一种基于“哨兵”的分布式缓存设计
14年双11大促缓存方案,今天有点闲暇时间,回顾一下当时的思路。
场景介绍:
大促活动下,对于某些产品进行整点秒杀活动。预计流量是平时峰值 5+倍 。
商品计算逻辑比较复杂:某个最终展示的商品属性和价格,可能需要上亿次动态条件计算获得,动态条件每时每刻都在变化,并且商品的库存属性属于行业共有库存,每时每刻都在变化。
计算模型:前端机并发去后端获取实时计算数据,然后合并结果, 根据用户信息 给商品打属性,排序。
头脑风暴
针对这种场景,有很多方案可以尝试,不过总结起来,大概俩个方向: 扩容 和 缓存 。
扩容
扩容是最容易想到的方式,而且每年大促,根据压测和运营活动预期,都可能有相应扩容。扩容从某种程度上说,也是最简单的方式,如果应用规划足够好,没有状态,那么基本不用开发介入就能完成。
但是如果应用涉及状态信息,那么扩容就没有说的那么轻巧,扩容涉及到增加集群状态;活动结束后,机器下线涉及集群减少状态,这一增一减,增加了运维的成本和系统稳定性。
扩容还有一个不好的地方就是活动结束后,系统水位下降,闲下来4倍的机器,比较浪费。
缓存
相对扩容,缓存是一种从应用角度出发,优化系统的方案。缓存的方案可细分不同粒度,分别适用不同场景。
静态化
静态化能最大限度降低最大限度降低后端压力,一般静态内容可以定时或者通过数据更像触发生成,然后推送到CDN节点。静态化适用于1) 读多写少的数据 ,或者2) 能够容忍数据变化延迟 的场景。对于本文介绍的场景,并不适合,原因在于商品不满足前面说的两点,并且每个登陆用户看到的产品价格和属性是不同的。
缓存中间结果
静态化这种”一刀切”模式,不能满足针对每个用户的个性化展示需求,如果把每个用户看到的数据都静态化,那缓存的命中率有会很低,基本每个用户请求一两次就不会再来了。而且缓存数据量巨大。
由此想到把缓存粒度缩小,把缓存从展示层后推到 前端机 上。因为前端机负责汇总后端结算结果,并根据用户信息给商品打属性,排序。
缓存方案尝试
经过头脑风暴,最终确定采用 缓存中间结果 方式。接下来讨论一下方案细节。
简单粗暴方式
如果缓存有数据,取缓存数据,如果没有,请求后端并把结果更新到缓存。 这是一种最简单的缓存模式,但不幸的是不适合秒杀场景,因为秒杀开始的时候,缓存很能没有数据,请求会 穿透 到后端。
实时缓存,异步更新方式
实时请求数据来自缓存,缓存数据定时异步更新。 粗看起来,这个方案不存在 缓存穿透 的情况,因为数据不会实时从后端计算获取,而是从缓存获取,如果缓存数据存在,直接获取即可。缓存更新可以把用户请求汇总后去重,定时更新。
上面讨论的两种方式都一个共性问题: 第一批请求 问题: 如果第一批请求缓存没有数据怎么办?
简单粗暴 的方式会让这样的请求 穿透缓存 ,后端去处理并更新缓存。这样会给后端计算带来压力,秒杀开始那一刹那,很可能支撑不住。
而 实时缓存 的牺牲了这样的请求,因为这些请求根本看不到数据,所以请求失败。这两种方式在本文的应用场景都不合适。
为何不提前初始化缓存?
的确,上面两个方案如果能在 第一批请求 到达前初始化好缓存,那基本上可以满足本文的应用场景的。而且看起来也很容易做到,提前 模拟一次请求 或者 提前往缓存放一份数据 不就可以了吗?
不幸的是,本文场景因为涉及数据范围巨大,不能在较短时间内遍历缓存key,初始化好缓存,即使采取并发方式。而且,初始化缓存请求过多,也将给后端机器造成压力。
缓存失效又该怎么办?
根据需求,两种方案的缓存 不会永久有效 ,如果缓存失败了怎么办?
对于 简单粗暴 方式,如果缓存失效,又会遇到 第一批请求 问题,一批请求发现缓存失效,怎么办?看来即使解决了缓存初始化问题,还有可能导致缓存穿透。
实时缓存 模式也有类似问题,如果异步更新前数据已经失效了,那么将牺牲一批数据失效后到更新前这批用户。因为没有人去更新数据。
缓存更新问题
不管哪种方式,分布式缓存更新都存在并发问题,尤其在整点秒杀场景更为突出。对于 简单粗暴 方式,可以采用分布式锁解决:如果缓存穿透的一批请求只有一个会真正打到后端是不是就可以解决了?
实时缓存 也有同样的问题,只不过异步请求可以把一段时间内的重复请求合并成一个,从侧面避免了并发问题。
更好的缓存方式
把上面的讨论结合,可以得到一种更优雅的缓存方案,既不牺牲第一批请求,也不存在缓存穿透问题,同时避免并发更新问题。
哨兵
想象有这样一个哨兵线程,只有它能去后端请求实时数据,并更新缓存。
第一批请求场景:
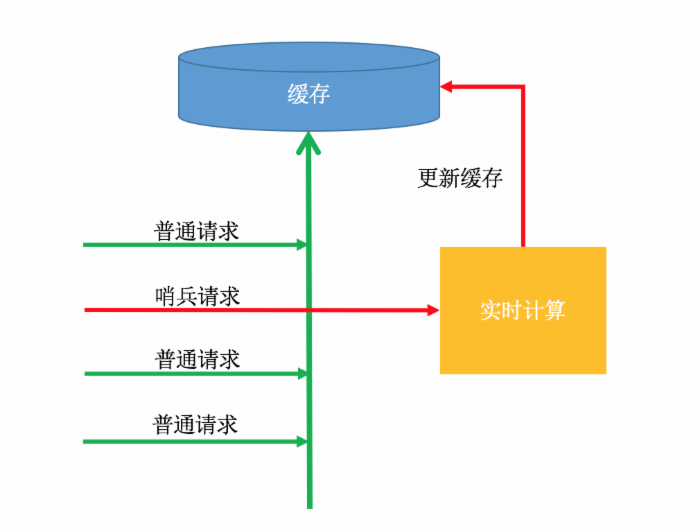
第一批请求中,选取最早的那个请求为哨兵,这个线程不会去读缓存,直接去后端获取计算结果并更新缓存。其他普通线程则自旋+sleep等待,直到哨兵更新缓存后,能拿到数据为止。
缓存失效场景:

哨兵的作用是让缓存永不失效。哨兵线程 提前苏醒 ,去后端获取计算数据并更新缓存。这样,其他普通线程根本不会感知到缓存已经失效,他们能一直拿到最新的缓存。
例如,某个key的缓存失效时间的 12:00:00 ,那么哨兵可能在 11:59:55 的时候苏醒,请求后端并于 11:59:57 的时候完成缓存数据更新,后续请求线程感知不到数据的更新,一直能取到非过期的数据。
实现细节
哨兵:其实哨兵也是一个普通请求。可以用原子计数器(redis或tair)实现,一个数据有两个key:原子计数器key和数据缓存key,二者缓存时间一致,但是计数器key失效时间比数据key的要早( 至少提前一个后端请求RT时间 ,这样能保证哨兵更新缓存后,不被其他线程感知到)。当请求线程发现缓存没有数据的时候,每个线程去更新计数器,更新后,得到计数器为1的线程,被设置成哨兵线程,其他线程则等待哨兵。
普通请求没有获取到数据的时候,自旋+sleep应该有个超时时间,防止意外情况。如果超时了,根据业务场景选择请求后端数据还是处理失败。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

