我写技术博客有两个原因:一是总结自己近日的研究成果,二是将这些成果分享给大家。所以就我个人来说,还是比较希望写出来的文章有更多的人能够看到的。我最近注意到我的博客的流量大多来自于谷歌,而几乎没有来源于百度的。而本文就旨在提出这个问题,并尝试着去解决这个问题。当然,换一个云主机服务提供商能够很直接明了地解决这个问题,但这不是本文的重点,暂且不提。
为什么 Github Pages 禁用了百度爬虫?
就这个问题,我联系了 Github Support 部门,对方给我的答复是这样的:
Hi Jerry,
Sorry for the trouble with this. We are currently blocking the Baidu user agent from crawling GitHub Pages sites in response to this user agent being responsible for an excessive amount of requests, which was causing availability issues for other GitHub customers.
This is unlikely to change any time soon, so if you need the Baidu user agent to be able to crawl your site you will need to host it elsewhere.
Apologies again for the inconvenience.
Cheers, Alex
简单地来说,就是百度爬虫爬得太猛烈,已经对很多 Github 用户造成了可用性的问题了,而禁用百度爬虫这一举措可能会一直持续下去。(不知道跟之前的 Great Cannon有没有关系)
因此,只能自己动手丰衣足食了,下面来讨论一下解决这个问题的方式。
解决问题 —— CDN
我在知乎提了这样一个问题: 如何解决百度爬虫无法爬取搭建在Github上的个人博客的问题? ,并且 Stackoverflow 上也有类似的问题: github blocks Baidu spider, how can I make it work again 。两位知乎答主和Stackoverflow的评论都比较推荐使用 CDN 来解决这个问题。
那我们首先来了解一下 CDN 的原理。
CDN 的原理
CDN 的全称是 Content Delivery Network ,即内容分发网络,一般用于分发静态内容,比如图片、视频、CSS、JS文件。

如果不使用 CDN,那所有用户的请求都会直接导向单一的源服务器(Origin Server)。而如果启用了 CDN 服务,那么 CDN 服务提供商会分配给你若干个节点,这里以上图为例,比如分配给你的服务器 3 个东海岸的节点和 3 个西海岸的节点。
此时用户就不会直接向源服务器发送请求,而是向边缘服务器(Edge Server)发送请求。再看下面这张示意图,当你第一次访问资源 foo.png 时,边缘服务器没有 foo.png 的缓存。所以会由它向源服务器发送请求,并获取到 foo.png。下一次所有经过这个节点的请求,因为存在缓存的缘故,都不用再次向源服务器发送请求,而是由边缘服务器直接返回该文件的缓存即可。这样一来就可以大大降低时延,也减小了源服务器的压力。
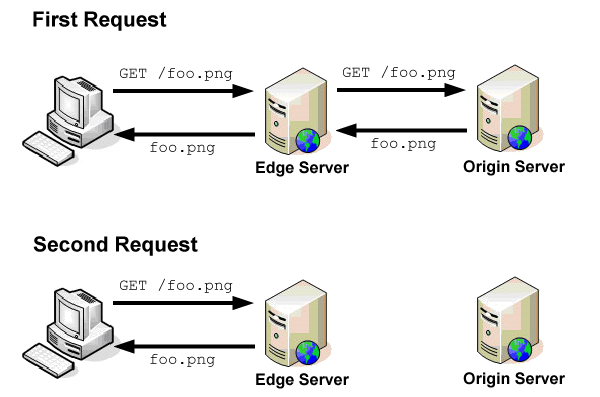
那 CDN 服务是如何决定你从哪个边缘服务器获取资源的呢?其实就是在发送 DNS 请求的时候,将你要访问的域名映射到最近的节点的 IP 上。具体判定哪个是最近的节点,最简单的策略就是根据 IP,但各个 CDN 的服务提供商的策略可能各不相同,这里就不展开讨论了。
CDN 的局限性
CDN 确实能够解决不少问题,但它本身也存在一定的局限性。其中最重要的一点是: 决不能用 CDN 来缓存动态内容 。
来看一个例子,假设服务器端有这样一个PHP文件 hello.php:
<html> <head>...</head> <body>Hello, <?= $name ?> </body> </html>如果 CDN 缓存了这个文件就会造成很糟糕的后果。比如 Jerry 先访问了 hello.php 页面,得到了 Hello, Jerry 的内容。此时这个内容已经被缓存到了节点 A,而 Tom 同学也是离节点 A 最近,那么 Tom 同学访问 hello.php 时,就会直接得到缓存内容:Hello, Jerry。这个时候 Tom 同学的内心一定是崩溃的。
你还应该 避免 使用 CDN 的情况有: 根据 user-agent 来选择返回移动版还是桌面版页面 。UA 判断这对解决我们的问题很重要,下文会提及。当然,部署在 Github Pages 上的网站都是静态站点,所有用户进来看到的内容一般是相同的。所以通过 CDN 来对全站进行缓存没有什么问题。
可行性分析
Github是通过 UA 来判定百度爬虫并返回 403 Forbidden 的。而百度爬虫的 UA 一般是这样的:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
那么使用 CDN 来解决这个问题的关键就在于,让百度爬虫不要直接向 Github 的服务器发送请求,而是通过 CDN 边缘服务器的缓存来抓取网站的内容。边缘服务器本身是不会关心 UA 的,所以问题就迎刃而解了。
可是问题真有这么简单吗?
并不是。
来看一下,我使用 百度站长工具 来进行抓取诊断的测试结果:

结果是只有偶尔能够抓取成功,结果很让人失望吧?让我们来分析以下原因,首先罗列我目前可知的一些情况:
- 所有抓取成功的页面都访问了 209.9.130.5 节点
- 所有抓取失败的页面都访问了 209.9.130.6 节点
- 我本机
ping jerryzou.com会 ping 到 209.9.130.8 节点
好了,细心的同学应该已经发现问题所在了,百度爬虫大部分的请求被导到了 209.9.130.6 节点,但是 这个节点上没有页面的缓存 !!如果百度爬虫是某个页面的第一个访问者,CDN 的边缘服务器会用百度爬虫的 UA 去请求 Github 的服务器,得到的结果自然是被拒绝了。
最终我们得到了通过 CDN 来解决这个问题的必要条件: 你的博客必须有巨大的访问量! 这样才能保证 CDN 的每一个边缘服务器上都有任何一个页面的缓存。我觉得除非像 React主页 这样的网站,不然要达到这个要求几乎不可能的。
最后,一句话总结:CDN 这一解决方案并不靠谱。
当然,不死心的我还是做了件奇怪的事……首先我在找到了 所有 BaiduSpider 的 IP ,然后想要伪装成这些 IP 来请求内容,以此想在所有百度爬虫可能爬取的边缘服务器上都建立缓存。
<?php function Curl($url, $ip){ $ch = curl_init(); curl_setopt_array($ch, [ CURLOPT_URL => $url, CURLOPT_TIMEOUT => 10, CURLOPT_HEADER => true, CURLOPT_HTTPHEADER => [ 'X-FORWARDED-FOR: '.$ip, 'CLIENT-IP: '.$ip ], CURLOPT_RETURNTRANSFER => true, CURLOPT_FOLLOWLOCATION => true, CURLOPT_NOBODY => false, CURLOPT_REFERER => 'http://test.jerryzou.com', CURLOPT_USERAGENT => 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36', ]); $response = curl_exec($ch); curl_close($ch); return $response; } $ipList = [ '203.125.234.1', '220.181.7.1', '123.125.66.1', '123.125.71.1', '119.63.192.1', '119.63.193.1', '119.63.194.1', '119.63.195.1', '119.63.196.1', '119.63.197.1', '119.63.198.1', '119.63.199.1', '180.76.5.1', '202.108.249.185', '202.108.249.177', '202.108.249.182', '202.108.249.184', '202.108.249.189', '61.135.146.200', '61.135.145.221', '61.135.145.207', '202.108.250.196', '68.170.119.76', '207.46.199.52', ]; foreach ($ipList as $ip) { Curl('http://jerryzou.com', $ip); echo "$ip/n"; } echo "Done/n"; 然而并没有卵用……
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

