参数嗅探(Parameter Sniffing)(2/2)
索引(Index)
上次我们讨论造成参数嗅探问题的根源是:在执行计划里,SQL 语句有时会产生书签查找,有时会产生表/聚集索引扫描。如果你能在数据库里修改索引,解决这个问题的最简单方法就是提供查询列对应的 覆盖非聚集索引 。这里我们就要包含书签查找的需要列,在非聚集索引的叶子层。这样做后,就可以获得 计划稳定性 :不管提供的输入任何参数,查询优化器都可以编译同样的执行计划——这里就是都会用到 索引查找(非聚集索引) 运算符。
1 DROP INDEX idx_Test ON Table1 2 CREATE NONCLUSTERED INDEX idx_Test ON Table1(Column2) INCLUDE(Column1) 3 4 SELECT * FROM dbo.Table1 WHERE Column2=1 5 SELECT * FROM dbo.Table1 WHERE Column2=2

如果你不能修改你的索引设计,可以尝试下面的方法:
重编译(Recompilation)
SQL Server提供给你的第一个选项是执行计划的重编译。它提供2个不同选项给你使用:
- 全部重编译,整个存储过程
- 有问题的SQL语句重编译,即所谓的 语句级别的重编译 (从SQL Server 2005起可用)
我们通过实例详细讲解下这2个选项。下面的语句会对整个存储过程进行重编译:
1 -- Create a new stored procedure for data retrieval 2 CREATE PROCEDURE RetrieveDataR 3 ( 4 @Col2Value INT 5 ) 6 WITH RECOMPILE 7 AS 8 SELECT * FROM Table1 9 WHERE Column2 = @Col2Value 10 GO
当你执行这样的存储过程时,查询优化器在每次执行前都会重新编译存储过程。因此你得到的执行计划都是基于目前输入的参数值。作为重编译的副作用,你的执行计划不会被缓存,对于一个每次都重编译的执行计划进行缓存是没有意义的。当你有一个大的复杂的存储过程在存储过程级别使用 RECOMPILE 选项,这样做就没太大意义,因为你的 整个 存储每次都重编译,而存储过程就是为了编译好进行重用,从而提高执行效率。
1 EXEC dbo.RetrieveDataR @Col2Value = 1 -- int 2 EXEC dbo.RetrieveDataR @Col2Value = 2 -- int
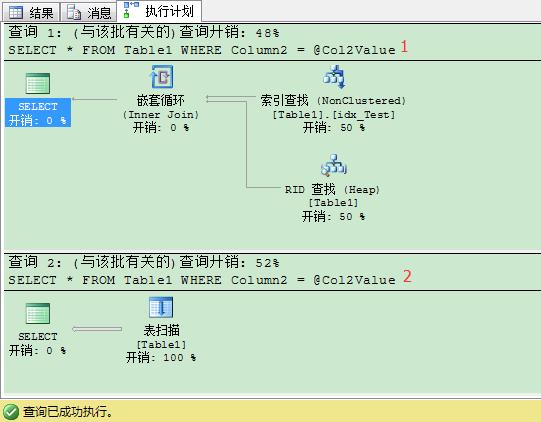
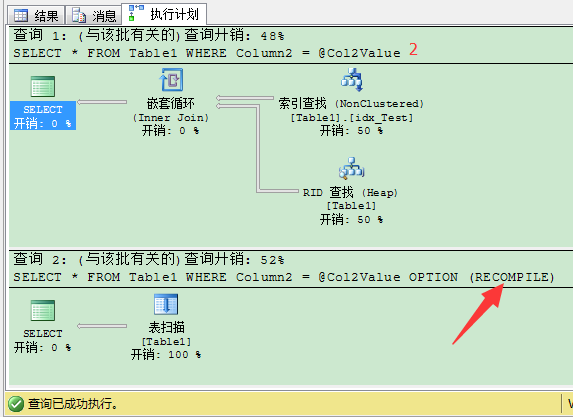
如果你的参数嗅探问题只出现在一个特定的SQL语句。那就没有必要对整个存储过程进行重编译了。因此从SQL Server2005开始,提供称为 语句级别的重编译(Statement Level Recompilation) 。你可以对需要重编译的SQL语句加上RECOMPILE查询提示而不是整个存储过程。我们来看下下面的代码:
1 -- Create a new stored procedure for data retrieval 2 CREATE PROCEDURE RetrieveDataR2 3 ( 4 @Col2Value INT 5 ) 6 AS 7 SELECT * FROM Table1 8 WHERE Column2 = @Col2Value 9 10 SELECT * FROM Table1 11 WHERE Column2 = @Col2Value 12 OPTION (RECOMPILE) 13 GO
上述例子里的第2个SQL语句在存储过程执行的时候都会重编译。第1个语句在执行初始时编译好,并生成计划缓存做后续重用。在你不想修改数据库的索引时,这个方法是处理参数嗅探的推荐方法。
1 EXEC dbo.RetrieveDataR2 @Col2Value = 2 -- int
OPTIMIZE FOR
除了存储过程或SQL语句的重编译查询提示,SQL Server也提供 OPTIMIZE FOR 的查询提示。用这个查询提示你可以告诉查询优化器哪个参数值下,对执行计划执行优化,我们看下面的例子:
1 -- Create a new stored procedure for data retrieval 2 CREATE PROCEDURE RetrieveDataOF 3 ( 4 @Col2Value INT 5 ) 6 AS 7 SELECT * FROM Table1 8 WHERE Column2 = @Col2Value 9 OPTION (OPTIMIZE FOR (@Col2Value = 1)) 10 GO
从存储过程的定义中你可以看到,SQL语句的执行计划在参数@Col2Value值为1的时候需要进行优化。不管你提供给这个参数的任何值,你都获得为值1优化的编译计划。用这个方法你已经对SQL Server放大招了,因为查询优化器没别的选项——它必须为参数值1生成优化的的执行计划。当你知道查询计划需要为指定参数进行优化时,可以使用这个方法让SQL Server对此参数的执行计划进行优化。在你重启SQL Server或执行群集故障转移时,就可以预知你的执行计划。
为了进一步保障这个选项的有效性,你就要熟悉你的数据分布情况,还有什么时候数据分布情况会改变。如果数据分布情况已经改变,你就要修改查询提示,看看是否仍然合适。你不能完全相信查询优化器,因为你已经用 OPTIMIZE FOR 查询提示重置查询优化器的选择。要记住这个。另外在提供 OPTIMIZE FOR 查询提示的同时,SQL Server也提供 OPTIMIZE FOR UNKNOWN 查询提示。如果你决定使用OPTIMIZE FOR UNKNOWN查询提示,查询优化器就使用表统计信息里的密度来做参数预估。如果逻辑读超过了 临界点 ,还是会使用表/索引扫描……
小结
在这个文章里我向你展示在SQL Server里处理参数嗅探问题的不同方式。其中造成这个问题的最常见原因是糟糕的索引设计,造成参数值传入后优化器在执行计划里选择了书签查找。如果这样的执行计划被缓存重用的话,你的I/O成本就会爆表。在生成环境中,我就看到因为这个原因就造成100GB的逻辑读。在SQL语句上加一个简单的 RECOMPILE 查询提示就可以解决这个问题,查询只会增加少量的逻辑读。
如果你不能修改数据库索引设计,你可以在存储过程或SQL语句上使用 RECOMPILE 查询提示。作为副作用编译的计划就不会缓存。除此外的查询提示,SQL Server还提供 OPTIMIZE FOR 和 OPTIMIZE FOR UNKNOWN 的查询提示。在你使用这些查询提示时,你要对你的数据和数据分布情况非常熟悉,因为你在重置优化器。请慎重使用!Be always aware of this fact!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

