分布式云端机器学习

原文作者:微软云信息服务实验室研究员 Dhruv Mahajan , Sundararajan Sellamanickam ,
Keerthi Selvaraj译者: 张彤
如今,各类企业都在积聚越来越庞大的数据资产,比如用户行为、系统访问、使用模式等数据记录。而运用像 微软 Azure 机器学习平台 这样的云端服务平台,企业不仅仅可以用它来储存数据,做一些经典的“后视”商务智能分析,更能使用云端的强大力量做出具有“前瞻性”的预测分析。使用 Azure 机器学习 这样的现代化工具,企业可以获得关于其业务未来发展的切实见解——这将成为它们的竞争优势。
对“大数据”的收集和维护已经成为许多应用程序的普遍需求。随着数据量的剧增,分布式储存已成为必然趋势。在许多应用中,收集数据本身就是一个分散的过程,自然导致了分布式的数据储存。这种情况下,建立起以分布式计算处理分布式数据的机器学习(以下简称“ML”)方案就十分必要。这些方案包括:通过在线广告领域的逻辑回归分析来估计点击率,应用于大量图像和语音训练的数据集的深度学习方案,或为检测异常模式而进行的记录分析。
因此,在一个集群中对 ML 方案进行高效的分布式训练,是微软云信息服务实验室(CISL——Microsoft Cloud & Information Services Lab,发音像“sizzle”:-))的重要研究领域。本文,我们将对这一主题进行一些较为深入的探讨。下面所阐述的一些细节可能技术性略强,但我们会尽可能以简单易懂的方式来阐明它的中心思想。理解了这些想法,任何对大数据分布式 ML 感兴趣的人都会有所收获,我们也很期待你们的评论和反馈。
选择合适的基础设施
John Langford 在近期发表的一篇 文章 中,介绍了用于快速学习的 Vowpal Wabbit (VW) 系统,并简要谈及了对兆级数据集的分布式学习。因为大多 ML 的算法本质上是迭代,因此选择合适的分布式框架来运行它们就变得十分关键。
Map Reduce 和它的开源实现 Hadoop ,是目前较为流行的分布式数据处理平台。但由于 ML 每次迭代都有巨大的开销——如作业调度,数据传送和数据解析,因此以上的分布式数据处理平台并不能很好的用于迭代性的 ML 算法。
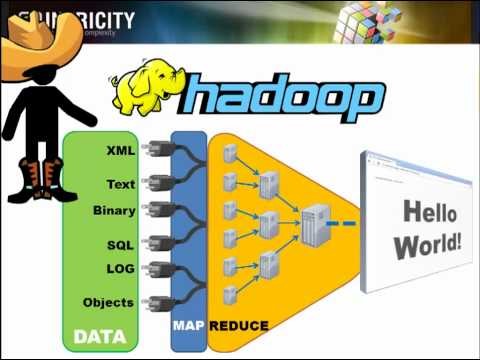
一个更好的选择是增加通信基础设施,如与 Hadoop 兼容的 All Reduce (像在 VW 中那样),或者采用更新的分布框架,如支持有效迭代运算的 REEF 。
统计查询模型 (SQM)
目前分布式 ML 最先进的算法,如用于 VW 中的是基于统计查询模型( SQM--Statistical Query Model )的算法。在 SQM 中,学习是基于对每个数据点进行计算,然后将对所有数据点的运算结果进行累加。举例来说,假设线性 ML 问题的结果是一个特征向量与其权重参数向量的点积。这包含了逻辑回归、支持向量机(SVMs)和最小二乘方拟合(least squares fitting)等重要的预测模型。在这种情况下,每次迭代时的训练目标函数的整体梯度是由各个数据点的梯度相加而成的。每个节点形成与该节点的训练数据相一致的局部梯度,然后用 All Reduce 运算来获得整体梯度。
通信瓶颈
分布式运算常常要面临一个关键瓶颈,即运算与通信宽带之间的巨大比例差。举例来说,通信速度比运算速度慢 10 倍到 50 倍都很常见。
以 Tcomm 和 Tcomp 分别表示通信和运算的单次迭代时间,那么一个迭代性 ML 算法的总时间花费可用下列算式表示:
总时间 =(Tcomm + Tcomp)* #迭代次数
当节点增多时,Tcomp 通常为线性下降,而 Tcomm 则上升或保持不变(All Reduce 良好实施的情况下)。涉及大数据的 ML 方案经常有众多的权重参数(d),这些参数在每次迭代时都会在集群中的节点间通信、更新。此外,其他步骤如 SQM 中的梯度运算也需要复杂度为O(d)的通信。这种情况在 Map Reduce 中更加不理想——每次迭代都需要一次独立的 Map Reduce 工作。因此,当参数d很大时,Tcomm 也会变得很大。SQM 并未在这方面的低效率问题上给予足够的重视。
攻克通信瓶颈问题
我们 近期的研究 正是针对这一关键问题,并建立在下述现象之上:假设 Tcomm 节点间权重参数的通信时间非常大。在每次迭代中,采用 SQM 这种标准方法会使得 Tcomp 每个节点内与运算相关的时间,远小于 Tcomm。因此我们提出以下问题,有没有可能修改算法和其迭代,使 Tcomp 与 Tcomm 接近,并且在这个过程中,将该算法转变成为迭代次数较少的理想方案呢?
当然,回答这个问题并不简单,因为它意味着一次根本性的算法改变。
更多的具体细节

接下来让我们考虑 ML 学习线性模型的问题。在我们的算法中,节点中权重更新和渐变的方式与 SQM 方式类似。然而,在每个节点中的渐变梯度(用 All Reduce 算出)和本地数据经过复杂的方式形成对全局问题的本地近似值。每个节点解决自己的近似问题,形成权重变量的本地更新,随后所有节点的本地更新结合形成权重变量的全局更新。每个节点解决近似问题时会导致其计算量增多,但不需要任何额外的通信。这样一来,虽然 Tcomp 增高,但因为 Tcomm 本身就很高,因此每次迭代花费的时间并未受到显著影响。但是,由于每个节点现在解决的是近似全局视图的问题,解决问题需要的迭代数量将大大减少。设想在无比庞大的数据中,每个节点自身的数据就足以实现良好的学习。这种情况下,每个节点形成的近似问题就近似于全局问题,这样 SQM 的算法需要几百次甚至几千次的迭代时,我们的算法只需要一或两次迭代就能完成。此外,我们的方法也较为灵活,允许出现一系列的近似值而不只是一个特定值。总体来说,我们的算法比 SQM 平均快了两到三倍。
也可以考虑将权重向量分散到多个集群节点中,建立分布式数据储存和运算方式,使任何一个权重变量的更新只发生在一个集群节点上。这在一些情况下非常有效,比如对线性 ML 问题中相关权重变量的归零问题,或者做分布式深度训练时。这样我们又一次建立了 特殊的迭代算法 ,增加了每节点内的运算但减少了迭代的次数。
评估
上述我们重点关注的算法比较适合通信负担较重的情况,但这并不能解决在实际中的所有问题。对于一般的情况,最近的学术文献中有很多好的分布式 ML 算法,但目前对这些方法还没有一个细致的评测。最好的方法还在寻找它们通往云端 ML 库的道路上。
根据用户需求的自动分布式 ML
另外,还有一个重要的部分,即在云端上使用分布式 ML 的用户拥有不同的需求。他们也许对最短时间内产生方案感兴趣,也许认为最少花费产生方案很重要。在考虑上述变量进行最优选择时,用户愿意牺牲一些精确度。另一种可能是,他们也许迫切地想知道最确切的结果,而不计时间和花费。考虑到问题描述、用户的不同要求和系统配置的可应用性细节,拥有一个能够选择合适算法和参数设定的自动程序十分重要。我们目前的研究也集中在这一方面。
在我们未来的产品发展中,自动分布式机器学习方案将会是微软 Azure ML 重要的一个研究领域。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

