外部排序,杀鸡焉用牛刀?
上篇: http://www.cnblogs.com/foreach-break/p/external_sort.html
- 字符集和编码
- 字节序
- I/O方式
- 内存
- 磁盘
- 线程/同步/异步
- 数据特点
字符集和编码
为什么要考虑文件的编码?
当你将文件从阿拉伯传到中国,告诉你的中国朋友要进行一个外部排序,你的中国朋友也许会傻:

上面是什么? 乱码 .
你也可以这样体验乱码:
echo "数" > t.txt iconv -f UTF-8 -t UNICODE t.txt ��pe好了,你知道了如果不知道文件的编码,你可能会解析到乱码.
字符集是什么?
charset - > char-set,字符的集合.比如 UNICODE、ASCII
编码是什么?
encoding,字符的表示.比如 UTF-8、ASCII
字符集和编码的关系
你晕了,我也晕了,ASCII码怎么既是字符集又是编码?
历史上,字符集和编码是同义词,实际却又不尽相同,没有一个规范地定义,那怎么理解呢?
字符集,往往强调其所“支持”的字符范围,集外的字符它不支持.集合就有一个边界,边界内的我给个表示,边界外的我不知道怎么表示。
编码,往往强调针对某个字符集的字符,我这么去转换表达为机器可理解的方式-二进制,如果对某个字符集的字符,我的转换方式和其一致,那么我既是编码也是字符集,否则我就只是一种字符集的转换格式。
那么,UNICODE是字符集,它所支持的字符,在它内部,也有个表示,这种表示是不是一种编码?毫无疑问,是一种编码。
UTF-8是一种编码,是对UNICODE的一个变长实现,这种编码和UNICODE编码是什么关系?转换关系。
所以看编码还是字符集,往往要看“语境”。
举个简单的例子:
汉字:“数”
| 编码/字符集 | 进制 | 值 |
|---|---|---|
| UNICODE | 16 | 6570 |
| UNICODE | 2 | 110010101110000 |
| UTF-8 | 16 | E6 95 B0 |
| UTF-8 | 2 | 111001101001010110110000 |
这个例子,你可以这样体验:
/// 看utf-8 echo "数" > t.txt hexdump -xv -C t.txt 0000000 95e6 0ab0 00000000 e6 95 b0 0a |....| 00000004 /// 看unicode iconv -f utf-8 -t unicode t.txt | hexdump -xv -C 0000000 feff 6570 000a 00000000 ff fe 70 65 0a 00 |..pe..| 00000006 字节序
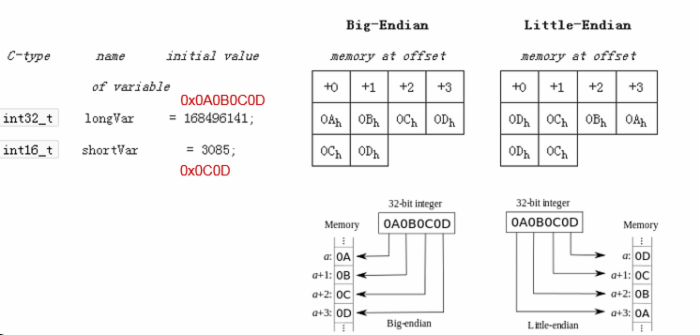
如果你注意到汉字“数”经过UTF-8编码后的16进制是 E6 95 B0 ,再给它后面加个换行是 E6 95 B0 0A ,你用下面的方法会看到:
hexdump -xv -C t.txt 0000000 95e6 0ab0 00000000 e6 95 b0 0a |....| 00000004 按双字节(16位)的方式解析,你得到是 95 E6 0A B0 ,你一定很费解,然并卵,这种费解的根源就是字节序造成的。
字节序就是字节的顺序,如果按照双字节(16位)的方式解析 E6 95 B0 0A ,那么读16位,得到 E6 95 ,字节序反一下,得到 95 E6 ,再读16位,得到 B0 0A ,字节序反一下,得到 0A B0 ,合起来就是 95 E6 0A B0 。
这种“反字节序”就叫 Little-Endian ,小端或者小尾。
大端(Big-Endian | BE)
 注:图片来自wiki
注:图片来自wiki
从上图可以看出,一个数的最高字节被放在内存的低地址处:
0A -> a + 0 ,这种方式就是大端( Big-Endian ),数的最高字节叫作 Most Significant Byte ,这个你可以称作最高有效字节或者最重要的字节,为什么最重要呢?
对于1个数来讲,它的最高字节能反映这个数的符号(正负),也比低位字节更能代表这个数的大小。
大端存储的特点也决定了它的优点,就是近似估计一个数的大小和符号,只需要取最高字节即可。
小端(Little-Endian | LE)
反之,如果一个数的最低字节被放在内存的低地址处:
0D -> a + 0 ,这种方式就是小端( Little-Endian ),数的最低字节叫作 Least Significant Byte ,可以称作最低有效字节或者最不重要的字节。
32位/64位地址下:
| 10进制 | 16进制 | 位数(bits)/字节数(bytes) | BE | LE |
|---|---|---|---|---|
| 168496141 | 0A 0B 0C 0D | 32/4 | 0A 0B 0C 0D | 0D 0C 0B 0A |
| 3085 | 0C 0D | 16/2 | 0C 0D | 0D 0C |
很显然,大端存储符合我们人类从左往右书写或阅读的习惯,为什么又要出一个如此麻烦的小端存储呢?
小端存储,取数的时候可以这样:
a + 0 -> 第一个字节
a + 1 -> 第二个字节
a + 2 -> 第三个字节
a + 3 -> 第四个字节
一个基址a,+不同的偏移即可完成不同精度的取数操作,high么?
如何区分大端还是小端?
如果你注意到:
/// 看unicode iconv -f utf-8 -t unicode t.txt | hexdump -xv -C 0000000 feff 6570 000a 00000000 ff fe 70 65 0a 00 |..pe..| 00000006 那么前2个字节 feff 就表示了小端存储,很简单, fe < ff ,这2个字节叫作 Byte Order Mark ,称字节序标记,不仅可以用作区分文件是大端/小端存储,还可以表示编码。
至于编程的方式区分大端小端,这个如果你谨记 字节序 的含义相信不难写出代码:
/// java获取字节序BE/LE Field us = Unsafe.class.getDeclaredField("theUnsafe"); us.setAccessible(true); Unsafe unsafe = (Unsafe)us.get(null); long a = unsafe.allocateMemory(8); ByteOrder byteOrder = null; try { unsafe.putLong(a, 0x0102030405060708L); byte b = unsafe.getByte(a); switch (b) { case 0x01: byteOrder = ByteOrder.BIG_ENDIAN; break; case 0x08: byteOrder = ByteOrder.LITTLE_ENDIAN; break; default: assert false; byteOrder = null; } } finally { unsafe.freeMemory(a); } System.out.println(byteOrder.toString()); 用C/C++就更简单了,一个 union 就搞定了.
字节序影响了什么?
字符集和编码如果搞错,会导致乱码,字节序搞错,会导致错码,很显然 0C0D 和 0D0C 不是同一个数,不是么?
I/O方式
既然是对文件进行排序,文件I/O是必不可少的,那么针对java的若干经典I/O方式,有没有值得探讨的地方呢?
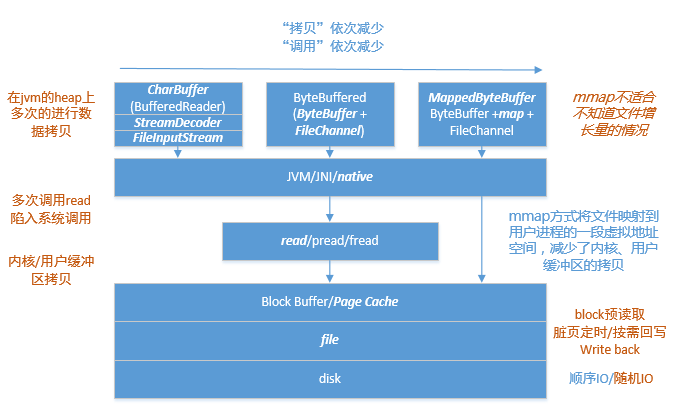
利用字符缓冲在流中读写文件
经典代表就是 BufferedReader/Writer ,粗略的讲,这种方式仅适合字符文件(虽然文件的本质都是0101)。
从BufferedReader读一行数据,如果其字符缓冲内木有或者不够,那么就得
BufferedReader -> StreamDecoder -> FileInputStream -> JNI/native -> read/c -> system call/kernal ...
而且,在read/c这个层面还一次只读一个字节,虽然操作系统会尽力在block-buffer/page-cache做足功夫,通过预读更多的物理块来减少磁盘I/O,但是“系统调用”和内核/用户缓冲区的数据拷贝,以及jvm的堆内堆外内存拷贝、jvm的堆内的byte[]、ByteBuffer、CharBuffer、char[]间的数据拷贝,多的乱了眼。
决定了这种方式,不会那么的高效,尽管做了字符缓冲,也只是有限地减少了调用和拷贝次数。
利用字节缓冲在FileChannel中读写文件
以读取数据为例,这种方式,比起字符缓冲+流的方式,因为面向字节,所以减少了解码的步骤,也不会一次一个字节的搞,在read/c的层面,它“批量”的读取数据,所以这种方式更加灵活也更加高效。
不足的是,因为面向字节,所以如果你解析的是个字符文件,那么你需要自己实现解码的步骤。
同时,因为利用文件通道 FileChannel 去操作文件,所以会开辟或者从本地直接内存池( DirectBytebuffer )中开辟直接内存( DirectByteBuffer ),而这种内存是一种堆外内存,所以将数据从堆外内存拷贝到堆内,这个过程不可避免。
利用字节缓冲 + mmap读写文件
mmap是什么?
memory-map -> 内存映射。
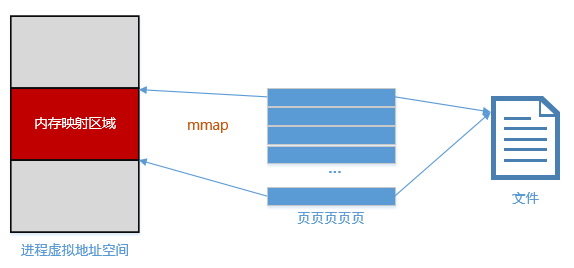
简单的说,mmap打通了用户进程的虚拟内存地址和文件的访问通道,你可以认为文件的一部分被映射进了你的进程能访问到的一段内存中,这样,你就可以像操作内存那样操作文件,high么。
这种方式对比前一种文件I/O的方式,避免了显式地read/c,也就避免了用户/内核缓冲区的数据拷贝,所以,一般而言,这种I/O方式是高效的典范。
既然有一般而言,就有特殊,对于定长文件支持地很好,对于不定长的有增长的文件,它很无力,看下面的方法签名:
java.nio.channels.FileChannel public abstract java.nio.MappedByteBuffer map(FileChannel.MapMode mode, long position, long size) throws java.io.IOException 注意到 position 和 size ,再注意到:
if (size > Integer.MAX_VALUE) throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE"); 你就知道这种方式,一次映射的不能超过2G大小,如果定长文件超过2G,你需要多次进行 map 调用。
如果文件不定长滴增长,那就没法获知准确的 size ,那这种方式再高效,然并卵。
同时 mmap 方式很吃内存,如果你映射了一个文件的一部分,又进行了大量的随机写,那么许多脏页就会造成,操作系统会定期/按需地处理这些脏页,采用 write-back 方式将修改后的页写入磁盘。
可以想象,因为页是随机的,那么这种持久化的方式会引发大量的磁盘随机I/O,这种情况,你懂的。
所以,当文件越大,被映射的 size 越大,随机I/O的概率可能就越大,那么 write-back 的阻塞和锁时间就会很长,你卡住了,脏页越来越多,卡的越来越严重,磁盘的磁头会很纠结, mmap 就没那么高效了,甚至会慢的让你费解。
内存
你应该知道使用你的内存的,不仅仅是你代码中的 new ,还包括你使用快排、归并排序的调用栈,递归算法的调用层次越深,栈就越深,开栈消栈的开销就会越大,所以你应该在数据集合很小的时候,进行 cutoff to insertion-sort ,不要认为插入排序木有用,它处理基本有序的数据和小量数据,非常高效,同时可以显著地减少你递归调用的深度和开销。
如果你使用了归并排序,注意提前分配辅助数组的空间,而不是在递归调用中分配、销毁,也应该注意到利用辅助数组和原始数组互为拷贝来减少两者之间的数据拷贝,这样,你的归并排序算法会高效的多。
同时,你应该意识到这些堆栈信息很可能会被交换到swap空间,意味着你没有预料的磁盘I/O会狠狠地拖垮你的性能。
关于内存碎片,和降低小对象、小数组的频繁生灭,使用池的技术,能改善性能,降低碎片。
还有, int 和 Integer 占用的内存空间大小是迥异的,当然如果你使用了泛型,这一点你可以忽略。
磁盘
关于磁盘没什么太多要讨论的,这里主要是机械磁盘,应该知道顺序I/O是机械磁盘的最爱,同时要注意到使用缓冲、缓存(预读)和批处理的思想来操作数据,这样可以降低磁盘I/O所占的时间比例。
线程/同步/异步
在上篇我们无脑而愉快地使用了单线程+同步的方式来处理外部排序问题,现在我们可以简单讨论下有没有更好的方式。
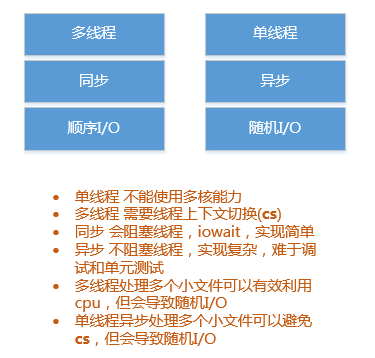
关于同步/异步、阻塞/非阻塞,这里再简单提一下:
同步/异步,关注多个对象或者线程的执行顺序,是一种逻辑次序的约定关系。
阻塞/非阻塞,关注某个对象或者线程的执行状态,一个线程进入阻塞状态,它所被分配的cpu时间就被没收了。
回到我们的外部排序问题上来,针对单个大文件 bigdata(4663M,5亿行) ,因为是字符文件,很难利用多线程同时读取文件的不同部分,因为你无法确知某行数据的换行符的偏移量在第几个字节,所以读取采用单线程,而且能充分利用顺序I/O(如果文件本身的物理块大量连续的话)。
因为按行读取并搜集一定数目的数据进入内存缓冲区 memBuffer ,并且进行了排序,所以在读取时,会遇到阻塞的情况, iowait 不可避免,这个时候,没有其它线程在处理排序,这是对 cpu 的极大浪费,而且按行读取往往不能充分让磁盘转起来,也浪费了I/O能力。
那么在排序的时候,因为是单线程,所以无法进行I/O,这就是纠结所在。
如果文件不是很大,这种方式简单快捷省脑子,如果文件极大,这种方式恐怕就过于简单粗暴了。
考虑要充分利用 cpu (多核的话),并充分让磁盘转起来,达到I/O的最大化,我们可以在这一步省去排序操作,尽快的将大文件分割为多个 无序 小文件。
到这里,我们有两种选择:
1. 单线程、异步、非阻塞I/O
因为是非阻塞I/O,所以线程除了被操作系统调度放弃cpu外,不会因为I/O而放弃cpu时间, 这个时间可以用来处理排序,当I/O就绪,异步回调会将数据奉送到线程的堆栈当中(memBuffer), 你就可以将这批新鲜热乎的数据挂入待排序的队列,然后接着处理排序。 这种方式,将线程的上下文切换时间降至最低,是cpu利用+的方式,但是无法利用多核cpu的优势。 同时,实现显然比较复杂。2. 多线程、同步、阻塞I/O
很简单,将无序小文件平均分配给多个线程,多个线程是多少呢? 根据你的要求,如果在意吞吐量,那么就无法避免多个线程的上下文切换,开更多的线程处理吧,性能不会那么高。 如果在意性能,一般取2、4、8、16,最多不要超过cpu物理核心的2倍。 当然,并发度的高低,都得看测试的结果,上面只是经验数值。 这种方式,建立在如下这个基础之上: let t1 = 大文件I/O而闲置的cpu时间(不能排序) + memBuffer排序浪费的I/O时间(不能I/O) let t2 = 多线程上下文切换时间 + 因多个文件同时I/O造成的随机I/O时间 如果 t2 < t1 ,那么这种方式可选。 事实上,根据实测,文件越大,这种方式的优势越明显,你可以试试。文件数据特点
说了这么多,最关键的还是文件本身的数据特点。
如果是字符文件,采用 UTF-8 编码,一个整型 99999999 当作字符串写进文件,需要8个字节来表示;
而如果面向字节,大端,4个字节就够了:
static private int makeInt(byte b3, byte b2, byte b1, byte b0) { return (((b3 ) << 24) | ((b2 & 0xff) << 16) | ((b1 & 0xff) << 8) | ((b0 & 0xff) )); } 放在上一篇的问题中说,5亿条整形数据,采用 UTF-8 编码的字符方式,每行还以 /n 结束,总数据量在约4663M;
而采用定长4字节的方式来编码,总数据量约1908M;
直接打了4.1折,亲。
数据越小,I/O越少,时间蹭蹭地降:
| 文件 | 起始/最终 数据格式 | 数据量 | 起始/最终 文件大小(M) | 排序方案 | 时间(s) |
|---|---|---|---|---|---|
| bigdata | 字符/字符 | 5亿 | 4663/4663 | 分为若干有序小文件,然后多路归并排序 | 772 |
| bigdata | 字符/字节 | 5亿 | 4663/1908 | 1.分为若干无序小文件; 2.四线程同步、阻塞I/O进行并发排序得到若干有序小文件; 3.多路归并排序. | 430 |
| bigdata | 字符/字符 | 5亿 | 4663/4663 | 位图法 | 191 |
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

