Otto产品分类挑战赛亚军:不要低估最近邻算法
【编者按】 竞赛刷分从来不是机器学习的目的,但参加竞赛可以让从业者学会快速入门。Kaggle的这篇博文,通过对奥托集团产品分类挑战赛亚军Alexander Guschin的访谈,介绍了一种有效的核心技术方法,并解释了为什么不应该低估最近邻算法的威力。Alexander的解决方案中最主要的思想是进行堆叠,将不同方法得到的预测值Y进行结合作为“元特征”。他发现KNN能够实现非常好的元特征,尝试更多的元特征可能比改善模型更有效。他使用的工具只有sklearn、xgboost和lasagne。
奥托集团产品分类挑战赛( Otto Group Product Classification Challenge) 曾经是 Kaggle历史上最受欢迎的竞赛。Alexander Guschin从其他3845名数据科学家行列中脱颖而出,获得了该挑战赛的亚军。在本篇博文中,Alexander将分享他的核心技术方法,并且解释为什么不应该低估最近邻算法的威力。

3848位参赛选手共 3514支队伍竞相对Otto集团产品线上的物品进行分类
基本信息
1. 在参加本次挑战赛之前你是什么背景?
对机器学习我有一定的理论了解,这主要多亏了我所在的基地研究所(莫斯科物理技术学院)以及我们的教授 Konstantin Vorontsov,他是俄国顶尖的机器学习专家之一。至于我对一些实际问题的熟稔,另一位很了不起的俄国数据科学家Alexander D’yakonov(曾经是Kaggle第一名),过去常常在每一年的秋季都会有实用机器学习课程,这个课程给了我很好的基础,Kagglers可能会知道这门课叫PZAD。
2. 你是怎样开始你的 Kaggle竞赛之旅的?
我是从 2014年秋季在Forest Cover Type Prediction开始参加比赛的,当时我对解决机器学习方面的问题并没有什么经验,后来我在“Titanic: Machine Learning from Disaster”上发现了很好的基准,它给予了我很大的帮助。从那以后,我意识到自己对机器学习非常感兴趣,并且我会尽我所能去参加每一场比赛。
3. 是什么因素使得你决定参加这次比赛?
当时我是想验证我学士毕业论文里的一些想法,并且我知道 Otto的竞赛有非常靠谱的数据集。你可以通过交叉验证的方式去检查每一件事,并且简历上的变化是足够接近排行榜的,此外,比赛的精神是非常适合于检查思路的。
开启技术之旅
1. 你对数据做了什么样的预处理,使用了什么样的有监督学习方法?
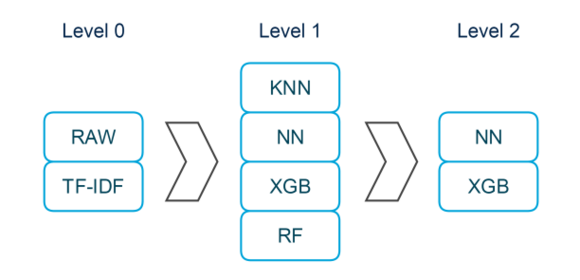
我的解决方案中的堆叠架构
我的解决方案中最主要的思想是进行堆叠(stacking) 。堆叠能够帮助你将不同方法得到的预测值 Y(在多类问题中称之为标签)进行结合作为“元特征”。一般而言,为了获得用于训练的元特征,你需要将你的数据划分成K折,对于每(k-1)组,在(k-1)部分上训练K个模型,并用剩下的部分进行预测。为了获得测试所用的元特征,你可以用这些K个模型所做的预测进行平均,或者在基于所有训练数据的基础上做单一的预测。然后,你可以在特征和元特征上训练元分类器,并且如果你有一些元分类器的话就可以做预测平均。
在参加这个比赛的初始阶段, 我发觉把数据换划分成两组是比较有用的:( 1)训练集和测试集,(2)有词频-逆文档词频的训练集和有词频-逆文档词频的测试集。 我的解决方案中的很多部分都采用并行的方式使用了这两组数据划分。
就有监督方法而言,我发觉 Xgboost和神经网络都能够在数据上给出很好的结果 ,所以我决定在我的 ensemble使用它们作为元分类器。
虽说 KNN通常会给出不同于决策树或神经网络的预测结果,但是我还是将这些预测结果包含到了第一层中作为元特征,碰巧地是,随机森林和xgboost作为元特征也很有用。
2. 在观察数据时你最重要的发现是什么?
最主要的发现可能是 KNN能够实现非常好的元特征 ,绝不要低估最近邻算法。
在第二层将 NN和XGB预测的结果结合起来是非常重要的,在我最后一次在第二层将NN和XGB分开后在私有的LB上得到的分数大概在0.391,而将它们结合在一起后得到的分数是0.386,可以看到结果获得了很大的提升,所以在第二层进行打包会非常的有用。

在 2维平面上TSNE
此外, TSNE在2维平面上看起来非常的有趣,从图中我们可以看到一些样本经过我们的算法后被误分了,这意味着要找到一种对我们预测的结果进行后处理的方法来提高logloss是非常不容易的。
同样也让人感兴趣的是,对于一些邻近其他类的类别,比如类别 1和类别2,将这些类别进行专门地区别是非常值得尝试的。

holdout最终预测模型
3. 对于其中的某一发现你有没有很吃惊?
不幸地是,如果你想让你的元特征更好,你不一定非得去改善你的模型, 并且当提及到 ensembling的时候,所有你能够指望的是你对算法的理解(基本上是你的元特征越丰富多样,分类精度就越好),并尽可能去尝试更多的元特征。

元特征越丰富多样,分类精度就越好。通过 Extratrees得到的元特征vs通过神经网络得到的元特征
4. 你使用了哪些工具?
我仅仅使用 sklearn、xgboost和lasagne。这些都是很好的机器学习库,并且我会向刚开始参加Kaggle比赛的人推荐这些工具。根据的经验,这些工具足够你去尝试不同的方法,并且在很多Kaggle比赛中都取得了很好的结果。
智慧之言
对于那些刚开始进入数据科学的人你有什么建议?
我认为最有用的建议是 不要将自己困在试着细调参数或是对于每一项竞赛都使用相同的方法的笼子里 。你应该通过论坛不断的进行阅读,并理解过去那些竞赛中的解决方法,所有这些将会让你获得极大的提高,不论你是什么样的级别水平。 换句话说,阅读过去的那些解决方法和解决竞赛中的问题一样的重要 。
同样,当你第一次开始解决机器学习方面的问题时,你可能会犯一些低级的错误,这些错误会耗掉你很多的时间和精力,所以如果你能和其他人组队的话是非常有帮助的,你可以请他帮你检查你写的代码或者让他尝试相同的方法。此外,在论坛里要一直将你自己方法的性能和别人的进行对比。 当你发现你的算法比论坛里别人报告的要差很多时,去检查基准和其他近段时间的一些比赛,并试着将改错误指出来。
个人简历: Alexander Guschin是莫斯科物理技术学院四年级学生,目前 Alexander正在完成他关于ensembling方法的本科论文工作。

Alexander在Kaggle上的个人资料
原文链接 : Otto Product Classification Winner's Interview: 2nd place, Alexander Guschin (翻译/袁勇 责编/周建丁)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

