SAP HANA数据存储:OLTP与OLAP存储方法对比
SAPHANA平台有各种各样的应用场景,这也意味着客户的实施方法有许多种选择,关键是如何挑选最适合他们需求的实施方案。
在《Implementing SAP HANA》这本书中,介绍了SAP平台在现实场景中的运作原理,并给出了实施建议和成功案例供参考。本系列文章节选自《Implementing SAP HANA》,介绍了行存储和列存储的各自特点,以及SAP HANA的数据存储方式如何提升空间压缩和性能。
在第二篇文章中,我们主要介绍了OLTP和OLAP所用到的不同数据存储方法。
OLTP存储方法
OLTP或者说关系型数据库本质上存储的是规范形式的数据。规范的数据可以检索冗余,这种存储模式可以优化宝贵的磁盘空间,这样就可以尽可能快地把数据写到磁盘。如果没有最小化数据存储这个技术考虑,那么关系型数据库自然会需要大量空间来存储这些冗余数据。如下图,展示了一个常见的规范关系型数据库表结构关系图,这种设计是为了减少冗余数据存储量的。
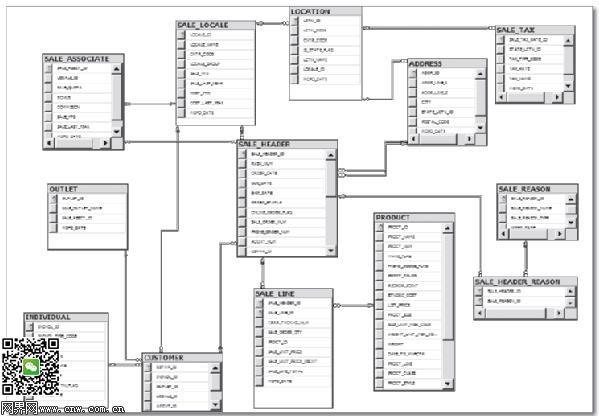
规范的关系数据库表结构
数据规范化处理成多个表,这样重复的数据就可以去除,只存储一次,同时持有指向重复数据的索引。例如,在上图中,“SALE_HEADER”记录规范存储到它们自己的表中,而不是把数据都存储到“SALE_HEADER”表中。这种概念是OLTP系统的基本处理,也是OLTP系统设计是考虑的最基本最简单的原则。
传统关系型数据库系统这样插入和存储数据的设计完全没有什么错。事实上,从这个目的来考虑,它的设计非常棒。(所有存储数据的方式都按这种方法设计是有原因的)然而,这种系统还有一个基本的问题:查询数据。
从OLTP系统中查询提取数据需要多次连接和联合查询各种关系表。在这种数据库设计中处理这个工作代价是比较昂贵的。通常,这些系统中的统计功能肯定是滞后的。这是一样的问题,都是因为联合查询性能缓慢和天生的速度障碍,因而大家发明了许多技术来解决这个问题。像OLAP这类技术思想就是专门为了解决这个问题。
OLAP存储方法
OLAP数据存储方法也是为解决如前所述访问磁盘获取数据缓慢和传统关系型数据库存储数据的方式而做的设计。像OLAP这种数据存储技术在物理上是以不同的方式存储数据,因为在磁盘层面遍历关系型数据库事实上并不是读取或提取数据的最快速方案。下图展示了在OLAP数据库中可替代的数据存储方式,通常用星型结构(因其关系型表结构图样得名)。
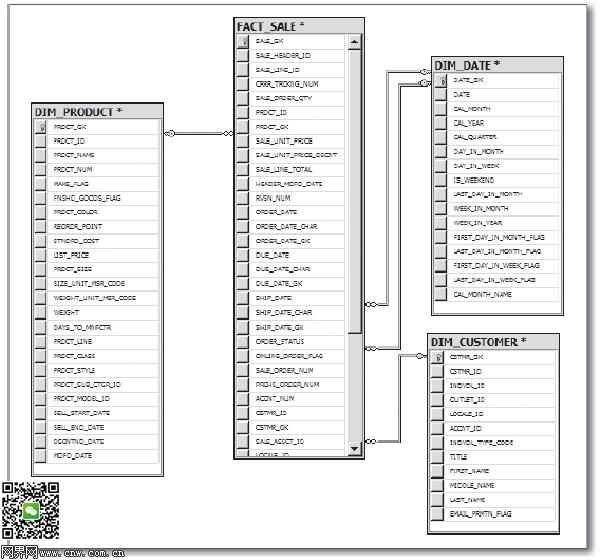
OLAP数据库中的数据存储。
在OLAP数据库中,数据被定义为事实和维度这样的概念。事实和维护也是标准的表,但是他们的名称暗示了他们存储的内容。事实表是星型结构或者维度数据模型的核心。例如,在上图中“FACT_SALE”表就是事实表。事实表存储的都是度量或者值,这些数据将被用作度量或描述业务概念事实的指标。事实表还包含指向日期维度表的外键,这样可以实现复杂日期度量。事实表用不同的间隔尺度安排,它可以有较高粒度和聚合级别,例如按日历周或者产品线聚合度量。或者事实表也可以使用最低级的粒度:来自来源系统或者组合来源系统的事务基线。事实表还包含有外键,可以利用维度表的主键找回到维度表。事实是一对多中“多”的关系。
在上图中前缀为“DIM_”的辅助表都是维度表。
维度表与事实表多少有点相反的感觉,因为维度包含度量描述,以附文的形式描述数据集通过给数据加标签用于分析,维度表也常用于快速查询或者过滤数据。在图3.2中,“DIM_CUSTOMER”表提供了客户数据或属性的明细信息,可以用于从客户数据的角度来过滤和查询销量。“DIM_PRODUCT”也是类似情况。
这是颇具戏剧性的解决方案,因为必须创建完全不同的表结构。如果上图中的建模任务还不够,那么就要增加另外的复杂性:出于必要(+微信关注网络世界),创建基于批量处理的过程。
基于批量处理的过程需要从OLTP规范数据结构中加载和转换数据,然后导入到非规范的OLAP结构用语快速查询。批过程通常称为抽取、转换和加载(ETL)。ETL过程把数据物理上进行了转换,符合这种OLAP存储方法的思路。
典型的ETL处理工作流
1、数据从一个或者多个数据源系统抽取出来以后,会被载入临时数据库,在这里进行多种转换。
2、临时数据库是去除数据源系统印记的关键一层,是向业务概念标准化的过程。
3、接下来数据要载入数据仓库表,解析为OLAP结构,同时支持高性能读取,适应分析方法和临时查询数据访问的灵活性要求。
SAP针对ETL数据集成的解决方案是SAP DataServices。SAPData Services是一套全功能ERL和数据质量解决方案,可以把非常复杂的处理构建的相对简单。SAP Data Services解决方案可以用于抽取和转换数据,利用许多强大的内建函数处理复杂转换操作。
因为它是把非SAP数据转入SAP HANA的主要手段,所以SAP Data Services在为实现SAPHANA中性能最大化而建立数据模型和数据存储方面有着举足轻重的作用。
像上图展示的那样的OLAP数据结构是临时查询分析工具(例如:SAPBusinessObjects BI)关注和主要使用的方式。如果数据中存在层次结构或者你使用日期维度(在前面的例子中指的是“DIM_DATE”)不只做搜索和排序,还要毫不费力地提供运行计算或者更复杂的基于日期的聚合,那么OLAP或者星型结构使得该工具可以非常灵活地钻取数据,当然,这种数据存储和系统设计缓解了平台性能缓慢的压力,增加了分析的优势特性。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

