php页面编码与字符操作
我们可以用header来定义一个php页面为utf编码或GBK编码,也可以在html中用meta标签来指定编码
例如:php页面为utf编码 header("Content-type: text/html; charset=utf-8");
我们通常使用header或meta,下面说一说两者的区别
一、采用meta页面编码
用meta来设置页面编码
1 <meta http-equiv="content-type" content="text/html; charset=编码类型">
作用是:声明客户端的浏览器用什么字符集编码显示该页面,起到通知浏览器的作用。只有字符编码与浏览器编码相同时才不会造成错误而产生乱码。
二、采用header()页面编码
用header()来设置页面编码
1 header("content-type:text/html; charset=编码类型"); header是发送原始 HTTP 标头,作用是把括号里面的信息发到http标头,浏览器会采用header()中设置的编码。
三、AddDefaultCharset方式设置编码
注意: 以前版本的Apache配置时修改AddDefaultCharset这个选项,要改为gb2312或者utf-8,否则汉字会变为乱码,但从Apache 2.0.53 开始,取消了AddDefaultCharset,现在的新版本会自适应浏览器的。所以在apache2.4中是找不到AddDefaultCharset的。
文档中:
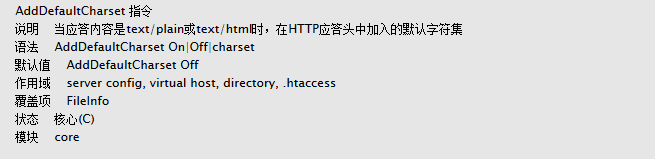
低版本的Apache的 .conf 文件里,有AddDefaultCharset。可以设置defaultcharset 字符编码(删除前面的#)。设置完成后相当于在每个文件中加上header("content-type:text/html; charset=字符编码")。
但是和header()还是有区别的(优先级不一样)
1:如果页面没有指定编码 , Apache配置defaultcharset gbk , 页面文件编码是utf-8。
页面显示是乱码。在页面没有meta指明charset,设置defaultcharset gbk,这个时候服务器的设置生效,编码不一致,造成乱码;
2:如果页面指定编码为utf-8, Apache配置defaultcharset gbk. 页面文件编码是utf-8。
页面显示乱码。设置defaultcharset gbk,会覆盖页面级别(meta)的编码设置;
3:如果页面header申明charset为utf8, Apache配置defaultcharst gbk,页面文件编码是utf8。
页面显示正常。这个说明header优先级要高于服务器和浏览器的设置;
4:如果Apache关闭DefaultCharset 。
页面显示正常。
由此得出结论:
header() >> AddDefaultCharset >> meta
所以添加header()是比较好的方法
四、编码转换函数
1:mb_detect_encoding 检查编码
1 $string = "赵亚飞"; 2 $encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5")); 3 header("content-Type: text/html; charset=".$encode); 4 echo $string;
有时会出现检查错误(解决办法)例如:对与GB2312和UTF- 8,或者UTF-8和GBK网上说是由于字符短是,mb_detect_encoding会出现误判。 不是bug,写程序时也不应当过于依赖mb_detect_encoding,当字符串较短时,检测结果产生偏差的可能性很大。
$encode = mb_detect_encoding($keytitle, array('ASCII','GB2312′,'GBK','UTF-8');
三个参数分别是:被检测的输入变量、编码方式的检测顺序( 如果为真,后面自动忽略 )、strict模式
对编码检测的顺序进行调整,将最大可能性放在前面,这样减少被错误转换的机会。 一般要先排gb2312,当有GBK和UTF-8时,需要将常用的排列到前面。
2:mb_convert_encoding 转换编码
函数原型:string mb_convert_encoding ( string str, string to_encoding [, mixed from_encoding] )
例如:
1 1: 将任意类型( 'ASCII,GB2312,GBK,UTF-8')字符串$html_str转换成'UTF-8'编码 2 $html_str = mb_convert_encoding($html_str, 'UTF-8', 'ASCII,GB2312,GBK,UTF-8'); 3 2:gbk To utf-8 4 < ?php 5 header("content-Type: text/html; charset=Utf-8"); 6 echo mb_convert_encoding("赵亚飞", "UTF-8", "GBK"); 7 ?>
注意:使用上面的函数需要安装但是需要先enable mbstring 扩展库。 在 php.ini里将; extension=php_mbstring.dll 前面的 ; 去掉
mb_convert_encoding 可以指定多种输入编码,它会根据内容自动识别,; 执行效率比iconv差很多
3:iconv 转换编码
iconv函数库能够完成各种字符集间的转换,是php编程中不可缺少的基础函数库。
需要注意一下:
iconv在转换字符有时会出错,(如果将utf-8转换为gb2312时,可能会出现字符串被截断的情况发生。)
解决方法:在需要转成的编码后加 "//IGNORE" 是iconv函数第二个参数后。
如下:
1 iconv("UTF-8","GB2312//IGNORE",$data)
ignore意思是忽略转换时的错误,如果没有ignore参数,所有该字符后面的字符串都无法被保存(不往下进行转换)。
iconv不是php的默认函数,也不是默认安装的模块。需要安装才能用的。
这里有一个自动判断编码类型,进行转化的函数:
1 function check_encod($encod,$string){ 2 //判断字符编码 3 $encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5")); 4 var_dump($encode); 5 if($encode != $encod){ 6 $string = iconv($encode, $encod, $string); 7 } 8 return $string; 9 } 10 $path = "赵亚飞。.jpg"; 11 $path = check_encod("GB2312",$path);
五:字符串截取
1:mb_substr()
PHP substr()函数可分割文字,但分割的文字如果包括中文字符往往会遇到问题,这时可以用mb_substr()这个函 数,用法与substr()相似,只是在mb_substr()最后要加入多一个参数,以设定字符串的编码, 需要打开php_mbstring.dll,需要在php.ini中把php_mbstring.dll 打开。例如:
1 echo mb_substr('赵亚飞赵亚飞er',0,9); //输出:赵亚飞 2 echo mb_substr('赵亚飞赵亚飞er',0,9,'utf-8'); //输出:赵亚飞赵亚飞er
第一个是以三个字节为一个中文,这就是utf-8编码的特点,下面加上utf-8字符集说明,是以一个字为单位来截取的
2:iconv_substr()
Substr是截取字符的函数,但是很多时候,截取中文却需要额外处理,原因是中文在UTF-8中占用3个字节,在GB2312中占用2个字节,在截取中随时存在截取的字符串长度与组成未知,所以给很多人造成了困扰。PHP5开始,iconv_substr函数出现
1 <?php 2 $str='赵z亚y飞f/include'; 3 echo substr($str,1,5); 4 echo "<br>"; 5 echo iconv_substr($str,1,5,"UTF-8"); 6 ?>
这个是在网页编码为UTF-8的PHP代码中使用的截取编码。如果在UTF-8网页中使用GB2312或者GBK编码来截取,会出错,占用字节不同;反之,在GB2312或GBK网页中,不能使用UTF-8来进行截取 。由于iconv_substr是按照字符而非占用字节来计算,所以“a”和“叶”均计算为1位。在GB2312或者GBK中,由于占用字节是一样的,所以可以随意使用GB2312或GBK编码来截取,截取结果是一样的。
3:兼容性良好的截取字符串的函数
1 function msub_str($str, $start=0, $length, $charset="utf-8", $suffix=true){ 2 if(function_exists("mb_substr")) 3 return mb_substr($str, $start, $length, $charset); 4 else if(function_exists('iconv_substr')) { 5 return iconv_substr($str,$start,$length,$charset); 6 } 7 $re['utf-8'] = "/[/x01-/x7f]|[/xc2-/xdf][/x80-/xbf]|[/xe0-/xef][/x80-/xbf]{2}|[/xf0-/xff][/x80-/xbf]{3}/"; 8 $re['gb2312'] = "/[/x01-/x7f]|[/xb0-/xf7][/xa0-/xfe]/"; 9 $re['gbk'] = "/[/x01-/x7f]|[/x81-/xfe][/x40-/xfe]/"; 10 $re['big5'] = "/[/x01-/x7f]|[/x81-/xfe]([/x40-/x7e]|/xa1-/xfe])/"; 11 preg_match_all($re[$charset], $str, $match); 12 $slice = join("",array_slice($match[0], $start, $length)); 13 if($suffix) { 14 return $slice."…"; 15 } 16 return $slice; 17 }
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

