HBase 协处理器编程详解第一部分:Server 端代码编写
Hbase 协处理器 Coprocessor 简介
HBase 是一款基于 Hadoop 的 key-value 数据库,它提供了对 HDFS 上数据的高效随机读写服务,完美地填补了 Hadoop MapReduce 仅适于批处理的缺陷,正在被越来越多的用户使用。作为 HBase 的一项重要特性,Coprocessor 在 HBase 0.92 版本中被加入,并广受欢迎。本文假设读者对 HBase 以及 Coprocessor 已经比较熟悉,因此并不打算进详细介绍 HBase Coprocessor 的基本概念。不熟悉 Hbase 协处理器原理的读者可以先阅读 HBase 博客上的文章 coprocessor_introduction 进行一个基本的了解。
利用协处理器,用户可以编写运行在 HBase Server 端的代码。HBase 支持两种类型的协处理器,Endpoint 和 Observer。Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行,势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。
另外一种协处理器叫做 Observer Coprocessor,这种协处理器类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子,在固定的事件发生时被调用。比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数。
HBase 协处理器用途广泛,然而 HBase 的各种文档却没有关于其编程方法的详细介绍,给入门的新手带来很大的障碍。在前文提及的经典文章 coprocessor_introduction 中有关于如何编写 Coprocessor 的一些描述,可惜该文章发表于 HBase 0.92 的流行时期,其编程方法在新版本的 HBase 中已经无法使用。如今广泛使用的是 0.98 版本,甚至更新的 1.0 版本,读者如果按照上文中的方法进行尝试,一定会摸不着头脑。
本文将实现两个具体的 Coprocessor,来分别讲述如何编写 0.98 版本 HBase 的协处理器,基本方法对于 HBase 1.0 版本也适用。
回页首
编写 Coprocessor 流程概述和开发环境准备
本文作者采用的操作系统为 CentOS 6.5,采用其他的 Linux 发行版也可以进行 HBase 开发,不过准备工作的细节稍有不同。不过总的说来需要以下这三个主要的工具:
- JDK 1.6 以上版本
- Hbase 0.98
- Google Protobuf 2.5.0
HBase 0.98 可以使用 Java 6 或 Java 7,而到了 1.0 版本就必须使用 Java 7。但是 Java 8 则有一些问题。因此推荐大家直接使用 Java 7 的 JDK 进行开发。
安装 JDK1.7
在 Oracle 官网下载 JDK。
图 1. 下载 JDK

下载完成后解压,并移动到$HOME/tools 目录下。$HOME/tools 是我自己创建的一个目录,用来存放所有开发本文实例所需要的工具。
tar -xzvf jdk-7u67-linux-x64.tar.gz mv –r jdk1.7.0_67 $HOME/tools
如果有 root 或者 sudo 的权限,您也可以直接下载 rpm 包,然后用 rpm 命令安装。本文做最一般性的假设,因此假设您没有 root 的权限。
将下载文件解压后,还需要修改环境变量。将下面的 export 语句加入.bashrc 或者.profile 中均可。这样下次登录时这些环境变量将自动生效。
export JAVA_HOME=$HOME/tools/jdk1.7.0_67/ export PATH=$JAVA_HOME/bin:$PATH
安装 Google Protobuf
老版本的 HBase(即 HBase 0.96 之前) 采用 Hadoop RPC 进行进程间通信。在 HBase 0.96 版本中,引入了新的进程间通信机制 protobuf RPC,基于 Google 公司的 protocol buffer 开源软件。HBase 需要使用 Protobuf 2.5.0 版本。这里简单介绍其安装过程:
首先需要下载 Protobuf 2.5.0 版本的源代码安装包,如果无法访问,可以在 csdn 找到下载。
wget href="https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.bz2 tar xjvf protobuf-2.5.0.tar.bz2
确保您已经安装了 gcc 和 gcc-c++包,然后进行编译安装:
mkdir $HOME/tools/protobuf-2.5.0 ./configure --prefix=$HOME/tools/protobuf-2.5.0 make;make install
编译成功后编辑环境变量,加入 protoc 的路径
export PROTO_HOME=$HOME/tools/protobuf-2.5.0 export PATH=$PROTO_HOME:$PATH
安装 Maven
本文采用 Maven 进行 Java 工程创建和编译,因此需要安装 Maven。您也可以采用其他您所喜欢的 Java 开发工具。
在 Maven 的官方网站可以下载 Maven 的二进制包,选择版本 3 以上的均可,本文采用最新的 Maven3.3.1。
图 2. 下载 Maven
下载完毕后解压。将解压后的二进制文件夹移动到$HOME/tools 下,以便于将来清理环境。最后修改环境变量即可。
tar -xzvf apache-maven-3.3.1-bin.tar.gz mv apache-maven-3.3.1 $HOME/tools vi .bashrc export MAVEN_HOME=$HOME/tools/apache-maven-3.3.1 export PATH=$MAVEN_HOME/bin:$PATH
安装 HBase
如果您已经安装了 HBase,并且其版本高于 0.96,那么请略过本节。写作本文时,HBase0.98 的最新版本为 0.98.11,因此这里简单介绍 HBase 0.98.11 版本的安装,本文的示例程序也将在这个版本的 HBase 中部署运行。
本文介绍的协处理器编写方法可以在任何高于 0.96 版本的 HBase 上运行,包括 HBase 1.0。0.94 版本的协处理器开发方法有所不同,在前文提及的经典文章 coprocessor_introduction 中有详细介绍,互联网上也有大量的文章讲述老版本的协处理器编写方法。本文不再赘述,而着重讲述变化后的 HBase 协处理器开发方法。
在 HBase 网站下载:
图 3. 下载 HBase
下载完毕照例解压,修改环境变量。
tar xzvf hbase-0.98.11-hadoop2-bin.tar.gz mv hbase-0.98.11-hadoop2 vi ~/.bashrc export HBASE_HOME=$HOME/tools/hbase-0.98.11-hadoop2 export PATH=$HBASE_HOME/bin:$PATH
为了运行本文中的实例,我们仅需要 HBase 运行在 standalone 模式即可。为此,无需修改任何配置,直接启动 HBase 即可。
start-hbase.sh
用 jps 命令查看,应该有一个 HMaster 的进程在运行。如果看到该进程,那么恭喜,您已经建立了一个完整的开发环境,足以满足本文的需要了。
进入细节之前,我们先从整体上了解一下开发 HBase 协处理器的流程。对于 Endpoint 类型的协处理器,其开发流程如下:
第一步是建立一个 Java 工程;第二步是定义用户 ClientHBase 通信的 RFC,采用 Protobuf 语言和工具完成定义;第三步是编写 HBase 协处理器的 Client 端和 Server 端代码,其中,Client 端代码负责调用协处理器并处理返回结果,Server 端代码将运行在 Region Server 上,实现具体的任务;最后需要对编译好的代码进行部署和测试。
对于 Observer 类型的协处理器,不需要定义 RPC,也不需要开发客户端代码。当相应的事件发生时,Observer 代码将自动在 Server 端执行。因此仅仅需要编写 Server 端的代码即可。
回页首
一个应用实例
本文将通过一个具体实例,来演示两种协处理器的开发方法的详细实现过程。
在管理 HBase 应用的过程中,笔者常想知道某个 Region 中数据行的个数总和,即 row count,或者整个 table 的数据量。本文将用“行数”来指称 row count。可以用 HBase Shell 的 count 命令来获取某张表的数据量。不过这是一个全表扫描过程,非常浪费资源,也很慢;另外一方面,还没有一个快捷的方法来获得单个 Region 的行数。
为此,我打算利用 Coprocessor 来实现一个简单的工具来帮助我实现以上的需求。其工作原理如下:
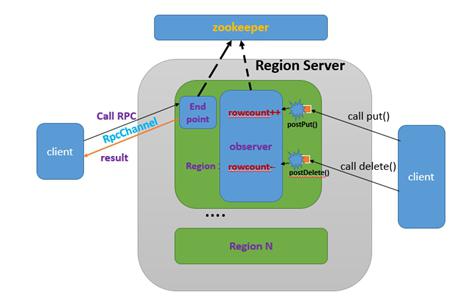
利用 Observer 协处理器在每一次 put 操作时,将统计该 Region 的行数,并保存在一个计数器中;在每一次 delete 操作时,将该计数器减 1。利用 Endpoint 协处理器,将该计数器的数值返回给 Client 端调用;为了在 Observer 和 Endpoint 协处理间共享行数计数器,我们将该计数器保存在 ZooKeeper 中。在客户端,调用 Endpoint 协处理器获取指定 Region 的行数计数器,并将所有的返回值求和即可。基本过程如下图所示:
图 4. 整体流程
回页首
创建 maven 工程
创建一个工程代码目录,用 {PROJECT_HOME} 来代表您创建的目录,后续开发的所有代码都将放在这里:
$ mkdir $PROJECT_HOME
用如下 Maven 命令创建工程:
$ cd $PROJECT_HOME $ mvn archetype:generate -DgroupId=org.ibm.developerworks -DartifactId=regionCount -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
回页首
Endpoint 协处理器
在本文中,Endpiont 协处理器的工作十分简单。仅仅返回 Region 的行数计数器即可,可以归纳为:读取一个值,然后返回它。但是即便是如此简单的一个操作,为了实现它,必须首先编写协处理器的框架。本文试图为大家提供一个尽量完整的参考。对于有经验的 Java 开发人员,以下的描述恐怕略显啰嗦,还请见谅。
用 Protobuf 编写和定义 RPC
如前所述 Endpoint 协处理器读取 Region 的行数计数器,然后将该值返回给调用的客户端。因此 RPC 需要一个整数类型的返回值代表行数。仅仅返回行数的情况下,客户端并不需要为 RPC 定义任何输入参数,不过为了演示输入和输出,我们额外为这个 RPC 设计了一个输入参数:reCount。这个参数是一个布尔变量,当为 true 时,表明用户需要 Endpoint 扫描遍历 Region 来计算行数;当其为 false,表示直接使用 Observer 协处理器维护的计数器。前者需要扫描整个 Region,非常慢;后者效率很高。
通过这种方法,我们也可以检验数据的正确性,因为遍历 Region 得到的行数是最准确的。最终的 RPC 定义如下。
清单 1. getRowCount RPC proto 定义
option java_package = "org.ibm.developerworks"; option java_outer_classname = "getRowCount"; option java_generic_services = true; option optimize_for = SPEED; message getRowCountRequest{ required bool reCount = 1; } message getRowCountResponse { optional int64 rowCount = 1; } service ibmDeveloperWorksService { rpc getRowCount(getRowCountRequest) returns(getRowCountResponse); } 将以上代码保存为文件 ibmDeveloperworksDemo.proto。可以看到,这里定义了一个 RPC,名字叫做 getRowCount。该 RPC 有一个入口参数,用消息 getRowCountRequest 表示;RPC 的返回值用消息 getRowCountResponse 表示。Service 是一个抽象概念,RPC 的 Server 端可以看作一个 Service,提供某种服务。在 HBase 协处理器中,Service 就是 Server 端需要提供的 Endpoint 协处理器服务,可以为 HBase 的客户端提供服务。在一个 Service 中可以提供多个 RPC,在本文中,我们仅仅定义了一个 RPC,实际工作中往往需要定义多个。
将该文件存放在工程的 src/main/protobuf 目录下。
$ mkdir $PROJECT_HOME/rowCount/src/main/protobuf $ mv ibmDeveloperworksDemo.proto $PROJECT_HOME/rowCount/src/main/protobuf
用 Protobuf 编译器将该 proto 定义文件编译为 Java 代码,并放到 Maven 工程下。
$ cd $PROJECT_HOME/rowCount/src/main/protobuf $ protoc --java_out=$PROJECT_HOME/rowCount/src/main/java ibmDeveloperworksDemo.proto
现在可以看到在工程的 src/main/java/org/ibm/developerworks 目录下生成了一个名为 getRowCount.java 的文件。这个 Java 文件就是 RPC 的 Java 代码,在后续的 Server 端代码和 Client 端代码中都要用到这个 Java 文件。
为了编译新生成的 Protobuf Java 代码,我们还需要修改 Maven 的 pom.xml 文件,加入对 protobuf-2.5.0 的依赖,这样 Maven 就可以自动下载相应的 jar 包,完成编译。
在 pom.xml 文件中加入如下的内容即可:
清单 2. Protobuf 在 pom.xml 中的依赖
<dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency>
现在可以尝试进行第一编译了:
mvn clean compile
如果出现错误,您需要仔细查看代码是否在编辑的时候出错。本文的附件中有所有的示例代码,仅供参考。
实现 Server 端代码
在工程目录的 src/main/java/org/ibm/developerworks/下建立一个 coprocessor 的目录,存放我们即将开发的 Server 端 Endpoint 协处理器代码。
$ mkdir $PROJECT_HOME/rowCount/src/main/java/org/ibm/developerworks/coprocessor
Server 端的代码就是一个 Protobuf RPC 的 Service 实现,即通过 Protobuf 提供的某种服务。其开发内容主要包括:
- 实现 Coprocessor 的基本框架代码
- 实现服务的 RPC 具体代码
Endpoint 协处理的基本框架
Endpoint 是一个 Server 端 Service 的具体实现。它的实现有一些框架代码,这些框架代码与具体的业务需求逻辑无关。仅仅是为了和 HBase 的运行时环境协同工作而必须遵循和完成的一些粘合代码。因此多数情况下仅仅需要从一个例子程序拷贝过来并进行命名修改即可。不过我们还是完整地对这些粘合代码进行粗略的讲解以便更好地理解代码。
首先 Endpoint 协处理器是一个 Protobuf Service 的实现,因此需要它必须继承某个 Protobuf Service。我们在前面已经通过 proto 文件定义了 Service,命名为“ ibmDeveloperWorksService ”,因此 Server 端代码需要重载该类,下图中相关代码用红色方框着重显示:
图 5. Endpoint 协处理器框架代码--父类

其次,作为一个 HBase 的协处理器,Endpoint 还必须实现 HBase 定义的协处理器协议,用 Java 的接口来定义。具体来说就是 CoprocessorService 和 Coprocessor ,这些 HBase 接口负责将协处理器和 HBase 的 RegionServer 等实例联系起来,以便协同工作。下图中相关代码用红色方框着重显示:
图 6. Endpoint 协处理器框架代码--接口

Coprocessor 接口定义了两个接口函数,start 和 stop。
协处理器在 Region 打开的时候被 RegionServer 自动加载,并会调用器 start 接口,完成初始化工作。一般的该接口函数中仅仅需要将协处理器的运行上下文环境变量 CoprocessorEnviorment 保存到本地即可。
清单 3.start 接口
//这两个类成员是后续代码用来操作 ZooKeeper 的,在 start() 中进行初始化 private String zNodePath = "/hbase/ibmdeveloperworks/demo"; private ZooKeeperWatcher zkw = null; @Override public void start(CoprocessorEnvironment env) throws IOException { if (env instanceof RegionCoprocessorEnvironment) { this.re = (RegionCoprocessorEnvironment) env; RegionServerServices rss = re.getRegionServerServices(); //获取 ZooKeeper 对象,这个 ZooKeeper 就是本 HBase 实例所连接的 ZooKeeper zkw = rss.getZooKeeper(); //用 region name 作为 znode 的节点名后缀 zNodePath=zNodePath+re.getRegion().getRegionNameAsString(); } else { throw new CoprocessorException("Must be loaded on a table region!"); } } CoprocessorEnviorment 保存了协处理器的运行环境,每个协处理器都是在一个 RegionServer 进程内运行,并隶属于某个 Region。通过该变量,可以获取 Region 的实例等 HBase 的运行时环境对象。
当需要在协处理器内调用 HBase 的服务或者 API 时,就必须通过该变量获取相应的 HBase 内部对象实例完成相关的操作。我们将在后续的 RPC 实现代码中给出详细的例子。
在 start 函数中,我们还初始化了一个 ZooKeeperWatcher,在文章的后续部分中,我们将详细介绍这个对象的用途。
Coprocessor 接口还定义了 stop() 接口函数。该函数在 Region 被关闭时调用,用来进行协处理器的清理工作。在本文中,我们没有任何清理工作,因此该函数什么也不干。
清单 4. stop 接口
@Override public void stop(CoprocessorEnvironment env) throws IOException { // nothing to do } 我们的协处理器还需要实现 CoprocessorService 接口。该接口仅仅定义了一个接口函数 getService()。我们仅需要将本实例返回即可。HBase 的 RegionServer 在接受到客户端的调用请求时,将调用该接口获取实现了 RPC Service 的实例,因此本函数一般情况下就是返回自身实例即可。
清单 5. getService 接口
/** * Just returns a reference to this object, which implements the RowCounterService interface. */ @Override public Service getService() { return this; } 完成了以上三个接口函数之后,Endpoint 的框架代码就完成了。每个 Endpoint 协处理器都必须实现这些框架代码,而且写法雷同。
Endpoint 协处理器真正的业务代码都在每一个 RPC 函数的具体实现中。
在本文中,我们的 Endpoint 协处理器仅提供一个 RPC 函数,即 getRowCount。我将分别介绍编写该函数的几个主要工作:了解函数的定义,参数列表;处理入口参数;实现业务逻辑;设置返回参数。
函数定义
函数 getRowCount 在 Server 端的函数定义如下。
public void getRowCount(RpcController controller, getRowCount.getRowCountRequest request, RpcCallback<getRowCount.getRowCountResponse> done)
每一个 RPC 函数的参数列表都是固定的,有三个参数。第一个参数 RpcController 是固定的,所有 RPC 的第一个参数都是它,这是 HBase 的 Protobuf RPC 协议定义的;第二个参数为 RPC 的入口参数;第三个参数为返回参数。入口和返回参数分别由代码清单 1 的 proto 文件中的 getRowCountRequest 和 getRowCountResponse 定义。
分析入口参数
request 包含了入口参数,从 proto 定义中可以知道,这个入口参数只有一个 field,布尔类型的 reCount。我们将该参数从 Protobuf 消息中反序列化:
boolean reCount=request.getReCount();
如果您编写的 RPC 包含多个 field,每一个 field 都可以通过 request.getXXX() 函数来获得,其中 XXX 表示 field 的名字。
实现函数逻辑
我们的 RPC 的主要业务逻辑为获得 Region 的行数,当 reCount 为 true 时,需要遍历 Region 然后对结果集进行计数来获得行数;当 reCount 为 false 时,直接读取表示行数的变量。
我们先来看遍历 Region 的方法,这是最经典的行数统计实现,在 HBase 代码的 example 目录下也有现成的例子。通过 Scan 操作遍历 Region 中的每一行数据,在循环内将计数器累加即可。下面的代码清单中将错误处理部分去掉,以便很好地显示主要逻辑。
清单 6. 采用 scan 方法获取行数
Scan scan = new Scan(); InternalScanner scanner = null; scanner = env.getRegion().getScanner(scan); boolean hasMore = false; long count = 0; do { hasMore = scanner.next(results); count++; } while (hasMore); 以上方法的缺点是运行效率低,且耗费资源。因为协处理器运行在 RegionServer 的地址空间,所以会影响 HBase 的整体运行效率。
另外一个办法是利用 Observer 协处理器负责维护行数计数器,而在 Endpoint 协处理器中仅仅需要读取该计数器即可。
一个需要解决的问题就是协处理器间的数据共享。因为 Observer 协处理器的运行实例和 Endpoint 协处理器的实例是独立的。
本文采用 ZooKeeper 进行数据共享,Observer 协处理器负责建立 ZooKeeper 节点 znode,并更新节点数据。在本例中,znode 数据为一个整数,表示 Region 的行数。我们将 Region Name 作为 znode 名字的一部分,以此来区分不同 Region 的计数器。这样,每一个 Region 都将在 ZooKeeper 中拥有一个自己的计数器。
清单 7. 从 ZooKeeper 得到计数器值
try{ byte[] data=ZKUtil.getData(zkw,zNodePath); rowcount = Bytes.toLong(data); } catch (Exception e) {LOG.info("Exception during getData"); } 设置返回参数
得到了行数之后,用它来设置返回参数,即 getRowCount.CountResponse 消息的 rowCount 域。协处理器将该值返回给客户端。
清单 8. getService 接口
getRowCount.getRowCountResponse response = null; response = getRowCount.getRowCountResponse.newBuilder().setCount(rowcount).build(); //将 rowcount 设置为 CountResponse 消息的 rowCount done.run(response); //Protobuf 的返回
至此,EndPoint 协处理器完成。
修改 pom.xml 加入 HBase 的 dependency
在以上代码中,包含了大量的 HBase 代码,因此在编译之前,需要修改 pom.xml 加入 HBase 的依赖。
清单 9. HBase 的 Maven 依赖
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>0.98.11-hadoop2</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-protocol</artifactId> <version>0.98.11-hadoop2</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>0.98.11-hadoop2</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>0.98.11-hadoop2</version> </dependency>
好了,现在再次执行 Maven 编译。就生成了 Endpoint 协处理所需的 jar 包。
回页首
Observer 协处理器
Observer 协处理器利用 postPut,postDelete 等几个钩子函数来维护 Region 的行数计数器。当 put 操作被调用时,我们认为一条新的数据被插入 Region,因此计数器应该加 1。同样当 Delete 被调用时,将计数器减 1。
Observer 协处理器的框架代码
和 Endpoint 协处理器相同,首先需要编写通用的框架代码。类 rowCountObserver 是我们准备开发的协处理器,首先它必须继承 BaseRegionObserver 类。然后我们需要重载 start() 和 stop() 两个方法。最后重载 prePut,preDelete 等 hook 方法。
清单 10. Observer 协处理器框架代码
public class rowCountObserver extends BaseRegionObserver { RegionCoprocessorEnvironment env; @Override public void start(CoprocessorEnvironment e) throws IOException { env = (RegionCoprocessorEnvironment) e; RegionServerServices rss = re.getRegionServerServices(); m_region = re.getRegion(); zNodePath = zNodePath+m_region.getRegionNameAsString(); zkw = rss.getZooKeeper(); myrowcount = 0 ; //count; try{ if(ZKUtil.checkExists(zkw,zNodePath) == -1) { LOG.error("LIULIUMI: cannot find the znode"); ZKUtil.createWithParents(zkw,zNodePath); LOG.info("znode path is : " + zNodePath); } } catch (Exception ee) {LOG.error("LIULIUMI: create znode fail"); } } @Override public void stop(CoprocessorEnvironment e) throws IOException { // nothing to do here } } start 执行初始化操作,包括保存 CoprocessorEnviorment 对象,获取 ZooKeeper Watcher,创建 znode 等工作。主要就是创建了和 Endpoint 协处理直接共享数据用的 znode。
rowcount 的初始化
本文中,我们将代表行数的数字存放在 znode 中。znode 保存在 ZooKeeper 中,由 ZooKeeper 保证持久性。但是在第一次初始化的时候,我们还是需要统计当前的行数以便对 znode 进行正确的初始化。比如 Region 目前已经保存了 100 行数据,那么我们应该将 znode 的值设置为 100。
为此,我们需要对 Region 进行 scan 操作。然而 start() 方法调用的时候,region 还未完全初始化完成,因此无法调用 scan 操作,因此我们将利用 Observer 的 postOpen() 钩子函数来对 znode 进行初始化。postOpen 在 Region 被打开成功之后调用,因此所有的 Region 操作都可以执行。
在 postOpen 函数内,我们将利用 Scan 对象对 Region 进行遍历,求得行数,并用该值对 znode 进行初始化,代码如下。
清单 11. postOpen 代码
@Override public void postOpen(ObserverContext<RegionCoprocessorEnvironment> e) { long count = 0; //Scan 获取当前 region 保存的行数 try{ Scan scan = new Scan(); InternalScanner scanner = null; scanner = m_region.getScanner(scan); List<Cell> results = new ArrayList<Cell>(); boolean hasMore = false; do { hasMore = scanner.next(results); if(results.size()>0) count++; } while (hasMore); } //用当前的行数设置 ZooKeeper 中的计数器初始值 ZKUtil.setData(zkw,zNodePath,Bytes.toBytes(count)); //设置 myrowcount 类成员,用来表示当前 Region 的 rowcount myrowcount = count; } catch (Exception ee) {LOG.info("setData exception");} } 维护 rowcount 的 hook 方法
在 Observer 协处理器中,我们需要实现以下几个 hook 方法来维护行数:
- preDelete:在数据被删除前调用
- prePut:在数据被插入前调用
在 preDelete 中,将计数器减 1;在 prePut 中,将计数器加 1。代码如下:
清单 12. getService 接口
@Override public void preDelete(ObserverContext<RegionCoprocessorEnvironment> e, Delete delete, WALEdit edit, Durability durability) throws IOException { //计数器减 1 myrowcount--; //更新 znode try{ ZKUtil.setData(zkw,zNodePath,Bytes.toBytes(myrowcount)); } catch (Exception ee) {LOG.info("setData exception");} } } @Override public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException { //计数器加 1 myrowcount++; //更新 znode try{ ZKUtil.setData(zkw,zNodePath,Bytes.toBytes(myrowcount)); } catch (Exception ee) {LOG.info("setData exception");} } 以上代码还不是很完善,仅仅作为演示例子供大家参考,还无法用于真正的实用环境中。在 preDelete 和 prePut 中需要先调用 get 判断给定数据是否存在,再进行计数器的增加或者减一操作。
至此 Observer 协处理器代码也已经完成。用 Maven 编译获得 jar 包。
回页首
小结
HBase 社区吸引了世界各国的众多计算机专家,开发非常活跃,目前已经推出 1.0 版本,意味着社区对 HBase 本身的成熟度已经非常有信心。然而核心开发人员专注于核心功能的开发,而很少花精力进行文档的写作。笔者在使用 Hbase 的过程中往往苦于资料的匮乏,多数情况下只好去研读别人的现成代码,找到适合自己的部分。对于一般的客户端开发,这个问题并不大,因为 HBase 的功能非常紧凑,只需要掌握数据的增删改查方法即可。然而一旦涉及到开发协处理器,因为它运行在 Region Server 端,很多功能需要了解 HBase 的内部实现代码,就比较头疼了。本人将自己的开发过程完整记录下来,和大家分享,仅仅是希望能够让普通开发人员获得一些帮助。
在后续第二部分,笔者将继续介绍在客户端如何调用协处理器,并简单演示一下协处理器的部署和运行。
回页首
下载
| 描述 | 名字 | 大小 |
|---|---|---|
| 代码示例 | sampleCode.zip | 1832k |
正文到此结束
- 本文标签: Region 协议 SDN shell value 互联网 HMaster zip IDE tab CEO tar 操作系统 HDFS HBase Shell 编译 Google pom key 进程 zookeeper java 数据 Hadoop 空间 参数 集群 配置 root API maven XML 数据库 Developer 目录 HBase 开源软件 rpm 需求 https 软件 网站 安装 apache 管理 node 实例 Oracle 开源 linux apr UI 测试 代码 ip list cat map wget 大数据 IBM 遍历 find 开发 centos
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

