呈现出来,选择安装插件来添加到您的主机。接着会给你提供一个已安装插件的名称以及需指定要监视的容器。如果该字段是空的,插件将监控主机上所有的容器。点击完成按钮,一分钟左右你就可以在[Server Name] > Plugins中看到从Docker监控插件中获取的详细信息。该插件为每个主机显示CPU使用率、内存使用率、网络吞吐量以及容器的数量。
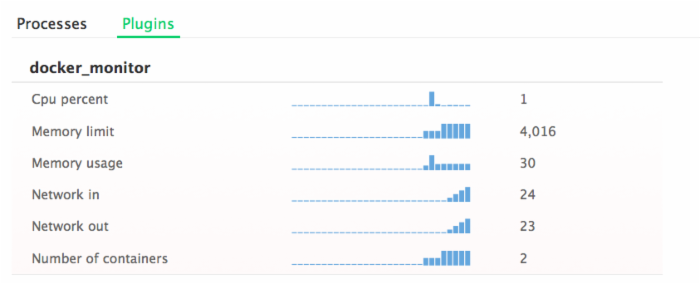
你点击任何一个图表,都可以拉取该指标的详细视图,该视图可以让你看到时间跨度更长的趋势。
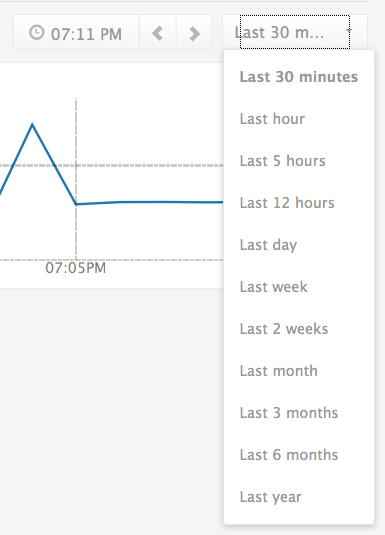
该视图还允许您过滤基于环境和服务器角色的指标。此外,您可以创建“Triggers”或警报,如果指标高于或低于配置的阈值它就给你发送电子邮件。这就允许您设置自动警报来通知您,比如,如果你的一些容器异常关闭以及容器计数低于一定数量。您还可以设置对平均CPU利用率的警报,举例来说,如果你正在运行的容器超过CPU利用率而发热,你会得到一个警告,当然你可以开启更多的主机到你的Docker集群。
要创建触发器,请选择顶部菜单的Roles>All Servers,然后选择plugins部分的Docker monitor。然后在屏幕的右侧的Plugin template Administration菜单里选择triggers。您现在应该看到一个选项“Add a Trigger”,它将应用到整个部署。
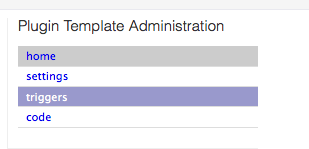
下面是一个触发器的例子,如果部署的容器数量低于3就会发出警报。
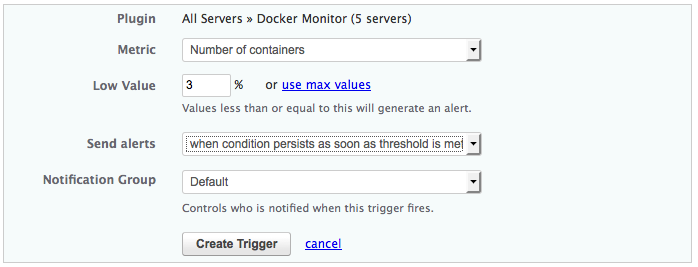
它的创建是为“所有的服务器”,当然你也可以用不同的角色标记你的主机使用服务器上创建的scoutd.yml文件。使用角色。你可以通过使用不同角色来应用触发器到部署的服务器的一个子集上。例如,你可以设置一个当在你的网络的节点的容器数量低于一定数量时的警报。即使是基于角色的触发器我仍然觉得Scout的警报系统可能做的更好。这是因为许多Docker部署具有相同主机上的多种多样的容器。在这种情况下为特定类型的容器设置触发器将是不可能的由于角色被应用到主机上的所有容器。
比起CAdvisor,使用Scout的另一个优点是,它有 大量的插件 ,除了Docker信息他们可以吸收其他有关你的部署的数据。这使得Scout是你的一站式监控系统,而无需对系统的各种资源来安装各种不同的监控系统。
Scout的一个缺点是,它不显示有关每个主机上像CAdvisor的单独容器的详细信息。这是个问题,如果你在同一台服务器上运行大量的容器。例如,如果你想有一个触发器来提醒您的Web容器的警报,但不是Jenkins容器,这时Scout就无法支持该情况。尽管有这个缺点,Scout还是一个相当有用的工具来监控你的Docker部署。当然这要付出一些代价,每个监控的主机十美元。如果你要运行一个有多台主机的超大部署,这个代价会是个考虑因素。
评分:
1. 易于部署程度:※※※※
2. 信息详细程度:※※
3. 集成度:※※※
4. 生成警报的能力:※※※
5. 监测非Docker的资源的能力:支持
6. 成本:每个主机$10
Data Dog
从Scout移步到另一个监控服务,DataDog,它既解决几个Scout的缺点又解除了CAdvisor的局限性。要使用DataDog,先在 https://www.datadoghq.com/ 注册一个DataDog账户。一旦你登录到您的帐户,您将看到支持集成的每种类型的指令列表。从列表中选择Docker,你会得到一个Docker run命令(如下),将其复制到你的主机。该命令需要你的预先设置的API密钥,然后你可以运行该命令。大约45秒钟后您的代理将开始向DataDog系统报告。
docker run -d --privileged --name dd-agent /
-h `hostname` /
-v /var/run/docker.sock:/var/run/docker.sock /
-v /proc/mounts:/host/proc/mounts:ro /
-v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro /
-e API_KEY=YOUR_API_KEY datadog/docker-dd-agent /
现在,您的容器连接,你可以去在DataDog Web控制台的事件选项卡,看到有关你的集群中的所有事件。所有的容器启动和终止将这一事件流的一部分。
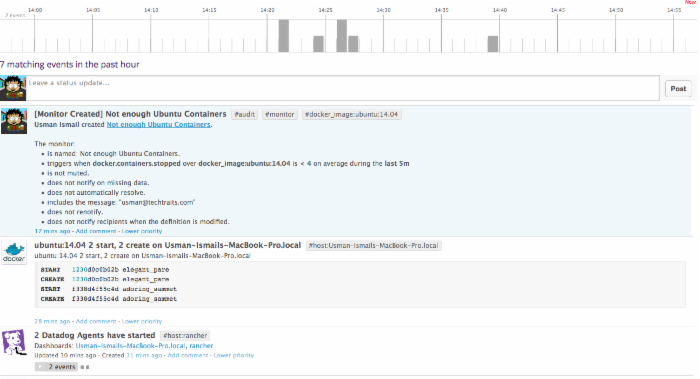
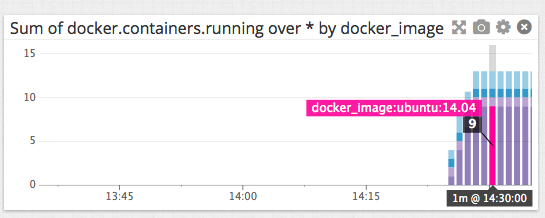
您也可以点击Dashboards标签并点击创建仪表板以合计您整个群集的指标。 Datadog收集系统中运行的所有容器中有关CPU使用率、内存以及I/O的指标。此外,您也可以获得运行和停止的容器计数以及Docker的镜像数量。Dashboard视图允许您创建基于任何指标或者设置在整个部署、主机群或者容器镜像的指标的图表。例如下图显示了运行容器的数量并加以镜像类型分类,此刻在我的集群运行了9个Ubuntu:14.04的容器。
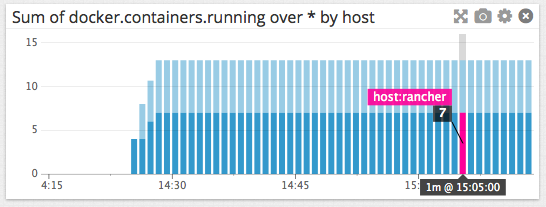
您还可以通过主机分类同样的数据,如下图所示,7个容器在我的Rancher主机上运行,其余的在我的本地的笔记本电脑。
DataDog还支持一种称为Monitors的警报功能。DataDog的一个monitor相当于Scout的一个触发器,并允许您定义各种指标的阈值。 比起Scout,DataDog的警报系统相当灵活与详细。下面的例子说明如何指定您监视的Ubuntu容器的终止,因此你会监视从Ubuntu:14.04的Docker镜象所创建容器的docker.containers.running信息。

然后,特定的警报情况是,如果在我们的部署中最后5分钟有(平均)少于十个Ubuntu容器,你就会呗警报。尽管这里没有显示,你会被要求填写发送出去时的指定消息在这个警报被触发后,而且还有受到此警报的目标。在当前的例子中,我用一个简单的绝对阈值。您也可以指定一个基于增量的警报,比如是在最后五分钟里停止的容器的平均计数是四的警报。

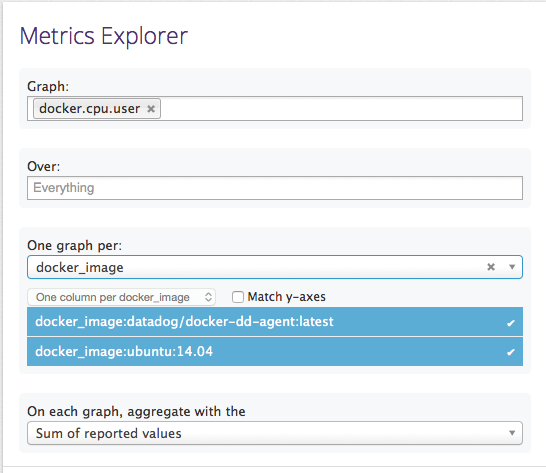
最后,使用Metrics Explorer选项卡可以临时聚集你的指标来帮助调试问题或者提取具体的数据信息。该视图允许您基于对容器镜像或主机绘制任何指标的图表。您可以将输出的数据组合成一个单一的图形或者通过镜像或主机的分组来生成一组图形。
DataDog相比scout在某些功能上做了显著地改善,方便使用以及用户友好的设计。然而这一级别伴随着额外的成本,因为每个DataDog agent价格为$15。
评分:
1. 易于部署程度:※※※※※
2. 信息详细程度:※※※※※
3. 集成度:※※※※※
4. 生成警报的能力:支持
5. 监测非Docker的资源的能力:※※※※※
6. 成本:每个主机$15
Sensu Monitoring Framework
Scout和Datadog提供集中监控和报警系统,然而他们都是被托管的服务,大规模部署的话成本会很突出。如果你需要一个自托管、集中指标的服务,你可以考虑 sensu open source monitoring framework 。要运行Sensu服务器可以使用 hiroakis/docker-sensu-server 容器。这个容器会安装sensu-server、uchiwa Web界面、Redis、rabbitmq-server以及sensu-api。不幸的是sensu不支持Docker。但是,使用插件系统,您可以配置支持容器指标以及状态检查。
在开启sensu服务容器之前,你必须定义一个可以加载到服务器中检查。创建一个名为check-docker.json的文件并添加以下内容到此文件。这个文件告诉Sensu服务器在所有有docker标签的客户端上每十秒运行一个名为load-docker-metrics.sh的脚本。
{
"checks": {
"load_docker_metrics": {
"type": "metric",
"command": "load-docker-metrics.sh",
"subscribers": [
"docker"
],
"interval": 10
}
}
}
现在,您可以使用下面的命令通过我们的检查配置文件来运行Sensu服务器Docker容器。一旦你运行该命令,你就可以在浏览器输入 http://YOUR_SERVER_IP:3000 来访问uchiwa界面。
docker run -d --name sensu-server /
-p 3000:3000 /
-p 4567:4567 /
-p 5671:5671 /
-p 15672:15672 /
-v $PWD/check-docker.json:/etc/sensu/conf.d/check-docker.json /
hiroakis/docker-sensu-server
这样Sensu服务器就开启了,你就可以对每个运行有我们的Docker容器的主机上开启sensu客户端。你告诉容器将有一个名为load-docker-metrics.sh的脚本,所以让我们创建脚本,并将其放到我们的客户端容器内。创建该文件并添加如下所示的文本,将HOST_NAME替换为您的主机的逻辑名称。下面的脚本是为运行容器、所有容器以及镜像而使用Docker远程API来拉取元数据。然后它打印出来sensu的键值标示的值。该sensu服务器将读取标准输出并收集这些指标。这个例子只拉取这三个值,但根据需要,你可以使脚本尽可能详细。请注意,你也可以添加多个检查脚本,如thos,只要早前在服务配置文件中你引用过它们。你也可以定义你想要检查运行Docker容器数量降至三个以下的失败。你还可以使检查通过从检查脚本返回一个非零值失败。
#!/bin/bash
set -e
Count all running containers
running_containers=$(echo -e "GET /containers/json HTTP/1.0/r/n" | nc -U /var/run/docker.sock /
| tail -n +5 /
| python -m json.tool /
| grep /"Id/" /
| wc -l)
Count all containers
total_containers=$(echo -e "GET /containers/json?all=1 HTTP/1.0/r/n" | nc -U /var/run/docker.sock /
| tail -n +5 /
| python -m json.tool /
| grep /"Id/" /
| wc -l)
Count all images
total_images=$(echo -e "GET /images/json HTTP/1.0/r/n" | nc -U /var/run/docker.sock /
| tail -n +5 /
| python -m json.tool /
| grep /"Id/" /
| wc -l)
echo "docker.HOST_NAME.running_containers ${running_containers}"
echo "docker.HOST_NAME.total_containers ${total_containers}"
echo "docker.HOST_NAME.total_images ${total_images}"
if [ ${running_containers} -lt 3 ]; then
exit 1;
fi
现在您已经定义你的Docker载入指标检查,你需要使用 usman/sensu-client 容器来启动sensu客户端。您可以使用如下所示的命令启动sensu客户端。需要注意的是,容器必须以privileged来运行以便能够访问Unix sockets,它必须有Docker socket挂载以及你上面定义的load-docker-metrics.sh脚本。确保load-docker-metrics.sh脚本在你的主机的权限标记为可执行。容器也需要将SENSU_SERVER_IP、RABIT_MQ_USER、RABIT_MQ_PASSWORD、CLIENT_NAME以及CLIENT_IP作为参数,请指定这些参数到您设置的值。其中RABIT_MQ_USER与RABIT_MQ_PASSWORD默认值是sensu和password。
docker run -d --name sensu-client --privileged /
-v $PWD/load-docker-metrics.sh:/etc/sensu/plugins/load-docker-metrics.sh /
-v /var/run/docker.sock:/var/run/docker.sock /
usman/sensu-client SENSU_SERVER_IP RABIT_MQ_USER RABIT_MQ_PASSWORD CLIENT_NAME CLIENT_IP
运行完此命令,一会儿你应该看到客户端计数增加1在uchiwa界面。如果您点击客户端图标,你应该看到,包括你刚才添加的客户端的客户端名单。我的客户端1是client-1以及指定的主机IP为192.168.1.1。

如果你点击客户端名称你应该得到检查的进一步细节。你可以看到load_docker_metrics检查在3月28日的10:22运行过。

如果你点击检查名称就可以看到检查运行的进一步细节。零表明没有错误,如果脚本失败(例如,如果您的Docker守护进程死掉),你会看到一个错误代码(非零)值。虽然在目前的文章中没有涉及这个,你也还可以使用 Handlers 在sensu设置这些检查失败处理程序来提醒您。此外,uchiwa只显示检查的值,而不是收集的指标。需要注意的是sensu不存储所收集的指标,它们必须被转发到一个时间序列的数据库如InfluxDB或Graphite。这也是通过Handlers做到的。如何配置指标转发到graphite 可以参考这里 。
Sensu支持我们所有的评价标准,你可以对我们Docker容器和主机收集尽可能多的细节。此外,你能够聚合所有主机的值到一个地方,并对这些检查发出警报。这些警报并没有DataDog或Sc out的先进,因为你仅能够提 醒单独的主机上检查失败。然而,Sensu的大缺点是部署的难度。虽然我已经使用Docker容器自动部署许多步骤,Sensu仍然是一个需要我们安装,启动和分开维护Redis、RabitMQ、Sensu API、uchiwa与Sensu Core的复杂系统。此外,你将需要更多的工具,如Graphite来呈现指标值以及生产部署需要定制容器,今天我已经使用了一个容器为了密码的安全以及自定义的SSL证书。除了您重启容器后才能添加更多的检查,你将不得不重新启动Sensu服务,因为这是它开始收集新的标准的唯一途径。由于这些原因,我对Sensu的在易于部署的评价相当的低。
评分:
1. 易于部署程度:※
2. 信息详细程度:※※※※
3. 集成度:※※※※
4. 生成警报的能力:支持但有限
5. 监测非Docker的资源的能力:※※※※※
6. 成本:免费
总结
今天的文章涵盖了多种选项用于监控Docker容器,从免费的选择, 如Docker stats、CAdvisor或Sensu,到有偿服务,如Scout和DataDog。我的研究到目前为止DataDog似乎是用于监控Docker部署的最好的系统。只需几秒的安装以及单行命令,所有主机都在同一个地方报告指标,在UI方面,历史趋势是显而易见的,并且Datadog支持更深层次的指标以及报警。然而,$15一个主机系统对于大型部署是昂贵的。对于较大规模,自托管部署,Sensu是能够满足大多数的要求,不过在建立和管理一个Sensu集群的复杂性可能让人望而却步。很显然,有很多其他的自托管的选项,如Nagios或Icinga,他们都类似Sensu。
但愿今天这篇文章会给你一些想法对于监视容器的选择。我会继续调查其他选项,包括使用CollectD、Graphite或InfluxDB与Grafana的更精简的自我管理的容器监控系统。敬请关注更多的细节。
其他信息:发布本文后,我有一些建议去评估Prometheus和Sysdig云,两个非常好的监控Docker的选择。我在这两个服务上花了一些时间,并添加了第二部分到这个文章中。你可以在 这里 (译注:过后会翻译这篇)找到它。
想要了解更多关于监控和管理Docker,请参加我们的下一个Rancher在线meetup。
原文: Comparing Five Monitoring Options for Docker (翻译:田浩浩 )
===========================
译者介绍
田浩浩, USYD 研究生,目前在珠海从事手机应用开发工作。业余时间专注Docker的学习与研究,希望通过DockOne把最新最优秀的译文贡献给大家,与读者一起畅游Docker的海洋。
正文到此结束
- 本文标签: UI GitHub Docker Uber 云 翻译 ip 压力 配置 亚马逊 json 开源 ssl mail 进程 Google 实例 总结 服务器 jenkins 数据库 安装 API Kubernetes 开发 root db grep 安全 管理 App 参数 web tab 密钥 redis 空间 插件 ssh unix js 集群 数据 时间 value rmi 测试 https 网站 调试 代码 key Ubuntu 定制 git cat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

