索引键的唯一性(2/4):唯一与非唯一聚集索引
在上一篇文章里,我们讨论了 堆表上唯一/非唯一非聚集索引 。在SQL Server里没有聚集索引定义的叫 堆表 。当你在堆表上定义了一个聚集索引,你的表数据就会重组按聚集键的顺序进行物理存储,因为这个表叫做 聚集表 。这篇文章里,我想谈下唯一和非唯一聚集索引之间的区别,这2类聚集索引对存储的影响。
看这个文章之前,希望你对聚集索引有个基本的认识,并且知道堆表和聚集表之间的区别,还有当在表上定义了一个聚集索引,表里数据页是如何组织的(B树结构)。
我们从唯一聚集索引谈起。在SQL Server里你有很多方法去定义唯一聚集索引。第1个最简单的方法就是列上定义一个 主键(PRIMARY KEY) 约束。SQL Server通过在表上创建那列的唯一聚集索引来施行 主键(PRIMARY KEY) 约束。另外一个方法是通过 CREATE CLUSTERED INDEX 语句来常见唯一聚集索引——但当你不指定 UNIQUE 属性时,SQL Server默认是会为你创建非唯一的聚集索引!下列这段代码会创建 Customers 表,这个表结构和上篇文章一样,但这次我们在 CustomerID 列创建 主键(PRIMARY KEY) 约束。因此SQL Server会在表上创建唯一聚集索引,在叶子层里,数据页是按 CustomerID 列值排序的。
1 -- Create a table with 393 length + 7 bytes overhead = 400 bytes 2 -- Therefore 20 records can be stored on one page (8.096 / 400) = 20,24 3 CREATE TABLE Customers 4 ( 5 CustomerID INT NOT NULL PRIMARY KEY IDENTITY(1, 1), 6 CustomerName CHAR(100) NOT NULL, 7 CustomerAddress CHAR(100) NOT NULL, 8 Comments CHAR(189) NOT NULL 9 ) 10 GO 11 12 -- Insert 80.000 records 13 DECLARE @i INT = 1 14 WHILE (@i <= 80000) 15 BEGIN 16 INSERT INTO Customers VALUES 17 ( 18 'CustomerName' + CAST(@i AS CHAR), 19 'CustomerAddress' + CAST(@i AS CHAR), 20 'Comments' + CAST(@i AS CHAR) 21 ) 22 23 SET @i += 1 24 END 25 GO
我们可以通过 DBCC IND 命令找出索引根页后(PageType为2,IndexLevel为2,即B树有3层:根和叶子层,PagePID为15359),就可以使用 DBCC PAGE 查看根页的内容。这里我的索引根页是15359。
1 TRUNCATE TABLE dbo.sp_table_pages 2 INSERT INTO dbo.sp_table_pages 3 EXEC('DBCC IND(ALLOCATIONDB, Customers, -1)') 4 5 SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC

1 DBCC PAGE(ALLOCATIONDB, 1, 15359, 3) 2 GO
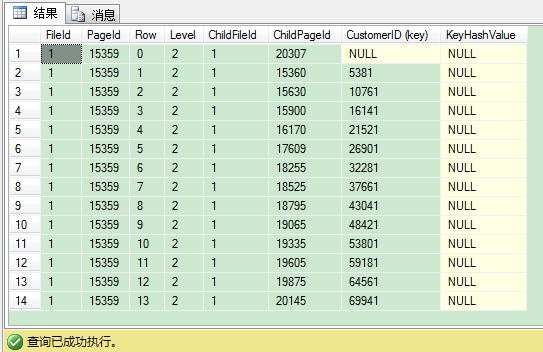
从上图里,我们可以看到每个索引记录包含聚集键,在这个例子是 CustomerID 列的值。
如果你从字节存储级别分析聚集索引记录的话,你会发现SQL Server这里使用下列字节信息:
- 1 byte:状态位
- n bytes:聚集键——这个例子里是4 bytes
- 4 bytes:页ID(PageID)
- 2 bytes:文件ID(FileID)
可以看出,聚集键的长度直接影响索引记录的长度。这就是说,你的聚集键长度越小,索引页上就可以存放更多的索引记录,因此你的聚集索引将更紧凑,查找更快,维护更容易。当你在你的聚集索引继续往下看时,你会发现所有中间层的索引结构和刚才的描述完全一样。这2层是没有任何区别的,除了索引叶子层,因为这层包含你实际逻辑排序的数据页。
现在我们来看看SQL Server里非唯一聚集索引,看看它们和唯一聚集索引的区别。为了演示这类索引,我重建了 Customers 表,并通过 CREATE CLUSTERED INDEX 语句在表上创建了非唯一聚集索引。
1 DROP TABLE dbo.Customers 2 -- Create a table with 393 length + 7 bytes overhead = 400 bytes 3 -- Therefore 20 records can be stored on one page (8.096 / 400) = 20,24 4 CREATE TABLE Customers 5 ( 6 CustomerID INT NOT NULL, 7 CustomerName CHAR(100) NOT NULL, 8 CustomerAddress CHAR(100) NOT NULL, 9 Comments CHAR(181) NOT NULL 10 ) 11 GO 12 13 -- Create a non unique clustered index 14 CREATE CLUSTERED INDEX idx_Customers_CustomerID 15 ON Customers(CustomerID) 16 GO
最后,我插入80000条记录,这些记录的 CustomerID 列(聚集键)不再唯一:
1 -- Insert 80.000 records 2 DECLARE @i INT = 1 3 WHILE (@i <= 20000) 4 BEGIN 5 INSERT INTO Customers VALUES 6 ( 7 @i, 8 ‘CustomerName’ + CAST(@i AS CHAR), 9 ‘CustomerAddress’ + CAST(@i AS CHAR), 10 ‘Comments’ + CAST(@i AS CHAR) 11 ) 12 INSERT INTO Customers VALUES 13 ( 14 @i, 15 ‘CustomerName’ + CAST(@i AS CHAR), 16 ‘CustomerAddress’ + CAST(@i AS CHAR), 17 ‘Comments’ + CAST(@i AS CHAR) 18 ) 19 INSERT INTO Customers VALUES 20 ( 21 @i, 22 ‘CustomerName’ + CAST(@i AS CHAR), 23 ‘CustomerAddress’ + CAST(@i AS CHAR), 24 ‘Comments’ + CAST(@i AS CHAR) 25 ) 26 27 INSERT INTO Customers VALUES 28 ( 29 @i, 30 ‘CustomerName’ + CAST(@i AS CHAR), 31 ‘CustomerAddress’ + CAST(@i AS CHAR), 32 ‘Comments’ + CAST(@i AS CHAR) 33 ) 34 35 SET @i += 1 36 END 37 GO
我们找下这个非唯一聚集索引的根页:
1 TRUNCATE TABLE dbo.sp_table_pages 2 INSERT INTO dbo.sp_table_pages 3 EXEC('DBCC IND(ALLOCATIONDB, Customers, -1)') 4 5 SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC
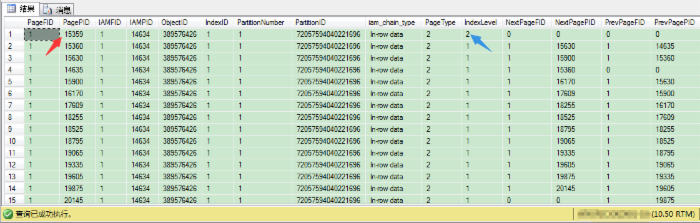
我们再来看看根页的内容:
1 DBCC PAGE(ALLOCATIONDB, 1, 15359, 3) 2 GO
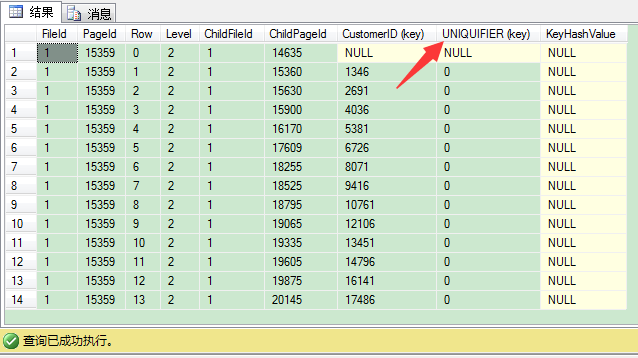
我们发现,SQL Server这里增加了 UNIQUIFIER (key) 的额外列。这列是SQL Server用来保证非唯一聚集键唯一。UNIQUIFIER (key)是4 bytes始于0的长整型值。当你有2条CustomerID值都是1380时,第1条的UNIQUIFIER为0,第2条的UNIQUIFIER值为1。但SQL Server只在索引的导航结构(高于叶子层的所有层)里保存UNIQUIFIER,即叶子层的UNIQUIFIER不为0。SQL Server只在非唯一聚集索引的导航结构里包含0值的UNIQUIFIER,这就是说导航结构里是不物理保存UNIQUIFIER的。在非唯一聚集索引里,唯一保存UNIQUIFIER的地方是在数据页,就是保存实际数据的地方。下图是我们聚集聚集索引里的中间层,你会看到UNIQUIFIER在这里是保存的。
1 DBCC PAGE(ALLOCATIONDB, 1, 15359, 3) 2 GO 3 4 DBCC PAGE(ALLOCATIONDB, 1, 14635, 3) 5 GO
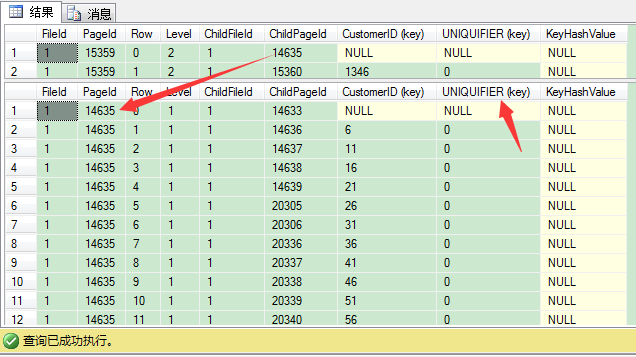
最后我们看看数据页14633:
1 DBCC TRACEON(3604) 2 DBCC PAGE(ALLOCATIONDB, 1, 14633, 3) with tableresults 3 GO
我们来找4条CustomerID值为1的记录,看看UNIQUIFIER的值是多少(应该是0,1,2,3)。
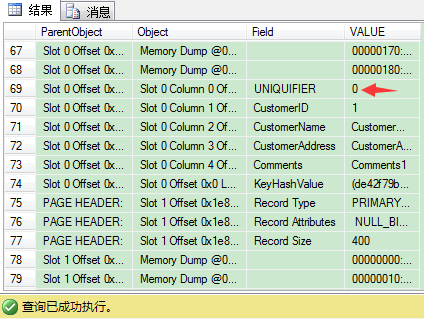
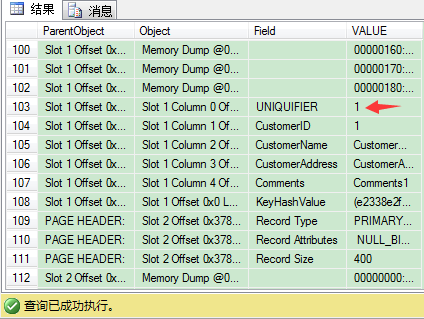
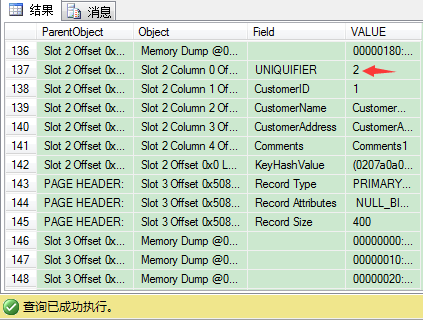
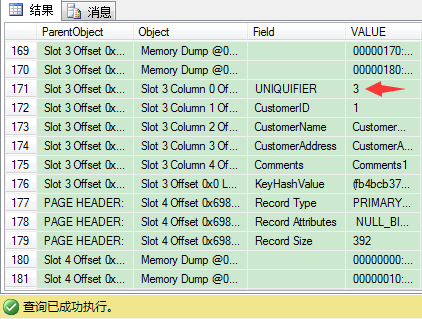
因此唯一和非唯一聚集索引的区别是在数据页,因为当使用非唯一聚集索引时,SQL Server使用4 bytes长的UNIQUIFIER来保证它们唯一,要记住,在你定义非唯一聚集索引时,这个额外开销始终存在。
下面文章我们会详细分析下唯一聚集索引上,唯一和非唯一非聚集索引的区别。请继续关注!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

