解析哈希表
网上看了很多有关的文章,感觉讲得都不够明了(原谅没读过书的我,这些基础知识都是看博客自学的)。所以今天决定来讲讲哈希表
哈希表又称散列表,C#里最经典的就是Hashtable和Dictionary。特别是后面的Dictionary,大家都用得非常多。他们是以键值对的形式存储的,通过key就可以查到value,而且查询速度非常快。它内部是如何实现的呢?查询快又是为什么呢?它又有什么缺点吗?下面就来一一说明
首先,我们要开辟一个容器(数组)来存储要插入的元素,既然知道字典是以键值对的形式来存储,那我们的容器应该是这样的
//容器实体 private struct bucket { public object key; public object value; } private bucket[] buckets = null;//容器
比如我现在想插入一个key为3B,value为1,我们就会通过key.GetHashCode()得到一个哈希值(int),然后再将这个值通过计算,转换成数组的索引,然后在索引位置存储这对key和value
下图k代表key,v代表value

有了眉目后,我们可以开始动手构建代码了
class Program { static void Main(string[] args) { MyHashTable table = new MyHashTable(); table.Add("3B", 1); table.Add("WEA", 2); var a = table.Find("3B"); } } public class MyHashTable { private struct bucket { public object key; public object value; } private bucket[] buckets = null;//容器 public MyHashTable() { buckets = new bucket[10]; } public void Add(object key, object value) { uint index = (uint)key.GetHashCode() % (uint)buckets.Length; bucket temp = new bucket() { key = key, value = value }; buckets[index] = temp; } public object Find(object key) { uint index = (uint)key.GetHashCode() % (uint)buckets.Length; var item = buckets[index]; if (item.key != key) throw new Exception("不存在该键"); return item.value; } }
Add的时候我们调用key.GetHashCode()可以得到它的哈希值(int),然后再将其转换为32位正整型,然后%数组的长度。得到索引的位置。 a=b%c,a的范围为0~c-1。所以一定不会越界 。但问题来了。
Q1.如果不同的key通过计算后得到了相同的索引,怎么办?这时我们该如何存储,如何查找?
table.Add("WEA", 2);table.Add("QQ1", 2);
这时他们通过uint index = (uint)key.GetHashCode() % (uint)buckets.Length;计算出来的index都是8, 下文中我们将这种情况称为冲突
Q2.容器大小初始化时为10,如果我插入的元素超过了10个,我要扩充容器。扩充完后容器(数组的长度)会发现变化,这时通过
uint index = (uint)key.GetHashCode() % (uint)buckets.Length
计算出来的结果就会出现不一样,我们该如何解决?
A1.我们先改造容器(数组buckets),数组的每个元素不是一个bucket。而是一个bucket链表(如果不知道链表的可以当它是一个集合)。这样我们就可以将转换后相同索引的多个元素都存在同一个位置。在查询时我们索引到这个bucket链表。然后再一个个找key相同的元素。
A2.我们可以重新做一次排列(相当于调用Add方法)
比如我们初始化时数组长度为10。全部被占用时,我们将数组扩展成20。这时我们就
uint index = (uint)key.GetHashCode() % 20 ;
然后再插入到新的数组中,这时排列就是正确的了。有点重新映射的味道。
附加一点,容器的大小(length,也就是数组的长度)与添加的元素的数量(elementcount)之间有一个关系。如果容器的大小不变,元素数量越多则出现冲突的可能性就越大。
比如我容器大小是2,我现在添加了一个元素到下标0的位置。而我下个元素添加时发生冲突的概率就有50%。如果容器大小是3,则重复的概率只有33.33%。
我们不可能为了避免重复,一开始就将容器弄得很大,就像我们不可能用食堂那种超大的锅子来煮1杯米的饭。
也不可能任由它冲突(反正我们再在链表里一个个查就行了)这样就失去了它查找性能的优势了,就相当于线性查找了。
我们如何把握这中间的平衡呢?
float r=elementcount/length; r最好处于0.6~0.7之间。而微软则是采用0.62(近乎黄金分割点啊)。如果r>0.62,我们就扩展容器。
class Program { public static void Main() { MyHash set = new MyHash(); List<string> list = new List<string>() { "ef","ab","ff","gg","ee","zf","ase","fge","qweg","qalspo","goo2","1qwe","wet93" }; for (int i = 0; i < list.Count; i++) { var item = list[i]; set.Add(item, i); } var value = set.Find("gg"); } } public class MyHash { //容器实体 private struct bucket { public object key; public object value; } private LinkedList<bucket>[] buckets = null;//容器 private int count;//已存元素数量 private int step = 10;//扩展时增加的数量 public MyHash() { IninialBuckets(step); } private void IninialBuckets(int length) { if (buckets == null)//如果为空,则初始化容器 { buckets = new LinkedList<bucket>[length]; return; } //否则,则扩展容器 length = length + buckets.Length; var newBuckets = new LinkedList<bucket>[length]; count = 0; foreach (LinkedList<bucket> linkList in buckets) { if (linkList == null) continue; foreach (bucket item in linkList) { int index = GetIndex(item.key, length); InserintoBuckets(index, item.key, item.value, newBuckets);//重新排列 } } buckets = newBuckets; } private int GetIndex(object key, int length) { return (int)((uint)key.GetHashCode() % (uint)length); } private void InserintoBuckets(int index, object key, object value, LinkedList<bucket>[] buckets) { var linkList = buckets[index]; if (linkList == null) linkList = new LinkedList<bucket>(); if (linkList.Count(x => x.key == key) > 0) throw new Exception("已存在key:" + key); bucket item = new bucket() { key = key, value = value }; linkList.AddLast(item); buckets[index] = linkList; count++; } public void Add(object key, object value) { if ((float)count / (float)buckets.Length > 0.62)//如果大于0.62。我们就扩展我们的容器 { IninialBuckets(step); } int index = GetIndex(key, buckets.Length); InserintoBuckets(index, key, value, buckets); } public object Find(object key) { int index = GetIndex(key, buckets.Length); var linkList = buckets[index]; if (linkList == null) throw new Exception("不存在此键"); bucket item = linkList.FirstOrDefault(x => x.key == key); if (item.key == null) throw new Exception("不存在此键"); return item.value; } }
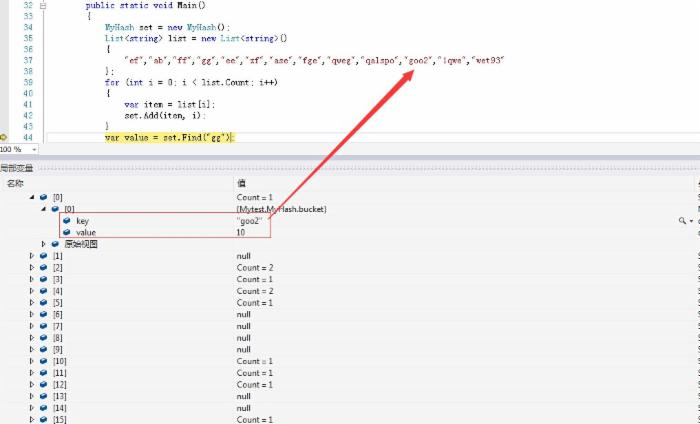
这时我们要根据某个key查value时,我们就将key同过计算转换为索引 (uint)key.GetHashCode() % (uint)length
所以在理想的情况下(不同的key通过hash后计算出来的索引不同,也就是无冲突),查找时的时间复杂度是O(1)。这就是它的优势。如果冲突了,接下来我们的查找就是线性的了。所以可以看出,哈希表这种数据结构最重要的是算法本身。
现在大家也可以看出哈希表的优势了,无论数据量再大,查找都是O(1) (理想情况下)。但它的前提就是牺牲空间。
大致原理就是这样,但我们常用的Hashtable等它们并不是这样构造的,它们解决冲突时使用的是 双重散列法,它探测地址的方法如下:
h(key, i) = h 1 (key) + i * h 2 (key)
其中哈希函数h 1 和h 2 的公式如下:
h 1 (key) = key.GetHashCode()
h 2 (key) = 1 + (((h 1 (key) >> 5) + 1) % (buckets.length- 1))
由于使用了二度哈希,最终的h(key, i)的值有可能会大于容器,所以需要对h(key, i)进行模运算,最终计算的哈希地址为:
哈希地址 = h(key, i) % buckets.length
而且容器扩展也是有讲究的。
因为这些知识对刚接触的朋友不太好理解,所以没放到文章中去将。只要明白原理,这些都变得非常简单了。
另外附带微软的dictionary实现,有兴趣的可以去看看微软是怎么做的
http://referencesource.microsoft.com/#mscorlib (当然,你要搜索dictionary)
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

