CGroup 介绍、应用实例及原理描述
CGroup 介绍
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。2007 年进入 Linux 2.6.24 内核,CGroups 不是全新创造的,它将进程管理从 cpuset 中剥离出来,作者是 Google 的 Paul Menage。CGroups 也是 LXC 为实现虚拟化所使用的资源管理手段。
CGroup 功能及组成
CGroup 是将任意进程进行分组化管理的 Linux 内核功能。CGroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 CGroup 子系统或控制器。CGroup 子系统有控制内存的 Memory 控制器、控制进程调度的 CPU 控制器等。运行中的内核可以使用的 Cgroup 子系统由/proc/cgroup 来确认。
CGroup 提供了一个 CGroup 虚拟文件系统,作为进行分组管理和各子系统设置的用户接口。要使用 CGroup,必须挂载 CGroup 文件系统。这时通过挂载选项指定使用哪个子系统。
CGroup 支持的文件种类
表 1. CGroup 支持的文件种类
| 文件名 | R/W | 用途 |
|---|---|---|
| Release_agent | RW | 删除分组时执行的命令,这个文件只存在于根分组 |
| Notify_on_release | RW | 设置是否执行 release_agent。为 1 时执行 |
| Tasks | RW | 属于分组的线程 TID 列表 |
| Cgroup.procs | R | 属于分组的进程 PID 列表。仅包括多线程进程的线程 leader 的 TID,这点与 tasks 不同 |
| Cgroup.event_control | RW | 监视状态变化和分组删除事件的配置文件 |
CGroup 相关概念解释
-
任务(task)。在 cgroups 中,任务就是系统的一个进程;
-
控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;
-
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;
-
子系统(subsystem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
相互关系
-
每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员;
-
一个子系统最多只能附加到一个层级;
-
一个层级可以附加多个子系统;
-
一个任务可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级;
-
系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
图 1. CGroup 层级图

图 1 所示的 CGroup 层级关系显示,CPU 和 Memory 两个子系统有自己独立的层级系统,而又通过 Task Group 取得关联关系。
CGroup 特点
-
在 cgroups 中,任务就是系统的一个进程。
-
控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制。
-
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
-
子系统(subsytem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
CGroup 应用架构
图 2. CGroup 典型应用架构图
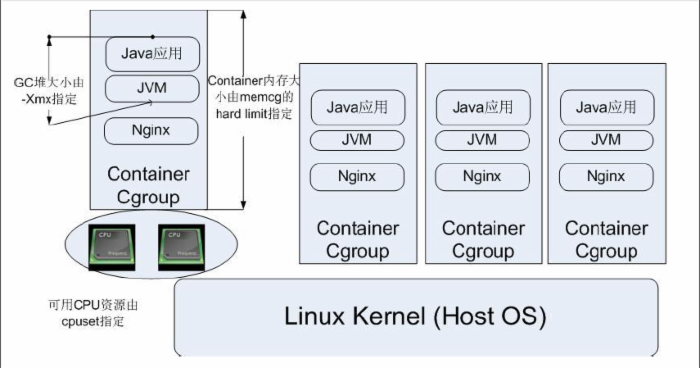
如图 2 所示,CGroup 技术可以被用来在操作系统底层限制物理资源,起到 Container 的作用。图中每一个 JVM 进程对应一个 Container Cgroup 层级,通过 CGroup 提供的各类子系统,可以对每一个 JVM 进程对应的线程级别进行物理限制,这些限制包括 CPU、内存等等许多种类的资源。下一部分会具体对应用程序进行 CPU 资源隔离进行演示。
回页首
CGroup 部署及应用实例
讲解 CGroup 设计原理前,我们先来做一个简单的实验。实验基于 Linux Centosv6.564 位版本,JDK1.7。实验目的是运行一个占用 CPU 的 Java 程序,如果不用 CGroup 物理隔离 CPU 核,那程序会由操作系统层级自动挑选 CPU 核来运行程序。由于操作系统层面采用的是时间片轮询方式随机挑选 CPU 核作为运行容器,所以会在本机器上 24 个 CPU 核上随机执行。如果采用 CGroup 进行物理隔离,我们可以选择某些 CPU 核作为指定运行载体。
清单 1.Java 程序代码
//开启 4 个用户线程,其中 1 个线程大量占用 CPU 资源,其他 3 个线程则处于空闲状态 public class HoldCPUMain { public static class HoldCPUTask implements Runnable{ @Override public void run() { // TODO Auto-generated method stub while(true){ double a = Math.random()*Math.random();//占用 CPU System.out.println(a); } } } public static class LazyTask implements Runnable{ @Override public void run() { // TODO Auto-generated method stub while(true){ try { Thread.sleep(1000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); }//空闲线程 } } } public static void main(String[] args){ for(int i=0;i<10;i++){ new Thread(new HoldCPUTask()).start(); } } } 清单 1 程序会启动 10 个线程,这 10 个线程都在做占用 CPU 的计算工作,它们可能会运行在 1 个 CPU 核上,也可能运行在多个核上,由操作系统决定。我们稍后会在 Linux 机器上通过命令在后台运行清单 1 程序。本实验需要对 CPU 资源进行限制,所以我们在 cpu_and_set 子系统上创建自己的层级“zhoumingyao”。
清单 2. 创建层级
[root@facenode4 cpu_and_set]# ls -rlt 总用量 0 -rw-r--r-- 1 root root 0 3 月 21 17:21 release_agent -rw-r--r-- 1 root root 0 3 月 21 17:21 notify_on_release -r--r--r-- 1 root root 0 3 月 21 17:21 cpu.stat -rw-r--r-- 1 root root 0 3 月 21 17:21 cpu.shares -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.sched_relax_domain_level -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.sched_load_balance -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.mems -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.memory_spread_slab -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.memory_spread_page -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.memory_pressure_enabled -r--r--r-- 1 root root 0 3 月 21 17:21 cpuset.memory_pressure -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.memory_migrate -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.mem_hardwall -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.mem_exclusive -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.cpus -rw-r--r-- 1 root root 0 3 月 21 17:21 cpuset.cpu_exclusive -rw-r--r-- 1 root root 0 3 月 21 17:21 cpu.rt_runtime_us -rw-r--r-- 1 root root 0 3 月 21 17:21 cpu.rt_period_us -rw-r--r-- 1 root root 0 3 月 21 17:21 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 3 月 21 17:21 cpu.cfs_period_us -r--r--r-- 1 root root 0 3 月 21 17:21 cgroup.procs drwxr-xr-x 2 root root 0 3 月 21 17:22 test drwxr-xr-x 2 root root 0 3 月 23 16:36 test1 -rw-r--r-- 1 root root 0 3 月 25 19:23 tasks drwxr-xr-x 2 root root 0 3 月 31 19:32 single drwxr-xr-x 2 root root 0 3 月 31 19:59 single1 drwxr-xr-x 2 root root 0 3 月 31 19:59 single2 drwxr-xr-x 2 root root 0 3 月 31 19:59 single3 drwxr-xr-x 3 root root 0 4 月 3 17:34 aaaa [root@facenode4 cpu_and_set]# mkdir zhoumingyao [root@facenode4 cpu_and_set]# cd zhoumingyao [root@facenode4 zhoumingyao]# ls -rlt 总用量 0 -rw-r--r-- 1 root root 0 4 月 30 14:03 tasks -rw-r--r-- 1 root root 0 4 月 30 14:03 notify_on_release -r--r--r-- 1 root root 0 4 月 30 14:03 cpu.stat -rw-r--r-- 1 root root 0 4 月 30 14:03 cpu.shares -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.sched_relax_domain_level -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.sched_load_balance -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.mems -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.memory_spread_slab -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.memory_spread_page -r--r--r-- 1 root root 0 4 月 30 14:03 cpuset.memory_pressure -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.memory_migrate -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.mem_hardwall -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.mem_exclusive -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.cpus -rw-r--r-- 1 root root 0 4 月 30 14:03 cpuset.cpu_exclusive -rw-r--r-- 1 root root 0 4 月 30 14:03 cpu.rt_runtime_us -rw-r--r-- 1 root root 0 4 月 30 14:03 cpu.rt_period_us -rw-r--r-- 1 root root 0 4 月 30 14:03 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 4 月 30 14:03 cpu.cfs_period_us -r--r--r-- 1 root root 0 4 月 30 14:03 cgroup.procs
通过 mkdir 命令新建文件夹 zhoumingyao,由于已经预先加载 cpu_and_set 子系统成功,所以当文件夹创建完毕的同时,cpu_and_set 子系统对应的文件夹也会自动创建。
运行 Java 程序前,我们需要确认 cpu_and_set 子系统安装的目录,如清单 3 所示。
清单 3. 确认目录
[root@facenode4 zhoumingyao]# lscgroup cpuacct:/ devices:/ freezer:/ net_cls:/ blkio:/ memory:/ memory:/test2 cpuset,cpu:/ cpuset,cpu:/zhoumingyao cpuset,cpu:/aaaa cpuset,cpu:/aaaa/bbbb cpuset,cpu:/single3 cpuset,cpu:/single2 cpuset,cpu:/single1 cpuset,cpu:/single cpuset,cpu:/test1 cpuset,cpu:/test
输出显示 cpuset_cpu 的目录是 cpuset,cpu:/zhoumingyao,由于本实验所采用的 Java 程序是多线程程序,所以需要使用 cgexec 命令来帮助启动,而不能如网络上有些材料所述,采用 java –jar 命令启动后,将 pid 进程号填入 tasks 文件即可的错误方式。清单 4 即采用 cgexec 命令启动 java 程序,需要使用到清单 3 定位到的 cpuset_cpu 目录地址。
清单 4. 运行 Java 程序
[root@facenode4 zhoumingyao]# cgexec -g cpuset,cpu:/zhoumingyao java -jar test.jars
我们在 cpuset.cpus 文件中设置需要限制只有 0-10 这 11 个 CPU 核可以被用来运行上述清单 4 启动的 Java 多线程程序。当然 CGroup 还可以限制具体每个核的使用百分比,这里不再做过多的描述,请读者自行翻阅 CGroup 官方材料。
清单 5.cpu 核限制
[root@facenode4 zhoumingyao]# cat cpuset.cpus 0-10
接下来,通过 TOP 命令获得清单 4 启动的 Java 程序的所有相关线程 ID,将这些 ID 写入到 Tasks 文件。
清单 6. 设置线程 ID
[root@facenode4 zhoumingyao]# cat tasks 2656 2657 2658 2659 2660 2661 2662 2663 2664 2665 2666 2667 2668 2669 2670 2671 2672 2673 2674 2675 2676 2677 2678 2679 2680 2681 2682 2683 2684 2685 2686 2687 2688 2689 2714 2715 2716 2718
全部设置完毕后,我们可以通过 TOP 命令查看具体的每一颗 CPU 核上的运行情况,发现只有 0-10 这 11 颗 CPU 核上有计算资源被调用,可以进一步通过 TOP 命令确认全部都是清单 4 所启动的 Java 多线程程序的线程。
清单 7. 运行结果
top - 14:43:24 up 44 days, 59 min, 6 users, load average: 0.47, 0.40, 0.33 Tasks: 715 total, 1 running, 714 sleeping, 0 stopped, 0 zombie Cpu0 : 0.7%us, 0.3%sy, 0.0%ni, 99.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu1 : 1.0%us, 0.7%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 0.3%us, 0.3%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 1.0%us, 1.6%sy, 0.0%ni, 97.5%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu4 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu5 : 1.3%us, 1.9%sy, 0.0%ni, 96.8%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu6 : 3.8%us, 5.4%sy, 0.0%ni, 90.8%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu7 : 7.7%us, 9.9%sy, 0.0%ni, 82.4%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu8 : 4.8%us, 6.1%sy, 0.0%ni, 89.1%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu9 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu10 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu11 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu12 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu13 : 0.0%us, 0.0%sy, 0.0%ni, 72.8%id, 0.0%wa, 0.0%hi, 4.3%si, 0.0%st Cpu14 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu15 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu16 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu17 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu18 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu19 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu20 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu21 : 0.3%us, 0.3%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu22 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu23 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32829064k total, 5695012k used, 27134052k free, 533516k buffers Swap: 24777720k total, 0k used, 24777720k free, 3326940k cached
总体上来说,CGroup 的使用方式较为简单,目前主要的问题是网络上已有的中文材料缺少详细的配置步骤,一旦读者通过反复实验,掌握了配置方式,使用上应该不会有大的问题。
回页首
Cgroup 设计原理分析
CGroups 的源代码较为清晰,我们可以从进程的角度出发来剖析 cgroups 相关数据结构之间的关系。在 Linux 中,管理进程的数据结构是 task_struct,其中与 cgroups 有关的代码如清单 8 所示:
清单 8.task_struct 代码
#ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock */ struct css_set *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock */ struct list_head cg_list; #endif
其中 cgroups 指针指向了一个 css_set 结构,而 css_set 存储了与进程有关的 cgroups 信息。cg_list 是一个嵌入的 list_head 结构,用于将连到同一个 css_set 的进程组织成一个链表。下面我们来看 css_set 的结构,代码如清单 9 所示:
清单 9.css_set 代码
struct css_set { atomic_t refcount; struct hlist_node hlist; struct list_head tasks; struct list_head cg_links; struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; struct rcu_head rcu_head; }; 其中 refcount 是该 css_set 的引用数,因为一个 css_set 可以被多个进程公用,只要这些进程的 cgroups 信息相同,比如:在所有已创建的层级里面都在同一个 cgroup 里的进程。hlist 是嵌入的 hlist_node,用于把所有 css_set 组织成一个 hash 表,这样内核可以快速查找特定的 css_set。tasks 指向所有连到此 css_set 的进程连成的链表。cg_links 指向一个由 struct_cg_cgroup_link 连成的链表。
Subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。一个 cgroup_subsys_state 就是进程与一个特定子系统相关的信息。通过这个指针数组,进程就可以获得相应的 cgroups 控制信息了。cgroup_subsys_state 结构如清单 10 所示:
清单 10.cgroup_subsys_state 代码
struct cgroup_subsys_state { struct cgroup *cgroup; atomic_t refcnt; unsigned long flags; struct css_id *id; }; cgroup 指针指向了一个 cgroup 结构,也就是进程属于的 cgroup。进程受到子系统的控制,实际上是通过加入到特定的 cgroup 实现的,因为 cgroup 在特定的层级上,而子系统又是附和到上面的。通过以上三个结构,进程就可以和 cgroup 连接起来了:task_struct->css_set->cgroup_subsys_state->cgroup。cgroup 结构如清单 11 所示:
清单 11.cgroup 代码
struct cgroup { unsigned long flags; atomic_t count; struct list_head sibling; struct list_head children; struct cgroup *parent; struct dentry *dentry; struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; struct cgroupfs_root *root; struct cgroup *top_cgroup; struct list_head css_sets; struct list_head release_list; struct list_head pidlists; struct mutex pidlist_mutex; struct rcu_head rcu_head; struct list_head event_list; spinlock_t event_list_lock; }; sibling,children 和 parent 三个嵌入的 list_head 负责将统一层级的 cgroup 连接成一棵 cgroup 树。
subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。这组指针指向了此 cgroup 跟各个子系统相关的信息,这个跟 css_set 中的道理是一样的。
root 指向了一个 cgroupfs_root 的结构,就是 cgroup 所在的层级对应的结构体。这样一来,之前谈到的几个 cgroups 概念就全部联系起来了。
top_cgroup 指向了所在层级的根 cgroup,也就是创建层级时自动创建的那个 cgroup。
css_set 指向一个由 struct_cg_cgroup_link 连成的链表,跟 css_set 中 cg_links 一样。
下面分析一个 css_set 和 cgroup 之间的关系,cg_cgroup_link 的结构如清单 12 所示:
清单 12.cg_cgroup_link 代码
struct cg_cgroup_link { struct list_head cgrp_link_list; struct cgroup *cgrp; struct list_head cg_link_list; struct css_set *cg; }; cgrp_link_list 连入到 cgrouo->css_set 指向的链表,cgrp 则指向此 cg_cgroup_link 相关的 cgroup。
cg_link_list 则连入到 css_set->cg_lonks 指向的链表,cg 则指向此 cg_cgroup_link 相关的 css_set。
cgroup 和 css_set 是一个多对多的关系,必须添加一个中间结构来将两者联系起来,这就是 cg_cgroup_link 的作用。cg_cgroup_link 中的 cgrp 和 cg 就是此结构提的联合主键,而 cgrp_link_list 和 cg_link_list 分别连入到 cgroup 和 css_set 相应的链表,使得能从 cgroup 或 css_set 都可以进行遍历查询。
那为什么 cgroup 和 css_set 是多对多的关系呢?
一个进程对应一个 css_set,一个 css_set 存储了一组进程 (有可能被多个进程共享,所以是一组) 跟各个子系统相关的信息,但是这些信息由可能不是从一个 cgroup 那里获得的,因为一个进程可以同时属于几个 cgroup,只要这些 cgroup 不在同一个层级。举个例子:我们创建一个层级 A,A 上面附加了 cpu 和 memory 两个子系统,进程 B 属于 A 的根 cgroup;然后我们再创建一个层级 C,C 上面附加了 ns 和 blkio 两个子系统,进程 B 同样属于 C 的根 cgroup;那么进程 B 对应的 cpu 和 memory 的信息是从 A 的根 cgroup 获得的,ns 和 blkio 信息则是从 C 的根 cgroup 获得的。因此,一个 css_set 存储的 cgroup_subsys_state 可以对应多个 cgroup。另一方面,cgroup 也存储了一组 cgroup_subsys_state,这一组 cgroup_subsys_state 则是 cgroup 从所在的层级附加的子系统获得的。一个 cgroup 中可以有多个进程,而这些进程的 css_set 不一定都相同,因为有些进程可能还加入了其他 cgroup。但是同一个 cgroup 中的进程与该 cgroup 关联的 cgroup_subsys_state 都受到该 cgroup 的管理 (cgroups 中进程控制是以 cgroup 为单位的) 的,所以一个 cgroup 也可以对应多个 css_set。
从前面的分析,我们可以看出从 task 到 cgroup 是很容易定位的,但是从 cgroup 获取此 cgroup 的所有的 task 就必须通过这个结构了。每个进程都回指向一个 css_set,而与这个 css_set 关联的所有进程都会链入到 css_set->tasks 链表,而 cgroup 又通过一个中间结构 cg_cgroup_link 来寻找所有与之关联的所有 css_set,从而可以得到与 cgroup 关联的所有进程。最后,我们看一下层级和子系统对应的结构体。层级对应的结构体是 cgroupfs_root 如清单 13 所示:
清单 13.cgroupfs_root 代码
struct cgroupfs_root { struct super_block *sb; unsigned long subsys_bits; int hierarchy_id; unsigned long actual_subsys_bits; struct list_head subsys_list; struct cgroup top_cgroup; int number_of_cgroups; struct list_head root_list; unsigned long flags; char release_agent_path[PATH_MAX]; char name[MAX_CGROUP_ROOT_NAMELEN]; }; sb 指向该层级关联的文件系统数据块。subsys_bits 和 actual_subsys_bits 分别指向将要附加到层级的子系统和现在实际附加到层级的子系统,在子系统附加到层级时使用。hierarchy_id 是该层级唯一的 id。top_cgroup 指向该层级的根 cgroup。number_of_cgroups 记录该层级 cgroup 的个数。root_list 是一个嵌入的 list_head,用于将系统所有的层级连成链表。子系统对应的结构体是 cgroup_subsys,代码如清单 14 所示。
清单 14. cgroup_subsys 代码
struct cgroup_subsys { struct cgroup_subsys_state *(*create)(struct cgroup_subsys *ss, struct cgroup *cgrp); int (*pre_destroy)(struct cgroup_subsys *ss, struct cgroup *cgrp); void (*destroy)(struct cgroup_subsys *ss, struct cgroup *cgrp); int (*can_attach)(struct cgroup_subsys *ss, struct cgroup *cgrp, struct task_struct *tsk, bool threadgroup); void (*cancel_attach)(struct cgroup_subsys *ss, struct cgroup *cgrp, struct task_struct *tsk, bool threadgroup); void (*attach)(struct cgroup_subsys *ss, struct cgroup *cgrp, struct cgroup *old_cgrp, struct task_struct *tsk, bool threadgroup); void (*fork)(struct cgroup_subsys *ss, struct task_struct *task); void (*exit)(struct cgroup_subsys *ss, struct task_struct *task); int (*populate)(struct cgroup_subsys *ss, struct cgroup *cgrp); void (*post_clone)(struct cgroup_subsys *ss, struct cgroup *cgrp); void (*bind)(struct cgroup_subsys *ss, struct cgroup *root); int subsys_id; int active; int disabled; int early_init; bool use_id; #define MAX_CGROUP_TYPE_NAMELEN 32 const char *name; struct mutex hierarchy_mutex; struct lock_class_key subsys_key; struct cgroupfs_root *root; struct list_head sibling; struct idr idr; spinlock_t id_lock; struct module *module; }; cgroup_subsys 定义了一组操作,让各个子系统根据各自的需要去实现。这个相当于 C++中抽象基类,然后各个特定的子系统对应 cgroup_subsys 则是实现了相应操作的子类。类似的思想还被用在了 cgroup_subsys_state 中,cgroup_subsys_state 并未定义控制信息,而只是定义了各个子系统都需要的共同信息,比如该 cgroup_subsys_state 从属的 cgroup。然后各个子系统再根据各自的需要去定义自己的进程控制信息结构体,最后在各自的结构体中将 cgroup_subsys_state 包含进去,这样通过 Linux 内核的 container_of 等宏就可以通过 cgroup_subsys_state 来获取相应的结构体。
从基本层次顺序定义上来看,由 task_struct、css_set、cgroup_subsys_state、cgroup、cg_cgroup_link、cgroupfs_root、cgroup_subsys 等结构体组成的 CGroup 可以基本从进程级别反应之间的响应关系。后续文章会针对文件系统、各子系统做进一步的分析。
回页首
结束语
就象大多数开源技术一样,CGroup 不是全新创造的,它将进程管理从 cpuset 中剥离出来。通过物理限制的方式为进程间资源控制提供了简单的实现方式,为 Linux Container 技术、虚拟化技术的发展奠定了技术基础,本文的目标是让初学者可以通过自己动手的方式简单地理解技术,将起步门槛放低。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

