单节点伪分布式Hadoop配置
本文所用软件版本:
VMware-workstation-full-11.1.0
jdk-6u45-linux-i586.bin
ubuntukylin-14.04-desktop-i386.iso
第一步:安装JDK
详见本博客 http://www.cnblogs.com/yangxiao99/p/4519385.html
第二步:安装Hadoop
首先加入下载的Hadoop安装包在/usr/local/hadoop文件夹下面。然后在命令行下进入/usr/local/hadoop文件,类似于上面的。然后输入解压命令如下
sudo tar -zxvf hadoop-1.2.1.tar.gz
为了以后操作/usr/local/hadoop文件夹里面的文件方便,我们设置一下文件夹的权限,在命令行输入如下
sudo chown -hR ubuntu /usr/hadoop
注意:在上面的命令中,ubuntu是我自己此时登陆的用户名,因此你需要将那个改成你自己的用户名。
第三步:配置Hadoop环境变量

第四步:设置SSH(安全外壳协议)
推荐安装OpenSSH,Hadoop需要通过SSH来启动Slave列表中各台主机的守护进程,因此SSH是必需安装的。虽然我们现在搭建的是一个伪分布式的平台,但是Hadoop没有区分开集群式和伪分布式,对于伪分布式,Hadoop会采用与集群相同的处理方式,即按次序启动文件conf/slaves中记载的主机进程,只不过在伪分布式中Salve为localhost而已,所以对于伪分布式,SSH是必须的。
配置过程(首先确保连接上网络):
① 安装SSH,在命令行输入如下
sudo apt-get install openssh-server
② 配置可以免密码登陆本机
在命令行输入(注意其中的ssh前面还有一个“.”不要遗漏)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
(解释一下上面这条命令,ssh-keygen 代表生成密钥;-t 表示指定生成的密钥类型;dsa 是dsa密钥认证的意思;-P 用于提供密语(接着后面是两个单引号,不要打错);-f 表示指定生成密钥文件)
这条命令完成后,会在当前文件夹下面的.ssh文件夹下创建id_dsa和id_dsa.pub两个文件,这是SSH的一对私钥和公钥,把id_dsa.pub(公钥)追加到授权的key中去,输入如下命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
至此,免密码登陆本机已经配置完毕。
说明:一般来说,安装SSH时会自动在当前用户下创建.ssh这个隐藏文件夹,一般不会直接看到,除非安装好了以后,在命令行使用命令ls才会看到。
③ 输入ssh localhost,显示登陆成功信息。
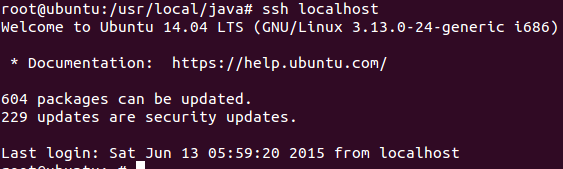
第五步:配置Hadoop伪分布式模式
现在进入到安装Hadoop的文件夹,找到里面的conf文件夹,点击进去。
-
配置hadoop环境文件hadoop-env.sh
打开文件,找到某行有”# export JAVA_HOME = ...” 字样的地方,去掉“#”,然后在等号后面填写你自己的JDK路径,如下所示

-
配置Hadoop的核心文件core-site.xml
打开文件,会发现标签<configuration></configuration>中是空的,在空的地方添加如下配置
Xml代码 
-
1 <property> 2 3 <name>fs.default.name</name> 4 5 <value>hdfs://localhost:9000</value> 6 7 </property> 8 9 10 11 <property> 12 13 <name>dfs.replication</name> 14 15 <value>1</value> 16 17 </property> 18 19 20 21 <property> 22 23 <name>hadoop.tmp.dir</name> 24 25 <value>/home/ubuntu/tmp</value> 26 27 </property>
(注意:在最后一个value值中,上面是ubuntu,是因为那是我的用户名,所以你需要将那个修改为你自己的用户名)
-
配置Hadoop中MapReduce的配置文件mapred-site.xml
打开文件,会发现标签<configuration></configuration>中是空的,在空的地方添加如下配置
Xml代码
-
1 <property> 2 3 <name>mapred.job.tracker</name> 4 5 <value>localhost:9001</value> 6 7 </property>
配置Hadoop中hdfs-site.xml的配置文件
同样的在标签<configuration></configuration>中加入一下代码
1 <property> 2 <name>dfs.name.dir</name> 3 <value>/usr/local/hadoop/hadoop-1.2.1/datalog1,/usr/local/hadoop/hadoop-1.2.1/datalog2</value> 4 </property> 5 <property> 6 <name>dfs.data.dir</name> 7 <value>/usr/local/hadoop/hadoop-1.2.1/data1,/usr/local/hadoop/hadoop-1.2.1/data2</value> 8 </property> 9 <property> 10 <name>dfs.replication</name> 11 <value>2</value> 12 </property>
以上配置用的命令是:sudo gedit ******
第六步:格式化Hadoop文件系统HDFS并启动Hadoop
首次运行hadoop必须进行格式化Hadoop文件系统,以后运行即可跳过。打开命令行,进入安装了Hadoop的文件路径下,然后在命令行输入
bin/hadoop namenode -format
格式化文件系统,然后启动Hadoop,在命令行里面输入
bin/start-all.sh

验证是否正常启动,在命令行里面输入jps,然后回车,如果在命令行里面出现如下类似画面(因为前面的数字可以不同)
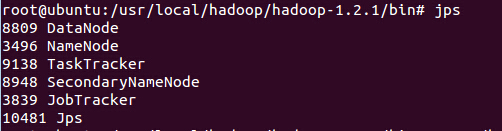
则说明已经正常启动。如果以后需要关闭Hadoop的话,在Hadoop安装的文件夹路径下面在命令行输入
bin/stop-all.sh
来关闭Hadoop。
第七步:跑一个Hadoop中自带的WordCount程序,来体验一把
1、在主目录下创建两个文本文件
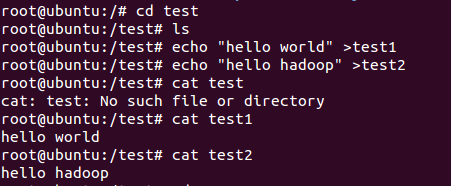
2、启动Hadoop
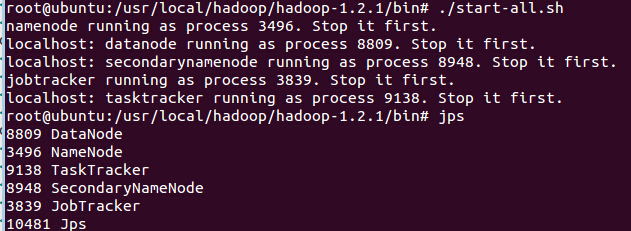
3、把新建的文件夹放到hdfs上

4、跑wordcount程序
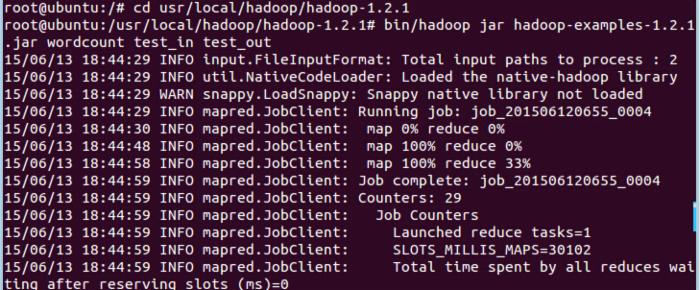
跑完之后可以查看一下
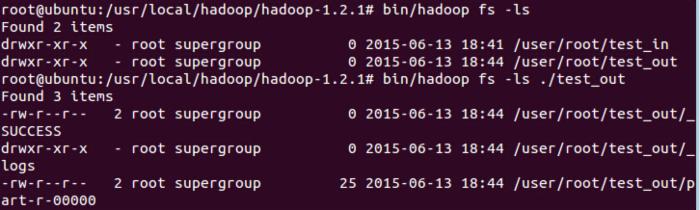
5、最终的结果就在part-r-00000中!

以上是亲手所写,欢迎各位来探讨交流:QQ:747861092
QQ群:163354117 (群名称:CodeForFuture)
附三个链接:(页面显示:hadoop状态)
http://localhost:50030/jobtracker.jsp
http://localhost:50070/dfshealth.jsp
http://localhost:50060/tasktracker.jsp

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

