Oracle专家谈MySQL Cluster如何支持200M的QPS
Andrew Morgan 是Oracle MySQL首席产品经理。 近日,他 撰文 介绍了MySQL Cluster如何支持200M的QPS。
MySQL Cluster简介
MySQL Cluster 是一个实时可扩展且符合ACID的事务型内存数据库。该数据库有高达99.999%的可用性和低廉的开源软件总拥有成本。在设计方面,它采用了一种分布式、多主节点的架构,消除了单点故障,能够在商用硬件上横向扩展,并借助“自动分片(auto-sharding)”功能为通过SQL和NoSQL接口访问数据的读/写密集型工作负载提供服务。
最初,MySQL Cluster被设计成一个嵌入式的电信数据库,用于网内应用程序,需要具备运营商级的可用性和实时性能。之后,其功能随着新功能集的增加迅速增强,其应用领域随之也扩展到了本地或云上的Web、移动和企业应用程序,包括:大规模OLTP、实时分析、电子商务(库存管理、购物车、支付处理、订单追踪)、在线游戏、金融交易(欺诈检测)、移动与微支付、会话管理&缓存、流式推送、分析及推荐、内容管理与交付、通信与在线感知服务、订阅者/用户信息管理与权益等。
MySQL Cluster体系结构
在MySQL Cluster内部,总共有三种类型的节点为应用程序提供服务。下面是一张MySQL Cluster体系结构简图,其中包含6个节点组,共12个“数据节点(Data Node)”:

数据节点是MySQL Cluster的主要节点。它们提供如下功能:内存内及基于磁盘的数据存储与管理、表的自动“分片(sharding)”及按用户定义分区、数据节点间数据同步复制、事务与数据检索、自动故障恢复、自我修复(故障解决后自动重新同步)。
表会自动跨数据节点分区,每个数据节点都是一个可以接受写操作的主节点。这使得写密集型工作负载很容易在节点之间分配,而且对于应用程序而言,这个过程是透明的。
MySQL Cluster采用了一种无资源共享的体系结构(比如不使用共享磁盘)存储和分发数据,并同步生成至少一个数据副本,如果某个数据节点出现故障,则总是有另一个数据节点存储了同样的信息, 使得请求和事务可以继续而不被中断。任何在数据节点故障期间短暂中断(亚秒级)的事务都可以回滚并重新执行。
MySQL Cluster允许用户选择如何存储数据:全部在内存中或者部分在磁盘上(仅限于未索引数据)。内存内存储对于经常变化的数据(活动工作集)而言尤其有用。存储在内存中的数据会定期地(本地检查点)写入本地磁盘,并在所有数据节点之间协调,这样,MySQL Cluster可以从系统完全失效(比如停电)的情况下恢复过来。基于磁盘的存储可以用于存储性能要求不那么严格的数据,其数据集大于可用内存。与其它大多数数据库服务器一样,为了提高性能,MySQL Cluster使用页缓存将经常使用的、基于磁盘存储的数据缓存在数据节点的内存中。
应用节点提供从应用逻辑到数据节点的连接。应用程序可以使用SQL访问数据库,通过一台或多个MySQL服务器对存储在MySQL Cluster中的数据执行SQL接口的功能。当访问MySQL服务器时,可以使用任何一种标准的 MySQL连接器 ,这使用户有许多种访问技术可选择。NDB API是其中一个可选的方案。这是一个基于C++的高性能接口,可以提供额外控制、更好的实时行为及更高的吞吐能力。NDB API还提供了一个层,使NoSQL接口可以绕过SQL层直接访问MySQL Cluster,降低了延迟,提高了开发灵活性。现有接口包括Java、JPA、Memcached、JavaScript与Node.js、HTTP/REST(借助Apache Module)。所有应用节点都可以访问所有数据节点的数据,所以,它们即使出现故障也不会导致服务中断,因为应用程序只要使用剩下的节点就可以了。
管理节点负责向MySQL Cluster中的所有节点发布集群配置信息以及节点管理。管理节点在启动、向集群加入节点及系统重新配置时使用。管理节点关闭和重启不会影响数据节点和应用节点的运行。在默认情况下,在遇到导致“集群分裂(split-brain)”或 网络分区 的网络故障时,管理节点还提供仲裁服务。
通过透明分片实现可扩展性

任何表的行都可以透明地分成多个分区/片段。对于每一个片段,都会有一个单独的数据节点保存它所有的数据,并处理所有针对那些数据的读写操作。每个数据节点还有一个伙伴节点,它们共同组成了一个节点组;伙伴节点存储了那个片段的第二个副本以及一个它自己原有的片段。MySQL Cluster使用同步两段提交协议确保事务提交的变化同时存储到两个数据节点。
MySQL Cluster默认使用表的主键作为“分片键(shard key)”,并对分片键执行MD5散列,从而选择数据应该存储的片段/分区。如果一个事务或查询需要访问多个数据节点的数据,那么其中一个数据节点将承担事务协调器的角色,并将工作委派给其它所需的数据节点;结果会在提供给应用程序前合并。需要注意的是,事务或查询可以连接来自多个分片和多个表的数据,这与传统的、实现了分片机制的NoSQL数据存储相比是一个巨大的优势。
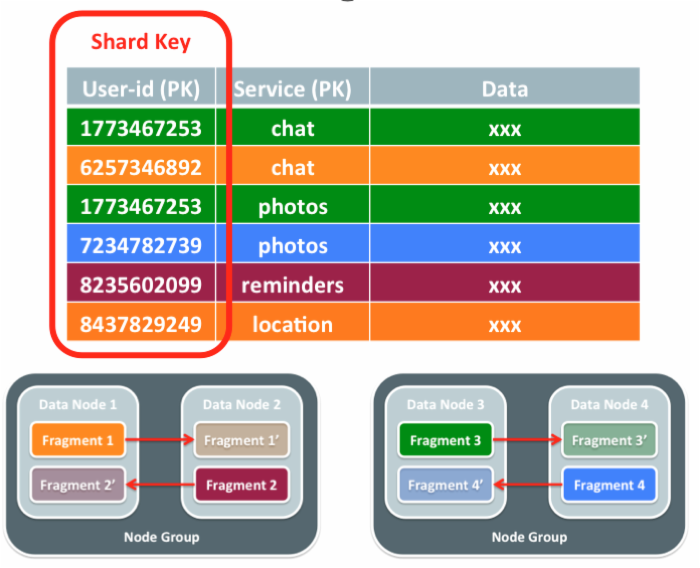
当单个节点就可以满足高强度查询/事务的数据操作需求时,就实现了最理想的(线性)扩展(因为这减少了数据节点间消息传递的网络延迟)。要做到这一点,应用程序应该清楚地知道数据分布——这实际上就是说定义模式的人可以指定用作分片键的列。比如,上图中的表使用了由user-id和服务名组合而成的主键;如果只使用user-id作为分片键,那么表中特定用户的所有行将会总是存储在同一个片段中。更为强大之处在于,如果其它表中也使用了同样的user-id列,并将其设定为分片键,那么所有表中特定用户的数据都会存储在同一个片段中,那个用户的查询/事务就可以由单个数据节点处理。
利用NoSQL API最大限度地提高数据访问速度
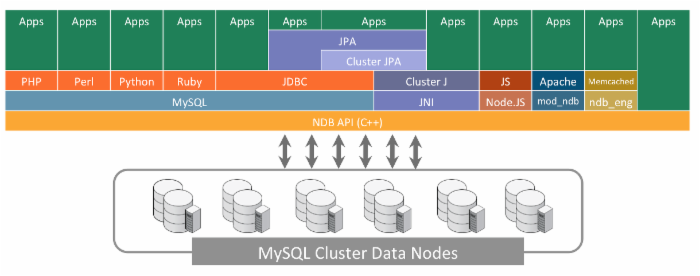
MySQL Cluster提供了许多种数据访问方式;最常用的方法是SQL,但从下图可以看出,还有许多原生API可供应用程序从数据库直接读/写数据,避免了向SQL转换并传递给MySQL服务器的低效和开发复杂度。目前,MySQL Cluster提供了面向C++、Java、JPA、JavaScript/Node.js、HTTP及Memcached协议的API。
基准测试:每秒2亿次查询
根据设计,MySQL Cluster用于处理以下两种工作负载:
- OLTP(在线事务处理) :内存优化型表可以提供次毫秒级的低延迟以及极高水平的OLTP工作负载并发能力,并且仍然可以提供良好的稳定性;此外,它们也能够用于基于磁盘存储的表。
- 即时搜索 :MySQL Cluster提高了执行表扫描时可以使用的并发数,极大地提高了未索引列的搜索速度。
话虽如此,MySQL Cluster旨在处理OLTP工作负载方面达到最佳,特别是在以并发方式发送大量查询/事务请求的情况下。为此,他们使用 flexAsynch 基准测试,测量更多数据节点加入集群后NoSQL访问性能的提升。
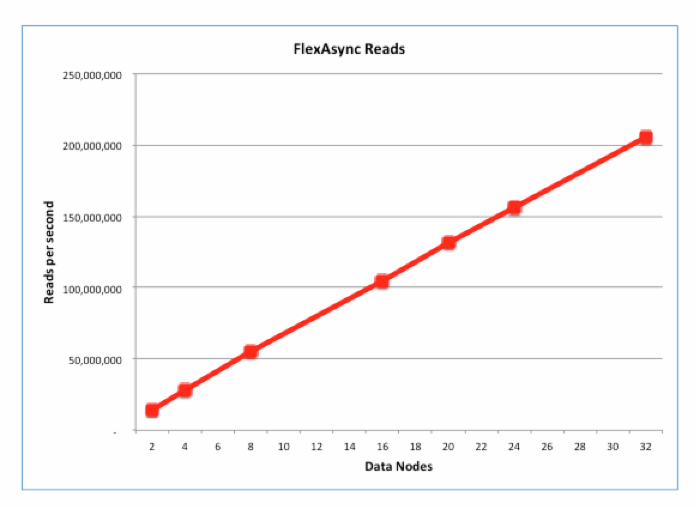
在该基准测试中,每个数据节点运行在一个专用的56线程Intel E5-2697 v3(Haswell)机器上。上图显示了在数据节点从2增加到32(注意:MySQL Cluster目前最多支持48个数据节点)的过程中吞吐量的变化。从中可以看出,吞吐量呈线性增长,在32个数据节点时,达到了 每秒2亿次NoSQL查询 。
读者可以登录 MySQL Cluster基准测试页面 ,查看关于这次测试的最新结果及更详细的描述。
每秒2亿次查询的基准测试是在MySQL Cluster 7.4(最新的正式版本)上得出的,关于该版本的更多信息请查看 这里 。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群  )。
)。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

