黄洁:Intel Spark应用优化和实践经验
【编者按】干货满满的2015 OpenStack技术大会、2015 Spark技术峰会、2015 Container技术峰会以实力赢得所有观众的认可。在Spark峰会上,英特尔大数据技术中心研发经理黄洁就Spark的内存管理、IO提升和计算优化3个方面进行了详细讲解,以下为演讲概述。
下为演讲概述
我来自Intel大数据技术中心,整个技术中心在中国、美国、印度都有相应的开发人员,团队致力于大数据顶尖项目的研究,主要包括Spark、Hadoop、Hive,有20多位Apache的Committers。团队的主要贡献集中于Spark,在Spark进入Apache时就开始合作,做出了功能、性能、易用性等方面的一些贡献。目前我们在整个Spark开源社区都是名列前茅的。
从自身角度来讲,团队很早之前就涉及到了对于Hadoop MapReduce的一些工作,在这个过程中我们发现,MapReduce天生存在一定的性能缺陷。无论是任何一个成功的大数据框架还是平台,只有走进真实工业性用户才能得到很好的效果和反馈。我们跟国内顶尖的互联网公司合作,使用Spark以及Spark软件开发真实的大数据应用,在这个过程中收获了很多经验,也希望把这些经验分享给合作伙伴和社区爱好者。
应用分类
很多人会发出这样的疑问,Spark到底适用于哪些场景?我们在哪些场景适合使用Spark ,或者我们应该首选Spark?从我们合作伙伴来讲,可以分为以下三类应用。
复杂的机器学和图的计算。 比如我们和很多合作伙伴做了一些社交网络的分析,然后通过分享给朋友从中分析出用户的喜好,或者通过更远朋友的关系获得一些信息。又比如说Community Detection,即社区挖掘或者社区发现,这也是一类。这部分用户大部分体现在对开发方式持有比较开放的态度,因为他原来在Hadoop并没有寻求到比较好的解决方案,所以直接选择用Spark的各种API或者操作原语开发一些算法的应用。
Complex、Interactive、OLAP/BI等。 目前,基本上70%或者80%的项目都是基于MapReduce,所以迁移起来比较方便。这部分用户在应用层上只需做很小的改动,或者甚至无需改动,往往可以发现性能两倍或者五六倍的提升(具体情况取决应用案例本身),所以他们很愿意迁移到Spark上来。
Stream Processing。 作为一个比较完整的下一代大数据处理平台,Spark不仅提供了前面两种应用功能,也提供了流处理。
经验分享
从这些应用里我们得到很多经验,下面和大家分享一下。
Spark性能,这个数据是基于许多真实应用基础,对比了Spark的原型开发和原先Hadoop所跑的性能,提升基本上达到5~6倍,有的甚至能达到百倍性能提升。同时,有一些应用在Spark是可以实现的(或者至少可以开发),但在MapReduce这个平台上没有办法实现或者执行。所以对这部分的用户来说,这部分性能或者功能优势差别更大。这也是大家用Spark的原因。
除此之外,还有一半的人是因为Spark的易用性和Spark公共平台提供各种类型大数据的应用所带来的优点。 就像上文提到的这三种类型在Spark部署环境上都可以达到一定的需求。同时,Spark还提供了非常多的语言,以及比较丰富的简单算子。例如现在我们也在跟社区一起合作,将为Spark提供R语言接口。当下项目已经合并到了Spark的主干版本。
所以从这两方面来说,很多人都非常欢迎Spark。虽然Spark非常美好,但就真的没有问题了吗?我们发现Spark还需要更加完善,需要更多人的贡献和努力。我们也发现在比如可靠性、易用性等方面还需更多完善。所以本文主要的内容就是希望从各个方面通过案例说明怎样提升Spark的应用体验。
案例分析
之前的总结可能很抽象,希望通过下面的案例能够带来更具象的认识,了解怎样通过这三个方面构建更加平衡的系统,获得更加优异的性能。
管理内存
一提到Spark,首先想起的就是Spark的优势在于内存计算,所以第一条就是怎样管理内存,使内存更加高效。
当与很多合作伙伴合作时,我们发现图计算场景促进了Spark的火爆:在图计算里最大的特性是迭代式计算,而Spark能够把计算出来的结果缓存在内存,之后迭代可以直接读取内存数据,从而显著地提升了性能。也就是说迭代与迭代的依赖关系是非常紧密的,但有时前一轮迭代产生的数据在后一轮迭代时就不再被使用了。
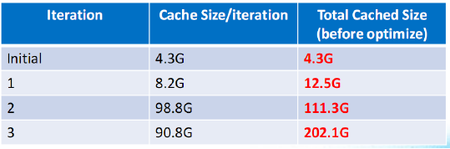
图1 程序优化前的缓存对比
如图1所示,这张表格是真实应用的例子,第一列是它的迭代轮数,第二列是需要缓存的RDD,第三列是累计被缓存的RDD。大家知道很多大规模计算往往都是千轮迭代,但只到第三轮迭代就需要这么大的内存空间了。那么,是不是表示Spark应用就需要这么大的内存空间呢?事实显然不是这样。
在代码里做了一个优化,结果发现内存空间节省了50%,这就意味着你可以节省出50%内存空间给其他应用。更新过的结果如图2所示。更新这个应用后,达到的数值和预期的数值是一样的。这个贡献其实已经被应用了,希望引发大家在用户层对Spark的思考,因为Spark提供了注入缓存和释放缓存的接口,所以在仔细开发代码的同时,也希望注意到在不使用缓存的情况下,主动去释放一些内存空间,这样意味着可以腾出更多的空间给计算。
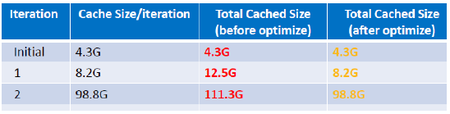
图2 程序优化后的缓存对比
第二个更推荐在大数据量下使用,有一些应用场景希望使用到内存存储空间,主要通过Tachyon来进行存储。如图3所示,这是给客户做的一个真实的案例,它是一个流式处理,是后端提供SQL查询内存数据表格,可以说是一个非常完整的处理框架。在这个过程当中,Spark-streaming的一个应用和Spark SQL的一个应用都是在同一个应用进程内,两个模块同时服务实时处理框架。
但对于真正的Service并不适合,所以如图4所示采用了Tachyon RawTables方式,把Spark Streaming放在了内存tables中,我们通过Spark SQL进程也可以访问内存数据达到即时响应的目的。同时,使得进程和进程各自工作时更加稳定,这也是它在我们真实案例中的一个使用。

除了稳定性和功能性考虑,在实际案例中还使用了Tachyon来提升内存计算效率。迭代式图计算需要缓存一些前轮的迭代结果以方便后轮使用。往往在真实环境下,有一些非常大的图数据是很难被全部缓存在内存空间,所以在这个过程当中,内存经常出现异常,或者是出现长时间的GC,又或者这个过程假死或者没有响应。所有数据存在Tachyon的层级缓存里面。在这里引入一个存储层级化概念,用户只要配置多少磁盘,有多少HD,多少内存空间,就可以首先放入内存,内存不够就放入缓存,之后会有更大空间去分析这个数据。通过这样的实现,大大减少了GC开销,提高了最后的执行效率。
提升I/O
第二点是I/O。首先提到的一个是本地化,在很多应用场景下,偶尔会有这样的情况,就是Spark的应用本地化并没有传统的MapReduce那么好,究其根本是Spark在等待新的Executor注册。当Executor没有全部注册上来,系统就会分配相应的任务,任务分配到节点,但并不一定是数据存储节点,从而造成非常糟糕的后果。当一个作业运行以后,如图5所示,这四张图是一个网络的利用率,一定要引入网络的带宽。

在这一阶段还是能够忍受的,因为并没有占满网络带宽。当然可能对于平台服务的提供者或者维护者来说却已经是浪费了资源。更严重的问题是在第二个阶段,它造成了整个应用的数据集中在部分节点。当其他节点从这些节点Shuffle数据时,网络带宽就会产生100%利用的情况。在以下两个方面提出改进,第一个是加入两个可调参数,这个优化很直观,可以选择等待80%或者90%都注册以后来分配任务。还有一种方式是等不起的,这个时候选择等待多少时间,在这种情况下加了一些优化。优化后的结果如图6所示,同样还是四张图,一开始的网络带宽都非常好,特别是在最后一个阶段那个网络瓶颈被取消了,所有系统最后的性能达到1.75倍提升。这是第一个网络的优化。

第二个是涉及到磁盘、I/O优化的网络。我们有很多合作伙伴早就有了Hadoop集群,所以大部分Spark是部署在YARN上面。比如在YARN的同一台物理节点上NodeManager上会有若干个Container服务于同一个Spark应用。在Spark启动时就需要把这些包分发到各个节点上,如果传送到同一个物理节点上,就是浪费了平台的资源。下面这个实例是磁盘和网络吞吐量,如图7所示,红色部分就是应用启动时间,大概是十秒钟,磁盘和网络没有达到瓶颈,却因为发送端网络的瓶颈造成整个启动耗时较长。
在这个过程当中做一个优化。优化后的结果如图8所示,应用启动时间不到一秒钟,只需半秒钟就可以完成整个启动过程完成,所以提升了十倍。特别是短作业,本身是一秒钟时间,但启动用了十秒钟就不是很合理了。
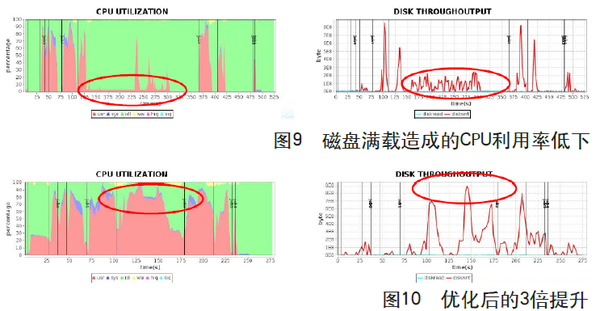
还有一个实例也是关于磁盘的。现在很多用户都会主动去缓存一个RDD,但这里会存在一个问题:内存无法缓存所有数据,往往用户会选择保守的缓存方式,即内存和磁盘混合存储,当内存放不下时,溢出到磁盘中。如图9所示是一个应用实例,图片分别显示CPU利用率和磁盘的带宽,这个磁盘的最高峰值是100MB/s,在这个影响下,CPU的利用率非常低,从而导致整个Stage的时间非常长。问题是用户已经配置了多张磁盘,他们的带宽却没有得到充分利用,这个过程中存在一个写同步的问题。
优化之后的结果如图10所示。优化之后,首先磁盘带宽提高了,也就是磁盘峰值是800MB/s,极大提高了效率。通过这样的优化,整个RDD的Cache有3倍提升。

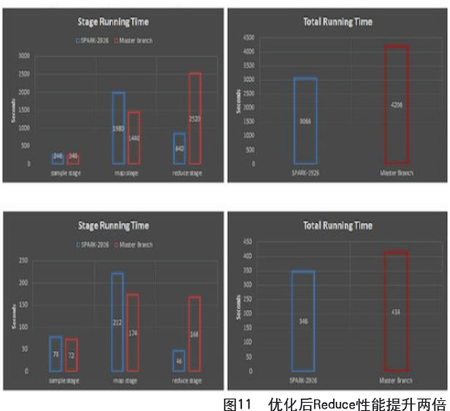
最后一点,对于Intel来说希望看到的是CPU优化,在考虑如何优化计算的同时,也希望能够优化整个软件栈来提供服务,能够充分利用平衡的一个系统。第一个例子和MapReduce Shuffle基本原理性是大同小异的。对SQL查询来说,非常依赖于Sort操作。在1.2版本里引入基于排序的Shuffle Write,解决了一些可扩展性问题。在充分利用之前的结果的基础上做了Shuffle Read,得到了最后的结果。这个工作是我们和Cloudera的工程师一起完成的,我们在内存中进行排序,然后把这些排序结果尽可能多地在内存中合并,如果内存不够则溢出,最后返回一个直接排序的数据,这样就不用浪费资源重新计算。如图11所示,分别是大、小规模数据测试结果,可以看出,通过这个优化,Reduce阶段性能会提高两倍。
有了这个功能,用户可以得到MapReduce Style的Shuffle结果;同时,配合我们最近提交的Sort Merge Join,内测的查询性能提高了20%。
第二个是关于一些非常复杂的机器学算法,比如说一些图的计算,都会用到一些代数运算的支持,即用到一些矩阵计算,这是在比较常见的场景。所以我们用了一个Intel MKL,充分利用了指令级优化,在性能方面得到了很大的提升,这个也是一个真实用户的案例,可以达到2~4倍性能提升。这部分应用代码没有开源,因为需要用户在应用层自行开发,其余改进优化内容都可以在开源社区上看到。
工具分享
第一个是跑MapReduce用户非常熟悉的一个基准性测试HiBench。我们拓展到了Spark上。目前提供各种API(Scala、Python及Java)实现,支持MR1(Standalone)和YARN。将来也希望开放Streaming的基准性测试。作为大数据的基准性测试,希望可以给用户一个直观上的衡量标准,比较代码改动或者版本改动带来的区别。
第二是我们自己开发的性能分析工具。该工具是基于一个非常轻量级的无侵入式实现。它可以帮助用户查看Spark分阶段的运行情况,包括系统的使用情况。最后我们提供了Web展示页面,方便工作人员检测或者分析结果。以上所有的案例分析都是基于该工具提供的信息得到的。
当前工作模式
最后提到现在的工作模式,主要还是在开源社区上的开发上,也会从两个渠道来发现问题和解决。第一,和广泛合作伙伴发现现在线上所有Spark的问题。第二,接下来会主要针对Spark Core、SQL做一些兼容方面的工作。Streaming做的是HA,还有R的支持,我们现在也紧跟着Spark R的步伐在做更多贡献。
简而言之,首先Spark在整个生态圈或者大数据上面起到的作用是不容忽视的,这也是Spark贡献人员非常想看到的。第二是希望Spark可以做得更好更完善,让更多人去使用它。至于如何做到,首先希望能明白应用,或者Spark应用、Spark平台,比如说用一些工具,或者说用一些生产环境的实践。第三是怎样适合Spark,没有非常明确的Memory和多大规模集群,可以肯定的一点就是最高效地充分利用了网络、磁盘、CPU。最后希望有更多的应用者可以及时反馈使用情况或者遇到的各种问题,这是大家对于Spark最大的贡献。
6月3-5日,北京国家会议中心, 第七届中国云计算大会 ,3天主会,17场分论坛,3场实战培训,160+位讲师, 议题全公开 !
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

