推荐系统,第 1 部分: 方法和算法简介
查找推荐系统
在您每天使用的许多网站中都可找到推荐系统,包括以下知名的例子:
LinkedIn(面向业务的社交网络站点)推荐您可能知道的人员,您可能喜欢的工作,您想要关注的群组,或者您可能感兴趣的公司。LinkedIn 使用 Apache Hadoop 构建它专业的协作式过滤功能。
Amazon(流行的电子商务站点)使用基于内容的推荐。您选择一款要购买的商品后,Amazon 根据该原始商品来推荐其他用户已购买的商品(作为下一个可能购买的商品表格)。Amazon 为此行为申请了专利,称为 商品到商品协作式过滤 (item-to-item collaborative filtering) 。
Hulu(一个流视频网站)使用一个推荐引擎识别用户可能感兴趣的内容。它还(在线下)使用基于商品的协作式过滤和 Hadoop 来扩展对大量数据的处理。目前已公开提供 Hulu 的在线和离线 ItemCF 架构的 详细信息 。
Netflix(一个视频租赁和流式传输服务)是一个知名的例子。2006 年,Netflix 举办了一次竞赛以改进它的推荐系统 Cinematch。2009 年,3 个团队合力构建了一个包含 107 个推荐算法的套件,以得到一个预测结果。事实证明这个套件是改善预测准确性的关键所在,这个组合团队赢得了竞赛大奖。
其他整合了推荐引擎的站点包括 Facebook、Twitter、Google、MySpace、Last.fm、Del.icio.us、Pandora、Goodreads,以及您最喜爱的在线新闻站点。推荐引擎的使用正成为现代 Web 存在的一个标准元素。
推荐系统改变了没有活力的网站与其用户通信的方式。无需提供一种静态体验,让用户搜索并可能购买产品,推荐系统加强了交互,以提供内容更丰富的体验。推荐系统根据用户过去的购买和搜索历史,以及其他用户的行为,自主地为各个用户识别推荐内容。本文介绍推荐系统及其所实现的算法。在第 2 部分中,将介绍构建一个推荐功能的开源选项。
基本方法
大多数推荐系统都采用两种基本方法之一:协作式过滤或基于内容的过滤。当然也有其他的方法(比如混合方法)。
协作式过滤
协作式过滤 根据以前用户行为的模型来获得推荐内容。可通过单个用户的行为单独构造该模型,或者 — 更有效的方法是 — 根据其他拥有类似特征的用户的行为来构造该模型。考虑其他用户的行为时,协作式过滤使用群组知识并基于类似用户来形成推荐内容。在本质上,推荐内容基于多个用户的自动协作,并过滤出表现了类似偏好或行为的用户。
例如,假设您正在构建一个网站来推荐博客。通过使用许多订阅并阅读博客的用户的信息,您可根据这些用户的偏好将他们分组。例如,您可将阅读多篇相同博客的用户分组到一起。有了此信息,您可识别该群组阅读了哪些最流行的博客。然后 — 对于群组中的一个特定用户 — 您推荐他或她未阅读也未订阅的最流行博客。
在图 1 中的表中,一组博客构成了行内容,而列定义了用户。博客行和用户列相交的单元包含该博客的该用户所阅读的文章数量。通过根据用户的阅读习惯来为用户划分集群(比如使用一个 nearest-neighbor 算法),您可看到两个分别包含两个用户的集群。注意每个集群的成员的阅读习惯的相似性:Marc 和 Elise(他们都阅读了多篇关于 Linux® 和云计算的文章)形成 Cluster 1。Cluster 2 中包含 Megan 和 Jill,他们都阅读了多篇关于 Java™ 和敏捷性的文章。
图 1. 协作式过滤的简单示例
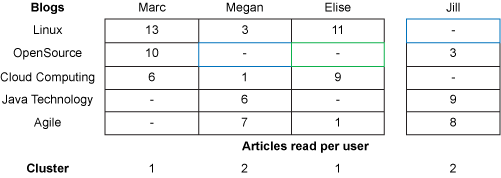
现在您可识别每个集群中的一些区别并进行有意义的推荐。在 Cluster 1 中,Marc 阅读了 10 篇开源博客文章,Elise 一篇都没读;Elise 阅读了 1 篇敏捷性博客,Marc 一篇都没读。然后在图 1中,针对 Elise 的一个推荐内容是开源博客。无法对 Marc 进行推荐,因为他和 Elise 在敏捷博客阅读方面的细微区别可能被过滤掉了。在 Cluster 2 中,Jill 阅读了 3 篇开源博客,而 Megan 一篇都没读;Megan 阅读了 11 篇 Linux 博客,而 Jill 一篇都没读。然后 Cluster 2 给出了两个推荐内容:为 Jill 推荐 Linux 博客和为 Megan 推荐开源博客。
查看这些关系的另一种方式是基于他们的相似性和区别,如图 2 中的维恩图所示。相似性(基于所用的特定算法)定义了如何将拥有类似兴趣的用户分组到一起。区别是可用于推荐内容的机会 — 例如通过一个流行度过滤器来应用。
图 2. 协作式过滤中使用的相似性和区别
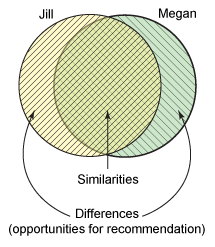
尽管图 2 是一种简化的结果(而且由于仅使用了两个示例的很少数据),但它是一种很方便的表示形式。
基于内容的过滤
基于内容的过滤 可根据用户的行为来构造推荐内容。例如,此方法可能使用历史浏览信息,比如用户阅读了哪些博客和这些博客的特征。如果用户经常阅读关于 Linux 的文章或可能在有关软件工程的博客中留下了评论,基于内容的过滤可使用此历史信息来识别和推荐类似的内容(有关 Linux 的文章或有关软件工程的其他博客)。可手动定义此内容,或者根据其他类似性方法来自动提取此内容。
返回到图 1,重点看看用户 Elise。如果您使用一个博客排名,指定阅读 Linux 文章的用户可能还喜欢阅读开源和云计算文章,您可轻松地进行推荐 — 根据他当前的阅读习惯 — Elise 阅读开源文章。此方法(如图 3 中所示)仅依赖于一个用户访问的内容,而不依赖于系统中其他用户的行为。
图 3. 基于内容的过滤中使用带排名的区别
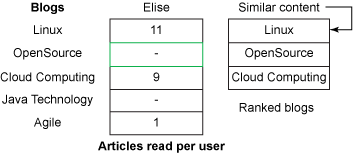
图 2中的维恩图在这里也适用:如果一端是用户 Elise,另一端是一组带排名的类似博客,那么会忽略相似性(因为 Elise 已阅读这些博客),而且带排名的区别是进行推荐的机会。
混合方法
混合 方法将协作式过滤和基于内容的过滤相结合,它可增加推荐系统的效率(和复杂性)。一个混合系统的简单示例可能是使用图 1和图 3中所示的方法。将基于内容的过滤和协作式过滤的结果合并在一起,就有可能实现更准确的推荐内容。混合方法也可用于解决从稀疏数据开始的协作式过滤问题 — 称为 冷启动 — 方法是支持先对基于内容的过滤结果分配权重,然后随着可用用户数据集的成熟而将该权重转变为协作式过滤。
回页首
推荐系统使用的算法
如赢得 Netflix 奖 的方法所演示的,有许多算法方法可用于推荐引擎。根据算法的设计宗旨是要解决什么问题还是数据中存在的关系,结果可能不同。许多算法来自机器学习领域,这是人工智能的一个子领域,可生成用于学习、预测和决策制定的算法。
皮尔逊相关
两个用户(和他们的属性,比如从一组博客中阅读哪些文章)之间的相似性可使用 皮尔逊相关 来准确计算。此算法度量两个变量(或用户)之间的线性依赖关系,以此作为其属性的函数。但它不会对整个用户群计算此度量结果。相反,必须根据更高级的类似性指标(比如阅读类似的博客)将人群过滤为 近邻 (neighborhoods) 。
皮尔逊相关(已广泛用于研究中)是一个用于协作式过滤的流行算法。
集群算法
集群算法 是一种无人监督的学习形式,可找到一组看似随机(或无关的)数据中的结构。一般而言,它们识别各项(比如博客读者)之间的相似性,计算他们在一个 特征空间 中与其他项目的距离。(一个特征空间中的特征可表示在一组博客中阅读的文章数量。)独立特征的数量定义了空间的维度。如果一些项目 “很靠近”,那么可将它们加入到一个集群中。
目前有许多集群算法。最简单的一个是 k -means,它将各个项目分区到 k 个集群中。最初,各项随机放置到集群中。然后,为每个集群计算一个 重心 (或 中心 )作为集群成员的函数。然后检查每一项与重心之间的距离。如果发现一项更靠近另一个集群,会将它移到该集群。每次检查所有项目的距离时都会重新计算重心。达到稳定状态后(也就是在一次迭代期间没有项目移动时),这组项目就已正确集群化,算法结束工作。
可能很难形象地表述对两个对象之间的距离进行计算。一种常见方法是将每一项视为一个多维矢量,使用欧几里德算法计算距离。
其他集群变体包括 Adaptive Resonance Theory (ART) 系列、Fuzzy C-means 和 Expectation-Maximization(概率集群)等。
其他算法
许多算法 — 以及这些算法的更多变体 — 可用于推荐引擎。一些已被人们成功使用的算法包括:
- Bayesian Belief Nets ,能够可视化为一个定向非循环图,其中的弧线表示变量之间关联的概率。
- Markov chains ,它采用一种与 Bayesian Belief Nets 类似的方法,但将推荐问题视为顺序优化,而不是简单的预测。
- Rocchio classification (使用 Vector Space Model 开发),它利用项目相关性的反馈来提高推荐的准确性。
回页首
推荐系统面临的挑战
Web 所带来的数据收集机会,使利用 “集体智慧”(和协作式过滤)变得更加简单。但大量可用的数据也使这一机会变得更加复杂。例如,尽管可以对一些用户的行为建模,但其他用户没有表现出典型行为。这些用户可能让推荐系统的结果失真并降低其效率。而且,用户可利用推荐系统来选择一个产品并放弃另一个产品 — 例如根据对一个产品的积极反馈和对竞争产品的消极反馈。一个好的推荐系统必须能管理这些问题。
大规模推荐系统中特有的一个问题是可伸缩性。传统算法比较适合较小的数据量,但在数据集增长时,传统算法可能难以处理。尽管这对于离线处理而言可能不是问题,但在实时场景中需要更加专业的方法。
最后,隐私保护考虑因素也是一大挑战。推荐算法可识别个人可能不知道的已有模式。一个最新的示例是,大型公司可根据购买习惯来计算怀孕预测分数。通过使用有针对性的广告,父亲会惊奇地发现他十几岁的女儿怀孕了。该公司的预测程序很准确,它可根据一位准妈妈购买的产品来预测她的预产期。
回页首
结束语
推荐引擎现在为大多数流行的社交和商业网站提供着支持。它们为站点所有者及其用户提供了巨大的价值,但也有一些缺点。本文探索了推荐系统背后的一些理念和支撑它们的算法。本系列的第 2 部分 介绍了在构建推荐功能时可用的开源选项。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

