爬虫与swift
分析
使用爬虫爬取网站page,并按事先的要求将需要的项目保存到数据库中,然后再使用python flask框架编写一个web 服务器讲数据库中的数据读出来,最后用swift编写一个应用将数据显示出来。我这里选区的所要爬取的网站是豆瓣电影网。
技术选用
爬虫:使用python的scrapy爬虫
数据库:使用mongoDB,存储网页只需要key和value形式进行存储就好了,所以在这里选择mongoDB这种NOSQL数据库进行存储
服务器:使用python的flask框架,用了你就知道几行代码就能完成很多事情,当然特别是flask可以根据需要组装空间,超轻量级。
实现:
-
scrapy爬虫实现
 上图是scrapy的文档结构,下面主要介绍几个文件。
上图是scrapy的文档结构,下面主要介绍几个文件。
a. items.py
from scrapy.item import Item, Field import scrapy class TopitmeItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() dataSrc = Field() dataId = Field() filmReview = Field() startCount = Field() 这里可以把items.py看作是mvc中的model,在items里我们定义了自己需要的模型。 b. pipelines.py
import pymongo from scrapy.conf import settings from scrapy.exceptions import DropItem from scrapy import log class MongoDBPipeline(object): def __init__(self): connection = pymongo.MongoClient( settings['MONGODB_SERVER'], settings['MONGODB_PORT'] ) db = connection[settings['MONGODB_DB']] self.collection = db[settings[‘MONGODB_COLLECTION’]] def process_item(self, item, spider): valid = True for data in item: if not data: valid = False raise DropItem("Missing {0}!".format(data)) if valid: self.collection.insert(dict(item)) log.msg("Beauty added to MongoDB database!", level=log.DEBUG, spider=spider) return item 俗称管道,这个文件主要用来把我们获取的item类型存入mongodb c. settings.py
BOT_NAME = 'topitme' SPIDER_MODULES = ['topitme.spiders'] NEWSPIDER_MODULE = 'topitme.spiders' BOT_NAME = 'topitme' ITEM_PIPELINES = ['topitme.pipelines.MongoDBPipeline',] MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "topitme" MONGODB_COLLECTION = "beauty" # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'topitme (+http://www.yourdomain.com)' 这里需要设置一些常量,例如mongodb的数据库名,数据库地址和数据库端口号等等 d. topitme_scrapy.py
from scrapy import Spider from scrapy.selector import Selector from topitme.items import TopitmeItem import sys reload(sys) sys.setdefaultencoding(‘utf8’)#设置默认编码格式 class topitmeSpider(Spider): name = "topitmeSpider" allowed_domin =["movie.douban.com"] start_urls = [ "http://movie.douban.com/review/latest/", ] def parse(self, response): results = Selector(response).xpath('//ul[@class="tlst clearfix"]') for result in results: item = TopitmeItem() # item['title'] = result.xpath('li[@class="ilst"]/a/@src').extract()[0] item['title'] = result.xpath('li[@class="ilst"]/a/@title').extract()[0].encode('utf-8') item['dataSrc'] = result.xpath('li[@class="ilst"]/a/img/@src').extract()[0] item['filmReview'] = result.xpath('li[@class="clst report-link"]/div[@class="review-short"]/span/text()').extract()[0].encode('utf-8') item['dataId'] = result.xpath('li[@class="clst report-link"]/div[@class="review-short"]/@id').extract()[0] item['dataId'] = result.xpath('li[@class="nlst"]/h3/a/@title').extract()[0] item['startCount'] = 0 yield item # ul[@class="tlst clearfix"]/li[3]/div[1] # //ul[@class="tlst clearfix"]/li[@class="ilst"]/a/img/@src 这个文件是爬虫程序的主要代码,首先我们定义了一个类名为topitmeSpider的类,继承自Spider类,然后这个类有3个基础的属性,name表示这个爬虫的名字,等一下我们在命令行状态启动爬虫的时候,爬虫的名字就是name规定的。 allowed_domin意思就是指在movie.douban.com这个域名爬东西。 start_urls是一个数组,里面用来保存需要爬的页面,目前我们只需要爬首页。所以只有一个地址。 然后def parse就是定义了一个parse方法(肯定是override的,我觉得父类里肯定有一个同名方法),然后在这里进行解析工作,这个方法有一个response参数,你可以把response想象成,scrapy这个框架在把start_urls里的页面下载了,然后response里全部都是html代码和css代码。这之中最主要的是涉及一个xpath的东西,XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。可以通过xpath定位到我们想要获取的元素。 - 服务器
使用python的flask框架实现
from flask import Flask, request import json from bson import json_util from bson.objectid import ObjectId import pymongo app = Flask(__name__) client = pymongo.MongoClient() db = client['topitme'] def toJson(data): return json.dumps(data, default=json_util.default) @app.route('/FilmReview', methods=['GET']) def findMovie(): if request.method == 'GET': json_results = [] for result in results: json_results.append(result) return toJson(json_results) if __name__ == '__main__': app.run(debug=True) 首先可以看到代码,client,db两个参量是为了取得数据库连接。 findMovie函数响应http request,然后返回数据库数据,以JSON形式返回 - swift
ios的实现就不详细介绍了,这里写这部分只是为了,验证结果。
运行:
- 起服务器:

- 起数据库:

- 运行爬虫:
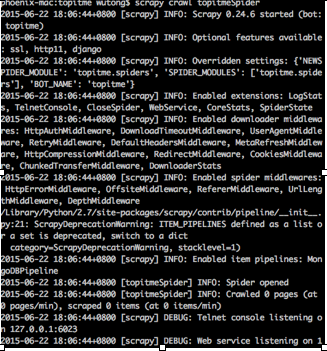
- 访问服务器: http://localhost:5000/FileReview 可以看到数据已经存储到数据库中了

- ios运行情况:
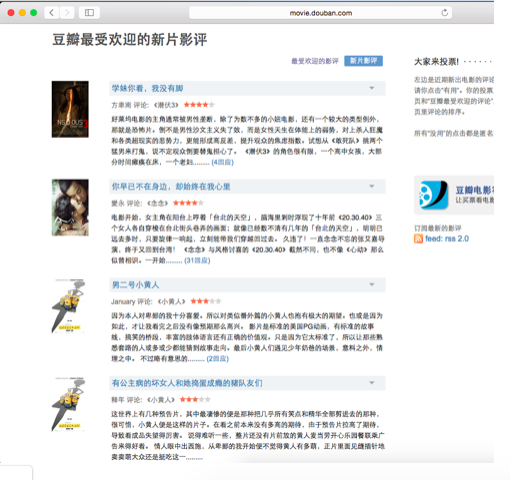
- 下面是原网站网页展示,可以看到所要的数据存储到数据库,并且正常显示出来
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

