利用GPU和Caffe训练神经网络
【编者按】 本文为利用GPU和Caffe训练神经网络的实战教程,介绍了根据Kaggle的“奥托集团产品分类挑战赛”的数据进行训练一种多层前馈网络模型的方法,如何将模型应用于新数据,以及如何将网络图和训练权值可视化。
Caffe是由 贾扬清 发起的一个开源深度学习框架,它允许你利用你的GPU训练神经网络。相对于其他的深度学习框架如Theano或Torch等,Caffe不需要你自己编写算法程序,你只需要通过配置文件来指定网络。显然,这种做法比自己编写所有程序更加节省时间,也将你限制在一定的框架范围内。不过,在大多数情况下,这没有太大的问题,因为Caffe提供的框架相当强大,并且不断进步。
这篇文章的主题由一种多层前馈网络组成。该模型将根据Kaggle的“ 奥托集团产品分类挑战赛 ”的数据进行训练。我们还关注将模型应用于新数据,以及如何将网络图(network graph)和训练得到的权值可视化。限于篇幅,本文不会解释所有的细节。另外,简单的代码比一千多字的话更有说服力。相对于对照 IPython Notebook 来程序化细节,本文将着重描述观念以及一些我遇到的绊脚石。
设置
如果你还没有把Caffe安装在你的系统上,我建议在一个允许GPU处理的EC2实例上工作,例如g2.2xlarge实例。有关如何使用EC2工作的介绍可以查看 Guide to EC2 from the Command Line ,设置Caffe及其准备工作可以参考 GPU Powered Deep Learning with NVIDIA DIGITS on EC2 。对于使用Caffe,我也建议你在你的实例上安装IPython Notebook——在 这里 可以找到教程。
定义模型和元参数
一个模型及其应用的训练至少需要三个配置文件。这些配置文件的格式遵循界面描述语言,称为协议缓冲区( protocol buffers )。它表面上类似于JSON,但却又显著不同,实际上应该在需要进行验证(通过自定义模式的方式——像Caffe的 这个 这样)和序列化的数据文档中取代它。
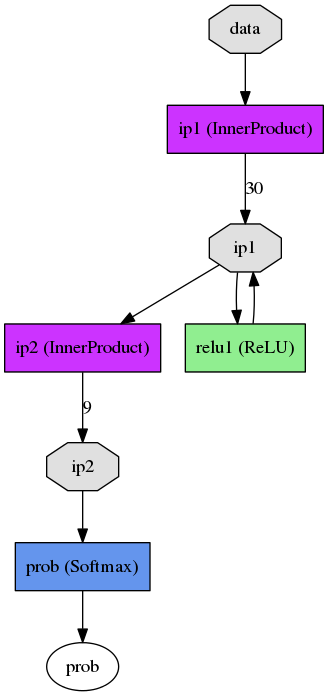
为了训练,你必须有一个prototxt文件保持训练的元参数( config.prototxt )以及一个模型用于定义网络图形( model_train_test.prototxt )——以非周期和定向的方式连接各层。需要注意的是,数据从底部流向到顶部时伴随着关于怎样指定层的顺序。这里的示例网络有五个层次:
- 数据层(一个用于训练,一个用于测试)
- 内积层(权值Ⅰ)
- ReLUs(隐含层)
- 内积层(权值Ⅱ)
- 输出层(用于分类的Soft Max)
A,Soft Max层给出损失
B,准确性层——允许我们看到网络如何在训练的同时提升。
以下从model_train_test.prototxt的摘录显示层(4)和(5A):
[...] layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" inner_product_param { num_output: 9 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "accuracy" type: "Accuracy" bottom: "ip2" bottom: "label" top: "accuracy" include { phase: TEST } } [...] 第三个prototxt文件( model_prod.prototxt )指定应用于它的网络。在这种情况下,它与训练规范大体上是一致的——但它缺乏数据层(因为我们不从产品的数据源中读取数据)并且Soft Max层不会产生损耗值但有分类的可能。另外,准确性层现在已经没有了。还要注意的是,我们现在在开始指定输入尺寸(如预期:1,93,1,1)——它是肯定混乱的,所有四个尺寸被称为input_dim,只有顺序定义哪个是哪个,并没有指定明确的背景。
支持的数据源
这是开始尝试使用Caffe时要克服的首要心理障碍之一。它不像使用一些CSV来提供Caffe可执行的方式那样简单。实际上,对于没有图像的数据,你有三种选择。
- LMDB(闪电内存映射数据库)
- LevelDB
- HDF5格式
HDF5可能是最容易使用的,因为你只需要采用HDF5格式把数据集存储到文件中。LMDB和LevelDB是数据库,所以你必须按照他们的协议。HDF5格式存储数据集的大小会被内存限制,这就是为什么我抛弃它的原因。LMDB和LevelDB之间的选择是相当随便的——从我掠过的资源来看,LMDB似乎更强大,速度更快,更成熟。然后从GitHub来看,LevelDB的维护似乎更积极,也具有较大的Google和StackOverflow的足迹。
Blobs和Datums
Caffe内部使用一个叫做Blobs的数据结构进行工作,它用于正向传递数据和反向渐变。这是一个四维数组,其四个维度被称为:
- N或batch_size
- 通道
- 高度
- 宽度
这与我们有关,因为在把它存储到LMDB之前我们必须按照结构塑造我们的案例——从它被送到Caffe的地方。图像的形状是直观的,一批次64个按规定的100×200 RGB像素的图像将最终作为形阵列(64,3,200,100)。对于一批64个特征矢量,每个长度93的Blob的形状为(64,93,1,1)。
在将数据加载到LMDB时,你可以看到个别案例或特征向量存储在Datum的对象上。整型数据被存储在(字节串格式)data中,浮点型数据存储在float_data中。一开始我犯错将浮点型数据分配到data中,从而导致该模型不学习任何东西。在将Datum存储到LMDB之前,你需要将对象序列化成一个字节的字符串表示。
总结
对我来说,掌握Caffe是一个令人惊讶的非线性体验。也就是说,要深刻理解这个系统,还没有任何的切入点和持续的学习路径。让Caffe对你发挥作用的有效信息,分布在很多不同的 教程 , GitHub上的源代码 , IPython Notebook 以及 论坛主题 。这就是为什么我花时间撰写本教程及相关的代码。在我将学到的知识总结形成文本之后,我自己都要从头读一下。
我认为Caffe有一个光明的未来——只要添加新的功能,它将不仅仅是水平的增长,而且会垂直的重构和改善所有用户的体验。这绝对是高性能深度学习的好工具。如果你想要做图像处理和卷积神经网络,我建议你看看NVIDIA DIGITS,它会为你提供一个舒适的GUI来实现目标。
原文链接: Neural Nets with Caffe Utilizing the GPU (翻译/王玮 责编/周建丁)
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

